Zombie Servers: The Hidden Energy Drainers in Data Centers

The Cost of Zombie Servers
How ZPE Systems’ Nodegrid Fights Zombie Servers
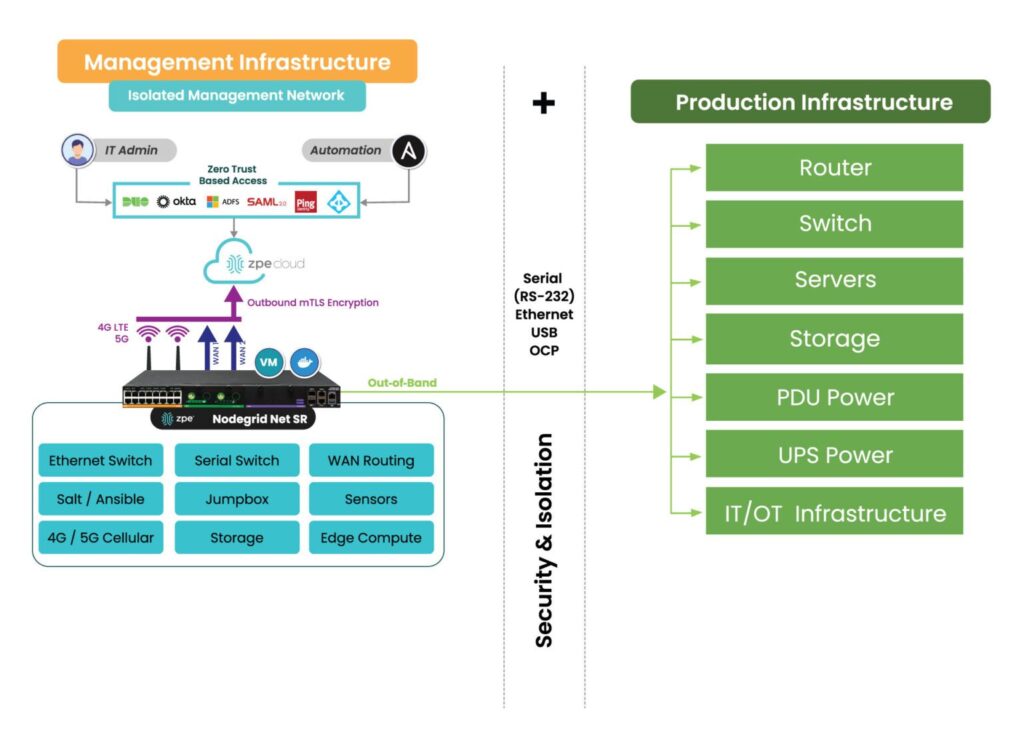
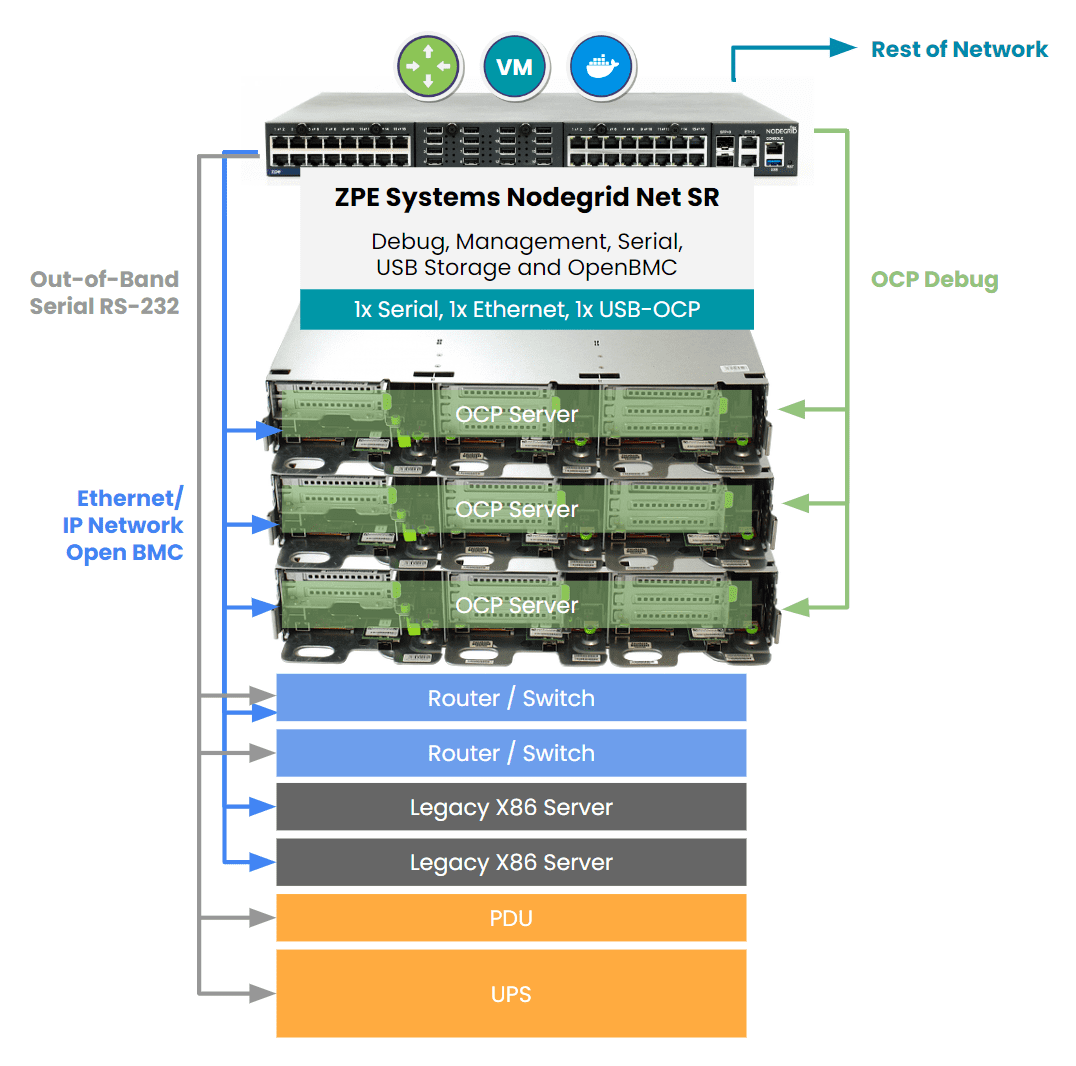
Out-of-band management (OOBM) solutions, like ZPE Systems’ Nodegrid, provide an effective way to monitor, manage, and optimize data center infrastructure, even when the primary network is down. When combined with ServerTech Intelligent PDUs, data center admins can remote-in to identify and address zombie servers, so they can ensure their operations run at peak efficiency.
Key Features of Nodegrid’s Out-of-Band Management for Zombie Server Management
- 24/7 Monitoring and Real-Time Insights: Nodegrid allows IT teams to continuously monitor server performance, making it easy to detect underutilized or idle servers. Real-time metrics show server activity, power usage, and health, so teams can pinpoint servers that may need to be repurposed or removed.
- Detailed Power Usage Data: The combined Nodegrid and ServerTech solution provides comprehensive energy usage data, so teams can see inefficiencies and where power is consumed most. This is essential for high-density data centers, where wasting even a little bit of power adds up to substantial costs. These insights help data center operators pinpoint zombie servers, reducing energy costs and freeing up space.
- Enhanced Automation and Management Control: With automation features, Nodegrid simplifies the complex task of managing server lifecycles. For instance, automated alerts can notify teams when a server reaches a specific threshold of low utilization, enabling quicker action to reassign or shut down the server.
- Increased Security and Resilience: Nodegrid enhances security by providing direct access to infrastructure via isolated management. Teams can access critical systems even during network failures, to ensure servers remain compliant, functional, and secure.
Benefits of Removing Zombie Servers
AI and other resource-intensive applications mean data centers need to be as efficient as possible. Zombie servers are not just an energy problem; they impact a data center’s ability to scale and meet demand for high-performance computing. Here are some benefits of removing or repurposing zombie servers:
- Energy Efficiency: Data centers can significantly lower energy costs and reduce environmental impact by shutting down idle servers.
- Cost Savings: Operating more efficiently by removing zombie servers can lead to substantial annual savings, freeing up resources for necessary expansions.
- Optimized AI-Ready Infrastructure: Freeing up resources allows data centers to repurpose space and energy toward servers that can support AI and other high-density applications.
Get Help Fighting Zombie Servers
Set up a call with one of ZPE Systems’ engineers, and we’ll show you how to get zombie servers out of your data center. Click the button below to schedule your call.
Watch a Walkthrough Demo
Watch this 20-minute video where Marcel van Zwienen (Senior Sales Engineer) demonstrates the remote management capabilities of Nodegrid and ZPE Cloud.

More Valuable Resources for Remote Monitoring
Check out these resources to help fight zombie servers and other inefficiencies lurking in your data center: