Part 1: Immutable Infrastructure: Challenges Your Company Needs to Be Aware of

Immutable infrastructure refers to the critical network resources and systems that make up your infrastructure and that are never updated, changed, or fixed in any way—they stay exactly the same. If something needs to be modified, the entire system or device is replaced by a new one. While this approach has many advantages for organizations, there are still some immutable infrastructure challenges you’ll need to overcome.
Mutable vs immutable infrastructure
Traditional infrastructure deployments are mutable and continuously change in place. Sysadmins and network engineers will constantly deploy patches, modify configurations, and install new software on systems and devices while they’re actively in use. The benefit of this approach is that you don’t need to create entirely new server instances or network deployments every time you want to change something.
However, mutable infrastructure does create some risk. For example, what if you deploy a patch that breaks a core function? What if some new code introduces a security vulnerability to the system? How about if an in-place upgrade fails halfway through and you end up with an unplanned version of the configuration? With mutable infrastructure, you’re stuck troubleshooting the issues and attempting to deploy fixes on systems and devices actively in use.
On the other hand, immutable infrastructure is frequently copied, deleted, and recreated without making changes to the systems currently in use. Configurations are abstracted as software code and managed from a centralized location that’s physically and logically separate from the target infrastructure. This code can be copied and deployed to many different targets as frequently as necessary. The environments themselves are virtualized (and often containerized) which creates an additional abstraction layer from the underlying hardware. This also makes it possible to copy, delete, and recreate instances as needed.
When an infrastructure as code (IaC) or software-defined networking (SDN) configuration needs to be updated, a new version of the code is written, deployed to a new instance, and tested to ensure functionality and security. Then, traffic is redirected to the new instance and the the old one is simply deleted. If a virtualized or containerized environment fails, or is compromised by a hacker, you can delete it and replace it with an exact copy with minimum hassle.
Immutable infrastructure is becoming popular among DevOps and NetDevOps organizations that use IaC and SDN to integrate resource provisioning directly into the software development pipeline. While this approach has clear advantages—including security improvement, IT complexity and failure decrement, and easier troubleshooting than mutable infrastructure—there are also some immutable infrastructure challenges.
Immutable infrastructure challenges
The immutable infrastructure paradigm was initially conceptualized for hyperscale and enterprise data center deployments. It relies on software-defined technology stacks and orchestration solutions that automate deployment and provisioning. The challenge comes when you need to venture outside of this ideal deployment, as is the case for many organizations.
Modern enterprise networks are shifting away from massive, centralized data centers because modern enterprises are themselves less centralized than they used to be. As operations become more globalized and remote, distributed workforces evolve the norm, and enterprises deploy infrastructure closer to the network edge. Edge network infrastructure is deployed to small local data centers, branch offices, remote warehouses, and other distributed locations. Often, these smaller deployments rely on hardware-based appliances, servers, and legacy equipment.
This creates some significant challenges when you try to shift to immutable infrastructure, including:
- Extending the software-defined network automation and orchestration to remote locations outside your enterprise network.
- Bringing the orchestrator’s hooks into all of your disparate legacy hardware solutions.
- Finding a way to apply immutable principles to this mutable hardware-based infrastructure.
Solving immutable infrastructure challenges
Immutable infrastructure requires centralized orchestration of software-defined technology, so you need to apply SDN to WAN architecture to bring immutable to the edge. This is called SD-WAN, or software-defined wide area network. SD-WAN decouples the management of your WAN from the underlying hardware, so you can use orchestration to control distributed WAN architecture.
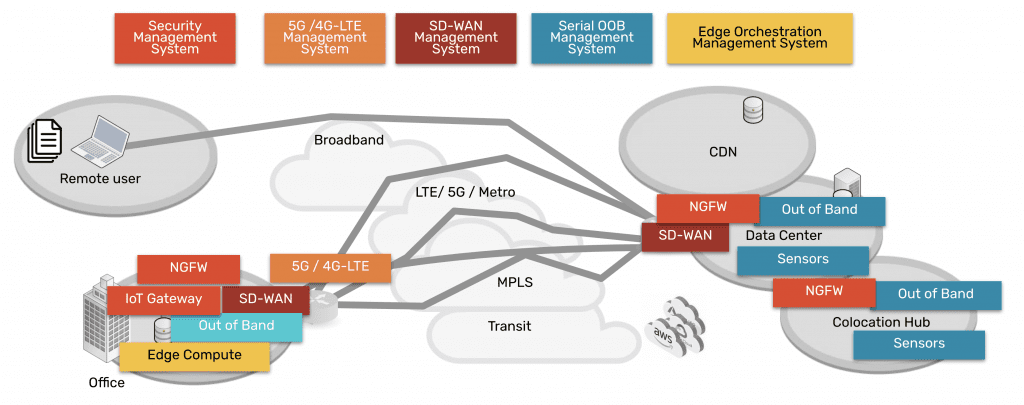
However, SD-WAN only gets you to the perimeter of your edge networks. To use immutable infrastructure effectively, you also need to extend the orchestrator’s reach into the branch and edge LANs. You can achieve this through SD-Branch technology, which gives you software-defined control over the internal networking infrastructure of remote architectures.
The second goal is to ensure that your orchestration solution can see and control every piece of your edge architecture, even legacy systems not designed with automation in mind. The SD-WAN/SD-Branch gateways and console servers you install at the edge need to support legacy pinouts and integrate with third-party hardware and software. If the edge connectivity solution can’t say yes to every component of your distributed network infrastructure, you’ll have gaps in the software-defined orchestration coverage.
The third task is to turn mutable hardware into immutable infrastructure, which you can accomplish through virtualization. In the same way that a single physical server can be turned into many different virtual machines, you can use network functions virtualization (NFV) to turn physical networking appliances into virtualized solutions. NFV creates an abstraction layer that separates the underlying hardware’s routing, switching, load-balancing, and other management functions. This allows your orchestrator to manage these functions automatically and create, copy, delete, and recreate network configurations at will without worrying about the mutable hardware.
The tricky thing about solving each of these challenges is that you need a truly vendor-neutral solution to make it all work. For example, if you have different branch gateways in different locations, you need to ensure that the SD-WAN/SD-Branch platform will integrate with all of them. Otherwise, you’ll need to manage multiple software-defined technology stacks, or you’ll lose the ability to apply immutable principles consistently across your entire distributed network.
The network functions virtualization platform also needs to support all of your disparate vendor hardware and legacy architecture; otherwise, you won’t be able to turn all mutable infrastructure into virtualized, immutable solutions. Plus, the orchestrator needs to integrate with your NFV platform as well as all edge hardware and software, to have full coverage.
Many immutable infrastructure solutions fall short of true vendor-neutrality. That means, to use them effectively, you have to upgrade your edge infrastructure hardware and software to compatible versions. This is an expensive and time-consuming endeavor and one that creates a massive roadblock for globally distributed enterprises hoping to adopt immutable principles.
Nodegrid brings immutable infrastructure to edge networks
ZPE Systems can help you bring immutable infrastructure to your edge networks with the vendor-neutral Nodegrid platform. Nodegrid’s powerful, all-in-one branch gateways give you the best of both worlds: you can use our powerful SD-WAN and SD-Branch technology or directly host your choice of third-party software-defined networking solutions. The modular design of the Nodegrid Net Services Router (NSR) also gives you added capabilities like edge compute, terminal server, NetDevOps, and more.
The vendor-neutral ZPE Cloud orchestration platform can say yes to every component of your distributed network architecture, including legacy hardware appliances and systems. ZPE Cloud gives you complete control over your mutable hardware, making it possible to apply software-defined orchestration to even the smallest branch deployments.
Plus, all Nodegrid devices run on the vendor-neutral, Linux-based Nodegrid OS with support for NFV. You can use Nodegrid OS to virtualize every piece of the edge networking stack, turning mutable branch hardware into immutable, automated solutions.
Learn how Nodegrid can solve your immutable infrastructure problems.
Call 1-844-4ZPE-SYS to see a demo.