
AI is quickly becoming core to business-critical ops. It’s making manufacturing safer and more efficient, optimizing retail inventory management, and improving healthcare patient outcomes. But there’s a big question for those operating AI infrastructure: How can you make sure your systems stay online even when things go wrong?
AI system reliability is critical because it’s not just about building or using AI – it’s about making sure it’s available through outages, cyberattacks, and any other disruptions. To achieve this, organizations need to support their AI systems with a robust underlying infrastructure that enables secure remote network management.
The High Cost of Unreliable AI
When AI systems go down, customers and business users immediately feel the impact. Whether it’s a failed inference service, a frozen GPU node, or a misconfigured update that crashes an edge device, downtime results in:
- Missed business opportunities
- Poor customer experiences
- Safety and compliance risks
- Unrecoverable data losses
So why can’t admins just remote-in to fix the problem? Because traditional network infrastructure setups use a shared management plane. This means that management access depends on the same network as production AI workloads. When your management tools rely on the production network, you lose access exactly when you need it most – during outages, misconfigurations, or cyber incidents. It’s like if you were free-falling and your reserve parachute relied on your main parachute.
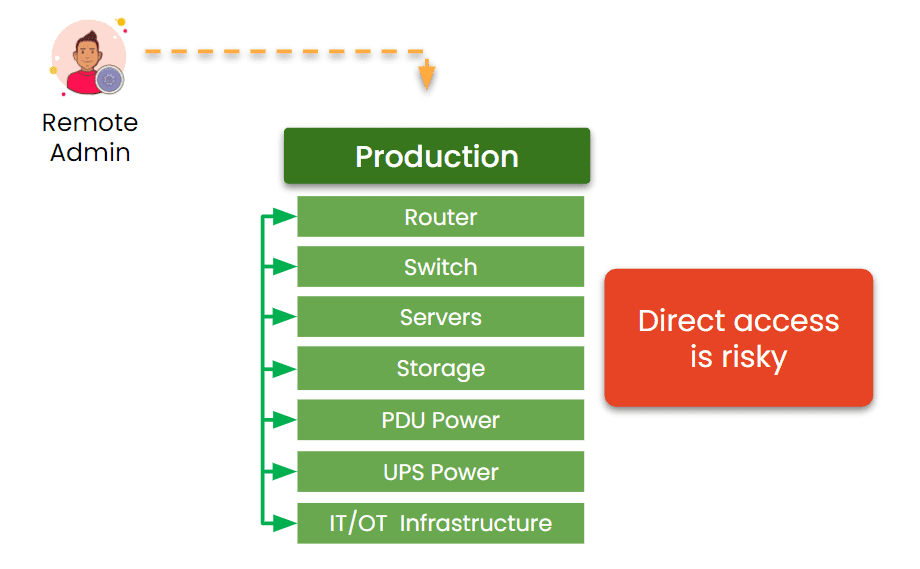
Image: Traditional network infrastructures are built so that remote admin access depends at least partially on the production network. If a production device fails, admin access is cut off.
This is why hyperscalers developed a specific best practice that is now catching on with large enterprises, Fortune companies, and even government agencies. This best practice is called Isolated Management Infrastructure, or IMI.
What is Isolated Management Infrastructure?
Isolated Management Infrastructure (IMI) separates management access from the production network. It’s a physically and logically distinct environment used exclusively for managing your infrastructure – servers, network switches, storage devices, and more. Remember the parachute analogy? It’s just like that: the reserve chute is a completely separate system designed to save you when the main system is compromised.
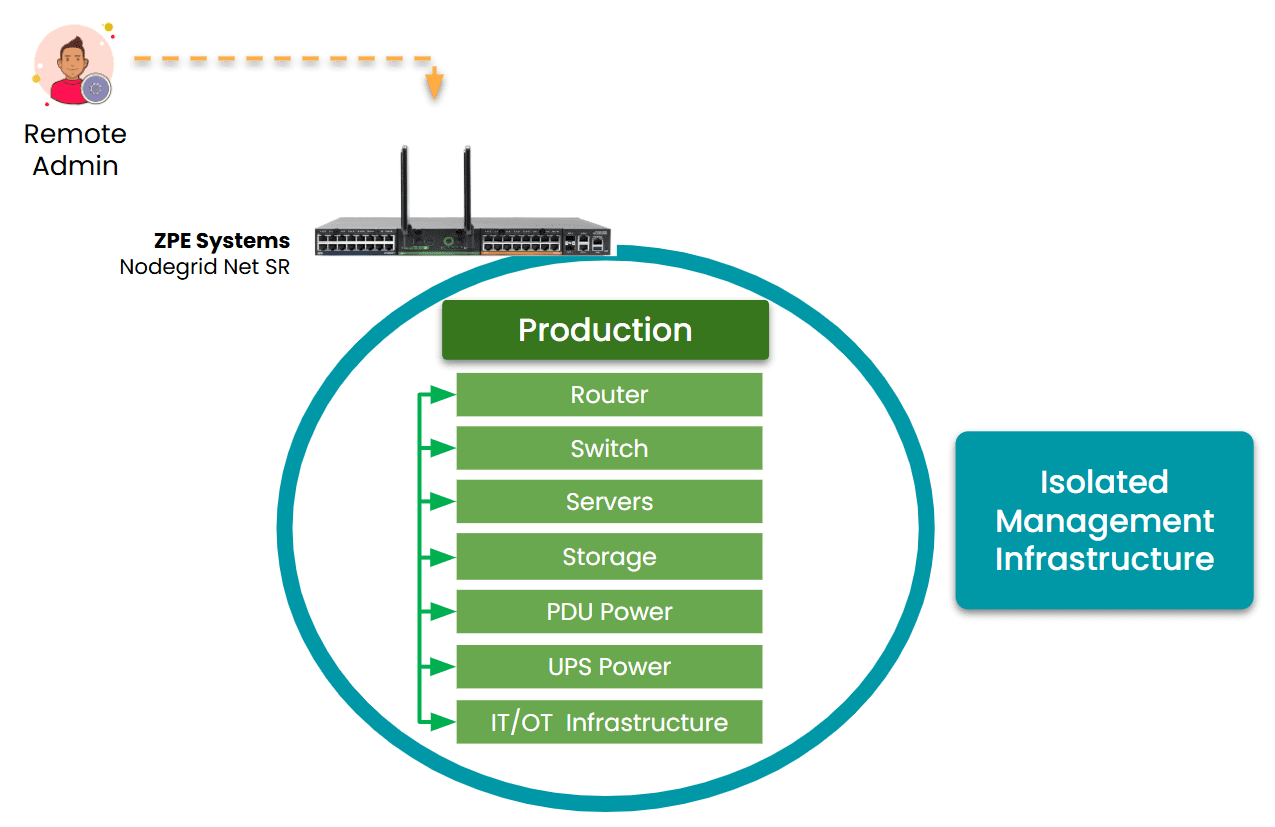
Image: Isolated Management Infrastructure fully separates management access from the production network, which gives admins a dependable path to ensure AI system reliability.
This isolation provides a reliable pathway to access and control AI infrastructure, regardless of what’s happening in the production environment.
How IMI Enhances AI System Reliability:
- Always-On Access to Infrastructure
Even if your production network is compromised or offline, IMI remains reachable for diagnostics, patching, or reboots. - Separation of Duties
Keeping management traffic separate limits the blast radius of failures or breaches, and helps you confidently apply or roll back config changes through a chain of command. - Rapid Problem Resolution
Admins can immediately act on alerts or failures without waiting for primary systems to recover, and instantly launch a Secure Isolated Recovery Environment (SIRE) to combat active cyberattacks. - Secure Automation
Admins are often reluctant to apply firmware/software updates or automation workflows out of fear that they’ll cause an outage. IMI gives them a safe environment to test these changes before rolling out to production, and also allows them to safely roll back using a golden image.
IMI vs. Out-of-Band: What’s the Difference?
While out-of-band (OOB) management is a component of many reliable infrastructures, it’s not sufficient on its own. OOB typically refers to a single device’s backup access path, like a serial console or IPMI port.
IMI is broader and architectural: it builds an entire parallel management ecosystem that’s secure, scalable, and independent from your AI workloads. Think of IMI as the full management backbone, not just a side street or second entrance, but a dedicated freeway. Stay tuned for a follow-up article that dives deeper into the differences between IMI and OOB.
AI System Reliability Use Case: Finance
Consider a financial services firm using AI for fraud detection. During a network misconfiguration incident, their LLMs stop receiving real-time data. Without IMI, engineers would be locked out of the systems they need to fix, similar to the CrowdStrike outage of 2024. But with IMI in place, they can restore routing in minutes, which helps them keep compliance systems online while avoiding regulatory fines, reputation damage, and other potential fallout.
AI System Reliability Use Case: Manufacturing
Consider a manufacturing company using AI-driven computer vision on the factory floor to spot defects in real time. When a firmware update triggers a failure across several edge inference nodes, the primary network goes dark. Production stops, and on-site technicians no longer have access to the affected devices. With IMI, the IT team can remote-into the management plane, roll back the update, and bring the system back online within minutes, keeping downtime to a minimum while avoiding expensive delays in order fulfillment.
How To Architect for AI System Reliability
Achieving AI system reliability starts well before the first model is trained and even before GPU racks come online. It begins at the infrastructure layer. Here are important things to consider when architecting your IMI:
- Build a dedicated management network that’s isolated from production.
- Make sure to support functions such as Ethernet switching, serial switching, jumpbox/crash-cart, 5G, and automation.
- Use zero-trust access controls and role-based permissions for administrative actions.
- Design your IMI to scale across data centers, colocation sites, and edge locations.
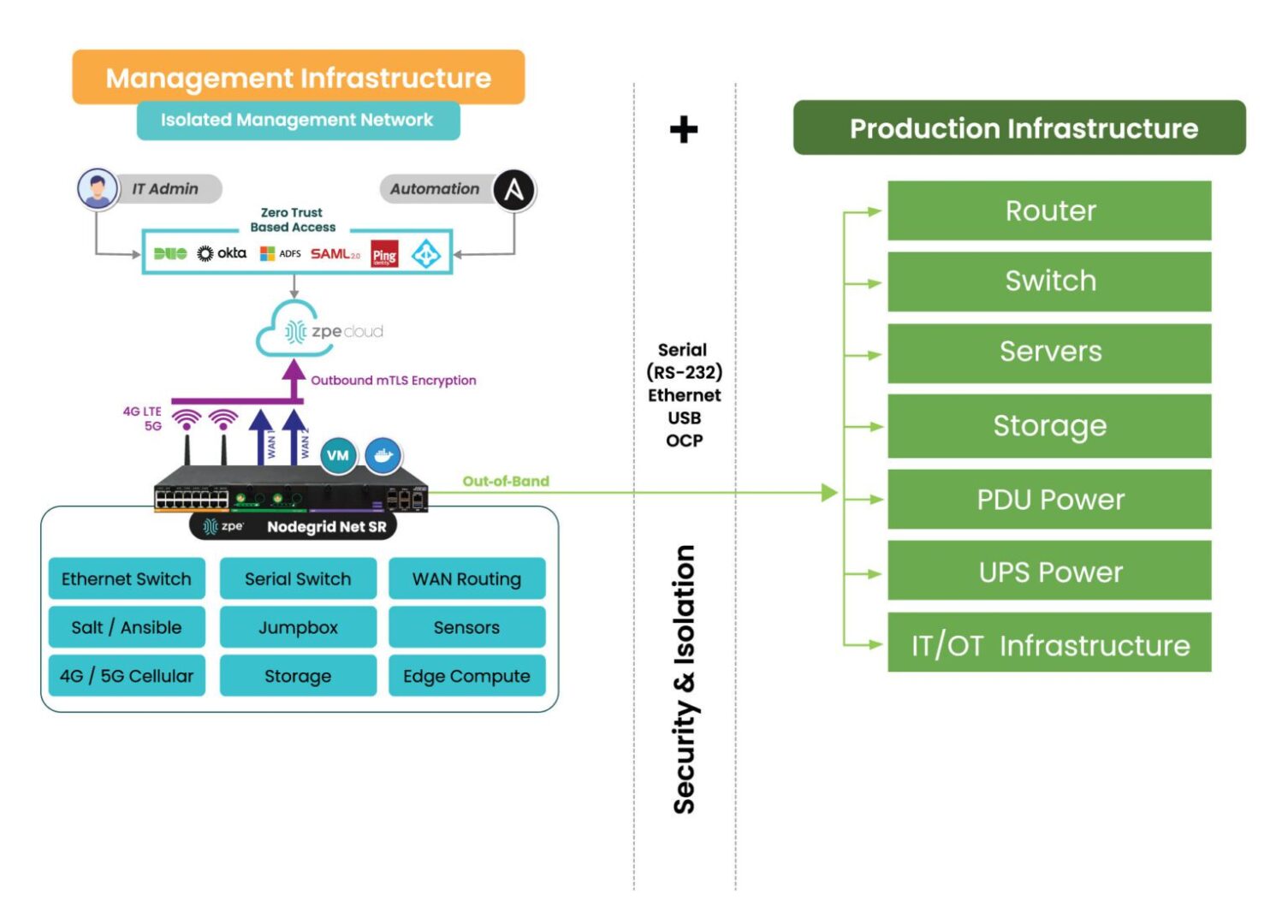
Image: Architecting AI system reliability using IMI means deploying Ethernet switches, serial switches, WAN routers, 5G, and up to nine total functions. ZPE Systems’ Nodegrid eliminates the need for separate devices, as these edge routers can host all the functions necessary to deploy a complete IMI.
By treating management access as mission-critical, you ensure that AI system reliability is built-in rather than reactive.
Download the AI Best Practices Guide
AI-driven infrastructure is quickly becoming the industry standard. Organizations that integrate an Isolated Management Infrastructure will gain a competitive edge in AI system reliability, while ensuring resilience, security, and operational control.
To help you implement IMI, ZPE Systems has developed a comprehensive Best Practices Guide for Deploying Nvidia DGX and Other AI Pods. This guide outlines the technical success criteria and key steps required to build a secure, AI-operated network.
Download the guide and take the next step in AI-driven network resilience.

Get in Touch for a Demo of AI Infrastructure Best Practices
Our engineers are ready to walk you through the basics and give you a demo of these best practices. Click below to set up a demo.
More AI Infrastructure Resources:
- The Elephant in the Data Center: How To Make AI Infrastructure Resilient
- Why Out-of-Band Management is Critical to AI Infrastructure
- Video: Optimizing Remote Management and AI Infrastructure Automation
- The Future of Data Centers: Overcoming the Challenges of Lights-Out Operations
- Out-of-Band Deployment Guide
- AI Orchestration: Solving Challenges to Improve AI Value