
On July 19, 2024, CrowdStrike, a leading cybersecurity firm renowned for its advanced endpoint protection and threat intelligence solutions, experienced a significant outage that disrupted operations for many of its clients. This outage, triggered by a software upgrade, resulted in crashes for Windows PCs, creating a wave of operational challenges for banks, airports, enterprises, and organizations worldwide. This blog post explores what transpired during this incident, what caused the outage, and the broader implications for the cybersecurity industry.
What happened?
The incident began on the morning of July 19, 2024, when numerous CrowdStrike customers started reporting issues with their Windows PCs. Users experienced the BSOD (blue screen of death), which is when Windows crashes and renders devices unusable. As the day went on, it became evident that the problem was widespread and directly linked to a recent software upgrade deployed by CrowdStrike.
Timeline of Events
- Initial Reports: Early in the day, airports, hospitals, and critical infrastructure operators began experiencing unexplained crashes on their Windows PCs. The issue was quickly reported to CrowdStrike’s support team.
- Incident Acknowledgement: CrowdStrike acknowledged the issue via their social media channels and direct communications with affected clients, confirming that they were investigating the cause of the crashes.
- Root Cause Analysis: CrowdStrike’s engineering team worked diligently to identify the root cause of the problem. They soon determined that a software upgrade released the previous night was responsible for the crashes.
- Mitigation Efforts: Upon isolating the faulty software update, CrowdStrike issued guidance on how to roll back the update and provided patches to fix the issue.
What caused the CrowdStrike outage?
The root cause of the outage was a software upgrade intended to enhance the functionality and security of CrowdStrike’s Falcon sensor endpoint protection platform. However, this upgrade contained a bug that conflicted with certain configurations of Windows PCs, leading to system crashes. Several factors contributed to the incident:
- Insufficient Testing: The software update did not undergo adequate testing across all possible configurations of Windows PCs. This oversight meant that the bug was not detected before the update was deployed to customers.
- Complex Interdependencies: The incident highlights the complex interdependencies between software components and operating systems. Even minor changes can have unforeseen impacts on system stability.
- Rapid Deployment: In the cybersecurity industry, quick responses to emerging threats are crucial. However, the pressure to deploy updates rapidly can sometimes lead to insufficient testing and quality assurance processes.
We need to remember one important fact: whether software is written by humans or AI, there will be mistakes in coding and testing. When an issue slips through the cracks, the customer lab is the last resort to catch it. Usually, this can be done with a controlled rollout, where the IT team first upgrades their lab equipment, performs further testing, puts in place a rollback plan, and pushes the update to a less critical site. But in a cloud-connected SaaS world, the customer is no longer in control. That’s why they sign waivers stating that if such an incident occurs, the company that caused the problem is not liable. Experts are saying the only way to address this challenge is to have an infrastructure that’s designed, deployed, and operated for resilience. We discuss this architecture further down in this article.
How to recover from the CrowdStrike outage
CrowdStrike gives two options for recovering:
- Option 1: Reboot in Safe Mode – Reboot the affected device in Safe Mode, locate and delete the file “C-00000291*.sys”, and then restart the device.
- Option 2: Re-image – Download and configure the recovery utility to create a new Windows image, add this image to a USB drive, and then insert this USB drive into the target device. The utility will automatically find and delete the file that’s causing the crash.
The biggest obstacle that is costing organizations a lot of time and money is that with either of these recovery methods, IT staff need to be physically present to work on each affected device. They need to go one by one manually remediating via Safe Mode or physically inserting the USB drive. What makes this more difficult is that many organizations use physical and software/management security controls to limit access. Locked device cabinets slow down physical access to devices, and things like role-based access policies and disk encryption can make Safe Mode unusable. Because this outage is affecting more than 8.5 million computers, this kind of work won’t scale efficiently. That’s why organizations are turning to Isolated Management Infrastructure (IMI) and the Isolated Recovery Environment (IRE).
How IMI and IRE help you recover faster
IMI is a dedicated control plane network that’s meant for administration and recovery of IT systems, including Windows PCs affected by the CrowdStrike outage. It uses the concept of out-of-band management, where you deploy a management device that is connected to dedicated management ports of your IT infrastructure (e.g., serial ports, IPMI ports, and other ethernet management ports). IMI also allows you to deploy recovery services for your digital estate that is immutable and near-line when recovery needs to take place.
IMI does not rely at all on the production assets, as it has its own dedicated remote access via WAN links like 4G/5G, and can contain and encrypt recovery keys and tools with zero trust.
IMI gives teams remote, low-level access to devices so they can recover their systems remotely without the need to visit sites. Organizations that employ IMI are able to revert back to a golden image through automation, or deploy bootable tools to all the computers at the site to rescue them without data loss.
The dedicated out-of-band access to serial/IPMI and management ports gives automation software the same abilities as if a physical crash cart was pulled up to the servers. ZPE Systems’ Nodegrid (now a brand of Legrand) enables this architecture as explained next. Using Nodegrid and ZPE Cloud, teams can use either option to recover from the CrowdStrike outage:
- Option 1: Reboot in Pre-Execution Environment Software – Nodegrid gives low-level network access to connected Windows as if teams were sitting directly in front of the affected device. This means they can remote-in, reboot to a network image, remote into the booted image, delete the faulty file, and restart the system.
- Option 2: Re-image – ZPE Cloud serves as a file repository and orchestration engine. Teams can upload their working Windows image, and then automatically push this across their global fleet of affected devices. This option speeds up recovery times exponentially.
- Option 3: – Run Windows Deployment server on the IMI device at the location and re-image servers and workstations if a good backup of the data has been located. This backup can be made available through the IMI after the initial image has been deployed. The IMI can provide dedicated secure access to the InTune services in your M365 cloud, and the backups do not have to transit the entire internet for all workstations at the time, speeding up recovery many times over.
All of these options can be performed at scale or even automated. Server recovery with large backups, although it may take a couple of hours, can be delivered locally and tracked for performance and consistency.
But what about the risk of making mistakes when you have to repeat these tasks? Won’t this cause more damage and data loss?
Any team can make a mistake repeating these recovery tasks over a large footprint, and cause further damage or loss of data, slowing the recovery further. Automated recovery through the IMI addresses this, and can provide reliable recording and reporting to ensure that the restoration is complete and trusted.
What does IMI look like?
Here’s a simplified view of Isolated Management Infrastructure. You can see that ZPE’s Nodegrid device is needed, which sits beside production infrastructure and provides the platform for hosting all the tools necessary for fast recovery.
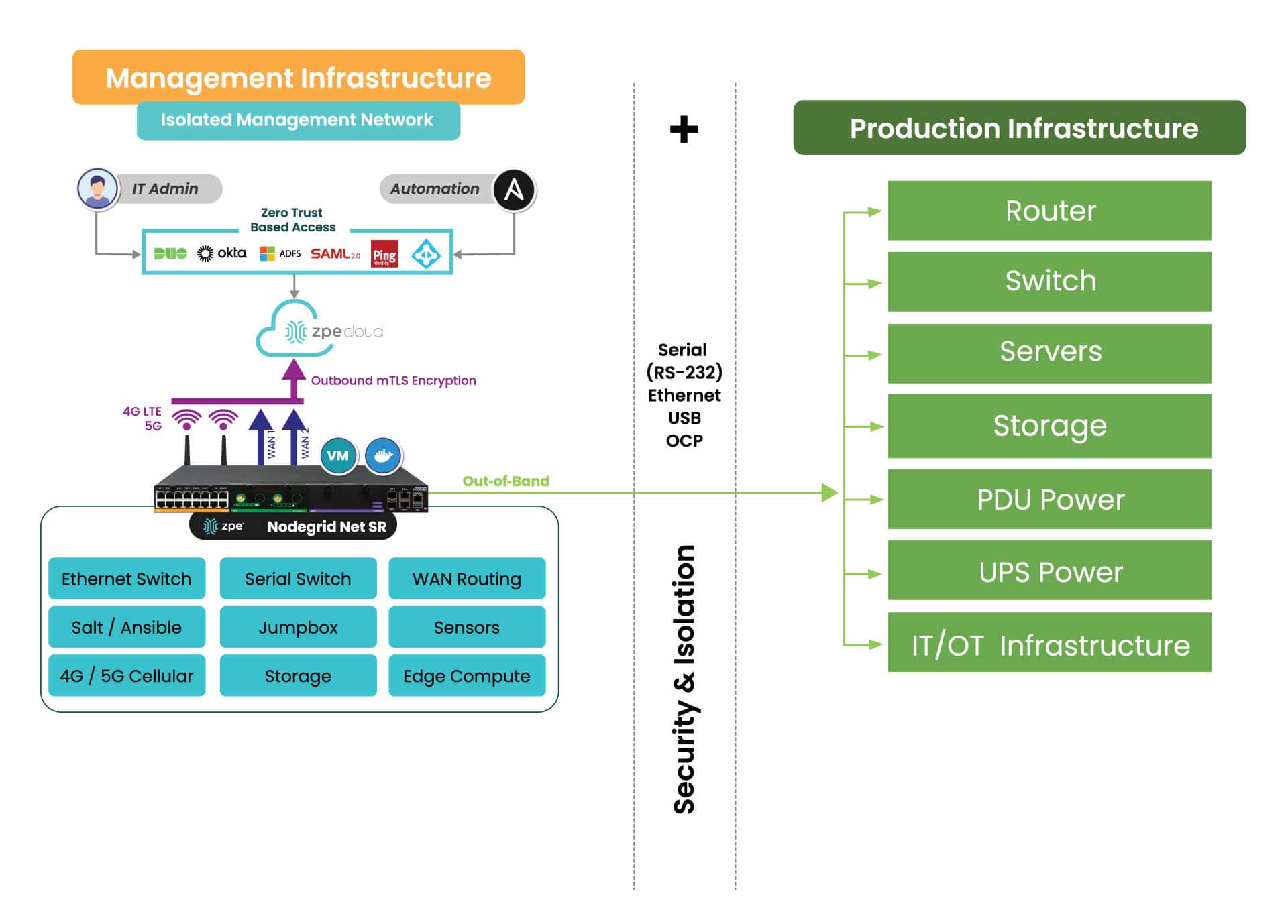
What you need to deploy IMI for recovery:
- Out-of-band appliance with serial, USB, ethernet interfaces (e.g., ZPE’s Nodegrid Net SR)
- Switchable PDU: Legrand Server Tech or Raritan PDU
- Windows PXE Boot image
Here’s the order of operations for a faster CrowdStrike outage recovery:
- Option 1 – Recover
-
- IMI deployed with a ZPE Nodegrid device that will start Pre-Execution Environment (PXE) which are Windows boot images that the Nodegrid will push to the computers when they boot up
- Send recovery keys from Intune to IMI remote storage over ZPE Cloud’s zero trust platform easily available in cloud or air-gapped through Nodegrid Manager
- Enable PXE service (automated across entire enterprise) and define the PXE recovery image
- Use serial or IP control of power to the computers, or if possible Intel vPro or IPMI capable machines, to reboot all machines
- All machines will boot and check in to a control tower for PXE, or be made available to remote into using stored passwords on the PXE environment, Windows AD, or other Privileged Access Management (PAM)
- Delete Files
- Reboot
- Option 2 – Lean re-image
-
- IMI deployed with a Windows Pre-Execution boot image running PXE service
- Enable access to cloud and Azure Intune to the IMI remote storage for the local image for the PC
- Enable PXE service (automated across entire enterprise) and define the PXE recovery image
- Use serial or IP control of power to the computers, or if possible, Intel vPro or IPMI capable machines, to reboot all machines
- Machines will boot and check in to Intune either through the IMI or through normal Internet access and finish imaging
- Once the machine completes the InTune tasks, InTune will signal backups to come down to the machines. If these backups are offsite, they can be staged on the IMI through backup software running on a virtual machine located on the IMI appliance to speed up recovery and not impede the Internet connection at the remote site
- Pre-stage backups onto local storage, push recovery from the virtual machine on the IMI
- Option 3 – Windows controlled re-image
-
- Windows Deployment Server (WDS) installed as a virtual machine running on the IMI appliance (offline to prevent issues or online but under a slowed deployment cycle in case there was an issue)
- Send recovery keys from Intune to IMI remote storage over a zero trust interface in cloud or air-gapped
- Use serial or IP control of power to the computers, or if possible, Intel vPro or IPMI capable machines, to reboot all machines
- Machines will boot and check in to the WDS for re-imaging
- Machines will boot and check in to Intune either through the IMI or through normal Internet access and finish imaging
- Once the machine completes the InTune tasks, InTune will signal backups to come down to the machines. If these backups are offsite, they can be staged on the IMI through backup software running on a virtual machine located on the IMI appliance to speed up recovery and not impede the Internet connection at the remote site
- Pre-stage backups onto local storage, push recovery from the virtual machine on the IMI
Deploy IMI to avoid the next outage
Get in touch for help choosing the right size IMI deployment for your organization. Nodegrid and ZPE Cloud are the drop-in solution to recovering from outages, with plenty of device options to fit any budget and environment size. Contact ZPE Sales now or download the blueprint to help you begin implementing IMI.