
Enterprise networks are like air. When they’re running smoothly, it’s easy to take them for granted, as business users and customers are able to go about their normal activities. But when customer service reps are suddenly cut off from their ticketing system, or family movie night turns into a game of “Is it my router, or the network?”, everyone notices. This is why network resilience is critical.
But, what exactly does resilience mean today? Let’s find out by looking at some recent real-world examples, the history of network architectures, and why network resilience doesn’t mean what it did 20 years ago.
Why does network resilience matter?
There’s no shortage of real-world examples showing why network resilience matters. The takeaway is that network resilience is directly tied to business, which means that it impacts revenue, costs, and risks. Here is a brief list of resilience-related incidents that occurred in 2023 alone:
- FAA (Federal Aviation Administration) – An overworked contractor unintentionally deleted files, which delayed flights nationwide for an entire day.
- Southwest Airlines – A firewall configuration change caused 16,000 flight cancellations and cost the company about $1 billion.
- MOVEit FTP exploit – Thousands of global organizations fell victim to a MOVEit vulnerability, which allowed attackers to steal personal data for millions.
- MGM Resorts – A human exploit and lack of recovery systems let an attack persist for weeks, causing millions in losses per day.
- Ragnar Locker attacks – Several large organizations were locked out of IT systems for days, which slowed or halted customer operations worldwide.
What does network resilience mean?
Based on the examples above, it might seem that network resilience could mean different things. It might mean having backups of golden configs that you could easily restore in case of a mistake. It might mean beefing up your security and/or replacing outdated systems. It might mean having recovery processes in place.
So, which is it?
The answer is, it’s all of these and more.
Donald Firesmith (Carnegie Mellon) defines resilience this way: “A system is resilient if it continues to carry out its mission in the face of adversity (i.e., if it provides required capabilities despite excessive stresses that can cause disruptions).”
Network resilience means having a network that continues to serve its essential functions despite adversity. Adversity can stem from human error, system outages, cyberattacks, and even natural disasters that threaten to degrade or completely halt normal network operations. Achieving network resilience requires the ability to quickly address issues ranging from device failures and misconfigurations, to full-blown ISP outages and ransomware attacks.
The problem is, this is now much more difficult than it used to be.
How did network resilience become so complicated?
Twenty years ago, IT teams managed a centralized architecture. The data center was able to serve end-users and customers with the minimal services they needed. Being “constantly connected” wasn’t a concern for most people. For the business, achieving resilience was as simple as going on-site or remoting-in via serial console to fix issues at the data center.
Then in the mid-2000s, the advent of the cloud changed everything. Infrastructure, data, and computing became decentralized into a distributed mix of on-prem and cloud solutions. Users could connect from anywhere, and on-demand services allowed people to be plugged in around-the-clock. Services for work, school, and entertainment could be delivered anytime, no matter where users were.
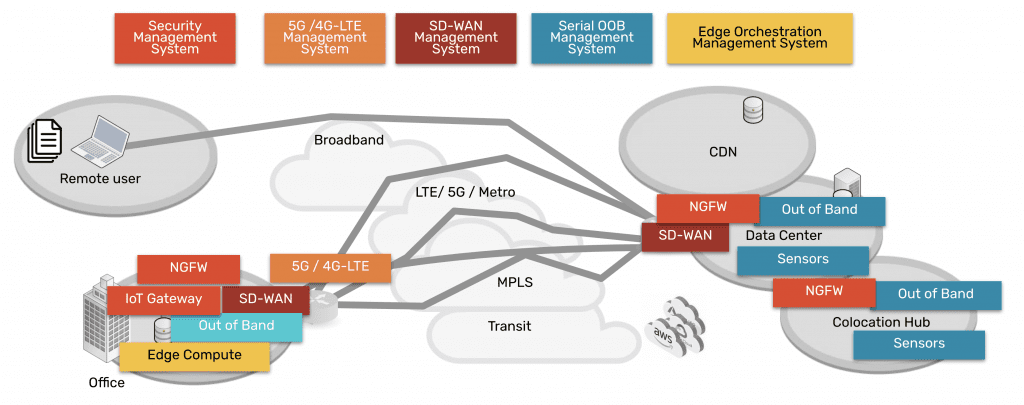
Behind the scenes, this explosion of architecture created three problems for achieving network resilience, which a simple serial could no longer fix:
Too Much Work
Infrastructure, data, and computing are widely distributed. Systems inevitably break and require work, but teams don’t have the staff to keep up.
Too Much Complexity
Pairing cloud and box-based stacks creates complex networks. Teams leave systems outdated, because they don’t want to break this delicate architecture.
Too Much Risk
Unpatched, outdated systems are prime targets for packaged attacks that move at machine speed. Defense requires recovery tools that teams don’t have.
Enabling businesses to be resilient in the modern age requires an approach that’s different than simply deploying a serial console for remote troubleshooting. Gen 1 and 2 serial consoles, which have dominated the market for 20 years, were designed to solve basic issues by offering limited remote access and some automation. The problem is, these still leave teams lacking the confidence to answer questions like:
- “How can we guarantee access to fix stuff that breaks, without rolling trucks?”
- “Can we automate change management, without fear of breaking the network?”
- “Attacks are inevitable — How do we stop hackers from cutting off our access?”
Hyperscalers, Internet Service Providers, Big Tech, and even the military have a resilience model that they’ve proven over the last decade. Their approach involves fully isolating command and control from data and user environments. This allows them to not only gain low-level remote access to maintain and fix systems, but also to “defend the hill” and maintain control if systems are compromised or destroyed.
This approach uses something called Isolated Management Infrastructure (IMI).
Isolated Management Infrastructure is the best practice for network resilience
Isolated Management Infrastructure is the practice of creating a management network that is completely separate from the production network. Most IT teams are familiar with out-of-band management as this network; IMI, however, provides many capabilities that can’t be hosted on a traditional serial console or OOB network. And with increasing vulnerabilities, CISA issued a binding directive specifically calling for organizations to implement IMI.
Isolated Management Infrastructure using Gen 3 serial consoles, like ZPE Systems’ Nodegrid devices, provides more than simple remote access and automation. Similar to a proper out-of-band network, IMI is completely isolated from production assets. This means there are no dependencies on production devices or connections, and management interfaces are not exposed to the internet or production gear. In the event of an outage or attack, teams retain management access, and this is just the beginning of the benefits of having IMI.
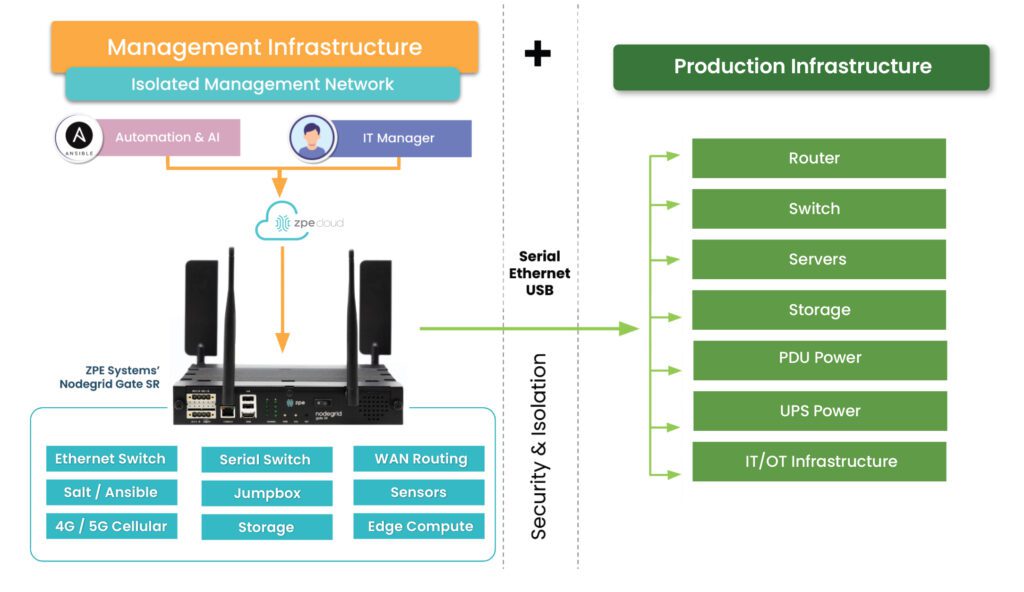
IMI includes more than nine functions that are required for teams to fully service their production assets. These include:
- Low-level access to all management interfaces, including serial, Ethernet, USB, IPMI, and others, to guarantee remote access to the entire environment
- Open, edge-native automation to ensure services can continue operating in the event of outages or change errors
- Computing, storage, and jumpbox capabilities that can natively host the apps and tools to deploy an IRE, to ensure fast, effective recovery from attacks
Get the guide to build IMI
ZPE Systems has worked alongside Big Tech to fulfill their requirements for IMI. In doing so, we created the Network Automation blueprint as a technical guide to help any organization build their own Isolated Management Infrastructure. Download the blueprint now to get started.