Gartner Market Guide for Edge Computing

Edge computing moves processing power and applications closer to the sources of data at the edges of the network, which improves performance and reduces risk. This approach is gaining popularity, with recent Gartner research finding that 69% of CIOs have already deployed edge technologies or would deploy by mid-2025. However, most edge deployments focus on individual use cases and lack a cohesive strategy, resulting in “edge sprawl”: many disparate solutions deployed all over the enterprise without centralized control or visibility.
“Edge computing without a strategy will eventually cause digital gridlock.” Thomas Bittman, Gartner Distinguished VP Analyst, in Building an Edge Computing Strategy
Edge sprawl increases complexity, reduces resilience, and ultimately hampers digital transformation. In a report published earlier this year titled “Building an Edge Computing Strategy,” Gartner provides recommendations for reducing edge sprawl with a comprehensive strategy. As we await the next Gartner Market Guide for Edge Computing, let’s discuss their recommendations for building a strategy to manage and orchestrate your edge solutions.
Building a Gartner-approved edge computing strategy
Gartner recommends building an edge computing strategy around five elements: vision, use cases, challenges, standards, and execution.
Gartner’s “Five Elements of an Edge Computing Strategy”
Edge computing vision
An edge computing vision describes the overall organizational goals and provides direction for teams and stakeholders. It should explain how edge computing supports and relates to other technology initiatives, such as cloud computing, IoT/OT devices, and artificial intelligence/machine learning, as well as how it fits into the overall digital transformation strategy.
Key components of an edge computing vision:
- The business impact of edge computing in objective terms, such as the amount of money saved
- How edge computing will accelerate digital transformation
- A discussion of the digital experience improvements enabled by edge computing
- The anticipated number of automation projects supported by edge computing
- What edge computing use cases will be deployed
- The targeted deployment agility in measurable terms, such as the time to deploy a new site
The edge computing vision provides the target your organization wants to reach in the next five years, and should be continuously updated as goals are met and strategies evolve. It’s crucial to clearly communicate the edge computing vision to get buy-in from executives and staff.
Edge computing use cases
There are often many edge computing use cases within an organization, and an effective edge computing strategy must identify and account for them all in order to avoid sprawl. There are three aspects to consider – the edge computing drivers, the existing edge computing use-case landscape, and potential edge computing use cases.
Edge computing drivers
Edge computing evolved to solve problems other computing architectures can’t handle. Understanding what those problems are will help you identify existing use cases and determine when edge computing should be pursued for a particular use case in the future. Gartner identifies four main edge computing drivers.
|
A rapid response is required, or the response time needs to be predictable, and current latency is unacceptable |
The cost of transmitting noisy, short-lived data is higher than the cost of moving compute to the edge |
|
Operations at the edge must continue even if the connection to the central data center or cloud is interrupted |
The privacy and security risks of transmitting edge data are too high, or regulatory requirements prevent it |
Existing edge computing use-case landscape
Many organizations already use edge computing in some form, even if they don’t call it by that name. Examples include operational technology (OT) deployments in the manufacturing industry and smart check-out systems in retail stores. An edge computing strategy must identify all existing solutions and discuss how they’ll be integrated with the chosen management technologies and best practices (more on those later).
Potential edge computing use cases
An effective edge computing strategy should also describe how the business will identify new use cases in the future. This proactive process should use the previously established edge computing drivers and involve collaboration between IT and the various business units within the organization. Gartner recommends creating a “clearinghouse” for new use case ideas, a structured process for identifying, reviewing, and prioritizing potential edge use cases.
Edge computing challenges
Even as edge computing solves business problems, it creates additional challenges that the strategy must address with new technologies and processes. Gartner identifies six major edge computing challenges to focus on while you develop an edge computing strategy.
- Enabling extensibility – Purpose-built edge computing solutions can’t adapt when workloads change or grow, so an edge computing strategy should leave room for growth by using extensible, vendor-neutral platforms that allow for expansion and integration.
- Extracting value from edge data – As edge devices generate more and more data, the difficulty of quickly extracting value from that data rises, so organizations should look for ways to deploy AI training and data analytics solutions alongside edge computing units.
- Governing edge data – Edge computing sites often have more significant data storage constraints than traditional data centers, so quickly distinguishing between valuable data and destroyable junk is critical to edge ROIs and requires careful governance.
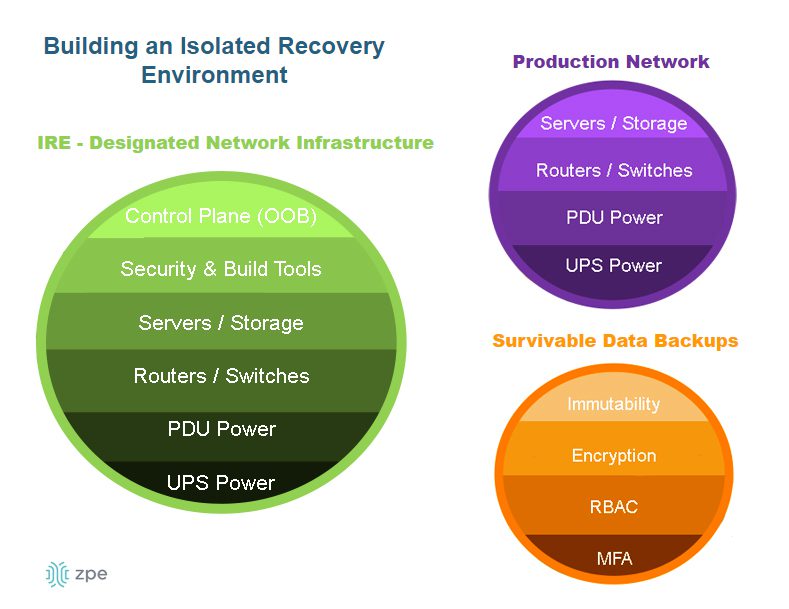
- Securing the edge – Edge deployments are highly distributed in locations that lack many security features in a traditional data center, adding risk and increasing the attack surface, so organizations should protect edge computing nodes with a multi-layered defense including zero-trust policies, strong authentication, and network micro-segmentation. Orgs also need a way to take back control of edge infrastructure during ransomware attacks, such as an isolated recovery environment (IRE).
- Supporting edge-native applications – Edge-native applications are designed for the edge from the bottom up, so organizations should deploy platforms that support these applications without increasing the technical debt, meaning they should use familiar technologies and interoperate with existing systems.
- Managing and orchestrating the edge – Environmental issues, power failures, and network outages can cut technical teams off from critical edge infrastructure, so organizations need edge management and orchestration (EMO) with environmental monitoring and out-of-band (OOB) connectivity.
Gartner recommends focusing your edge computing strategy on mitigating the specific risks, challenges, and inhibitors.
Edge computing standards
Edge computing use cases are often highly diverse, even within a single organization, so it’s critical to establish a set of unifying standards and guidelines to reduce edge sprawl. Many organizations use a cloud center of excellence (CCOE) to govern their cloud computing architecture, so Gartner recommends establishing a similar edge center of excellence (ECOE) based on three pillars.
| Governance: |
|
| Technologies: |
|
| Best Practices/Skills: |
|
For an effective edge computing strategy, Gartner recommends creating a unifying set of standards, guidelines, and best practices to be used across all edge computing deployments.
Edge computing execution
An edge computing strategy should include process documentation for the initial deployment of new edge rollouts. Gartner identifies six steps that help ensure successful edge computing launches.
- Proof of Concept – Test edge deployments in non-production and get feedback from stakeholders
- Proof of Production – Conduct a pilot to evaluate how you’ll operate, manage, and monitor an edge project at full scale
- Phased Rollout – Have a phased deployment plan including scale, regions, and functionality
- Surprises – Expect the unexpected by including guidelines in your edge computing strategy for monitoring and managing changes
- Evolution – Edge projects frequently change direction based on evolving requirements or unexpected changes, so extensibility is crucial
- Next-Best Action – Plans for the future frequently change direction, so have alternatives in your strategy to help guide these evolutions
An edge computing strategy that covers all six steps will streamline deployments and improve the agility of edge execution.
What to Expect from the Gartner Market Guide for Edge Computing
Last year, the Gartner Market Guide for Edge Computing discussed the issue of companies deploying individual edge solutions to handle individual use cases without any unified management and oversight. Part of the problem is that the edge computing market is still immature, and another hurdle is vendor lock-in. When edge computing solutions can’t interoperate with other vendors’ hardware and software, teams cannot deploy the universal hardware and unifying orchestration platforms to manage edge architectures efficiently.
Based on the market analysis provided in “Building an Edge Computing Strategy,” Gartner still heavily emphasizes the need to reduce edge sprawl with centralized, vendor-neutral edge management and orchestration (EMO). You can expect Gartner’s next market guide for edge computing to continue pushing for unified management and to highlight vendors with scalable, extensible, open edge computing solutions.
Building an edge computing strategy with Nodegrid
Nodegrid is a vendor-neutral edge infrastructure orchestration platform from ZPE Systems that can help you solve all six of Gartner’s edge computing challenges.
- Enabling extensibility – Nodegrid’s modular, extensible devices are easy to scale and adapt to handle changing workloads. Nodegrid management hardware runs the open, Linux-based Nodegrid OS, which can host your choice of third-party edge computing applications, so you can deploy and change edge software without buying additional hardware.
- Extracting value from edge data – Nodegrid’s powerful, extensible computing hardware can run data analysis, machine learning, and artificial intelligence applications to help extract additional value from the massive quantities of data at the edge.
- Governing edge data – Nodegrid’s ZPE Cloud platform offers a data lake application that helps process and organize edge data.
- Securing the edge – Nodegrid uses innovative hardware security and advanced, zero-trust authentication methods to defend edge networks, devices, and applications.
- Supporting edge-native applications – Nodegrid supports Docker containers and other edge-native technologies, allowing teams to use their choice of software platforms to reduce technical debt.
- Managing and orchestrating the edge – Nodegrid’s environmental monitoring sensors give remote teams real-time insights into conditions in edge deployment sites so they can respond to climate issues and power fluctuations as they occur. Nodegrid’s out-of-band (OOB) management creates an isolated management infrastructure that doesn’t rely on production network resources, giving teams a lifeline to troubleshoot and recover from outages, failures, and cyberattacks faster and more cost-effectively.
Nodegrid is a vendor-neutral Services Delivery Platform that brings all the components of your edge computing strategy under one management umbrella so you can overcome your biggest edge computing challenges.
Get streamlined edge computing with Nodegrid
To learn more about vendor-neutral edge management and orchestration (EMO) as described in the Gartner market guide for edge computing, contact ZPE Systems.
")