Best Intel NUC Alternatives

Service providers often struggle with the hybrid nature of their business. Even as they transition more towards a consumable service-based model that’s decoupled from traditional hardware solutions, there’s still a need for some sort of box to be deployed physically at a customer’s premises. Providers frequently rely on COTS (Common Off The Shelf) hardware to reduce costs and simplify the deployment process.
One commonly used COTS device is the Intel NUC, or “Next Unit of Computing,” which is a small appliance-like mini computer. Some service providers utilize Intel NUC devices as jump boxes, while others use them as a platform to deploy their services on-site. While these mini-computers are relatively inexpensive and easy to install, they create added security risks and management headaches that service providers need to be aware of.
This post highlights the challenges and security risks involved in relying on Intel NUC devices before discussing enterprise-grade Intel NUC alternatives that solve these problems.
| Table of contents: |
Why is Intel NUC so popular in IT infrastructure?
Managed Service Providers (MSPs) and Managed Security Service Providers (MSSPs) often use Intel NUC jump boxes to remotely access the control plane of critical client infrastructure. These mini PCs typically run bare bones software to reduce licensing costs, which means they are unpatched, unmonitored, and unsecured. This lack of oversight and management makes Intel NUCs popular access points for hackers to breach client networks.
Why consider Intel NUC alternatives?
Service providers like to use Intel NUC boxes because they’re cheaper, faster to install, and take up less space than a full PC or server. NUCs are often deployed without antivirus, monitoring agents, or other security software installed, which excludes them from the service provider’s security coverage. Plus, clients are frequently unaware that these devices are in their racks accessing their infrastructure, so they don’t access them in security and compliance audits. Other Intel NUC challenges include:
- Lack of centralized management – Each Intel NUC is an island that’s managed and accessed individually, which makes it impossible to efficiently deploy updates, install new tools, or monitor for problems.
- Insecure, unpatched OS – Operating systems and software contain thousands of potential vulnerabilities that hackers can exploit, so a lack of monitoring and patch management creates a huge security risk.
- No hardware security – Intel NUC boxes lack any hardware security, which means someone could steal the device and use it to deploy malware or access client resources – or even just pawn the hardware.
- Regulatory issues – When providers use unmanaged jump boxes to access client infrastructure, they expose their customers to potential noncompliance with privacy laws like HIPAA that require strict data access controls.
- Affects insurance eligibility – Using an unsecured Intel NUC may also disqualify customers from receiving cybersecurity insurance benefits in the event of a successful breach.
While Intel NUCs are a quick and inexpensive way for MSPs, MSSPs, and other service providers to remotely access client infrastructure, they also make it easier for cybercriminals to breach enterprise networks. To reduce the attack surface without increasing the cost, hassle, or footprint of deploying jump boxes, you need an enterprise-grade solution that combines networking functions, security, and remote out-of-band access to the control plane to eliminate the need for a separate device.
Intel NUC alternatives from ZPE Systems
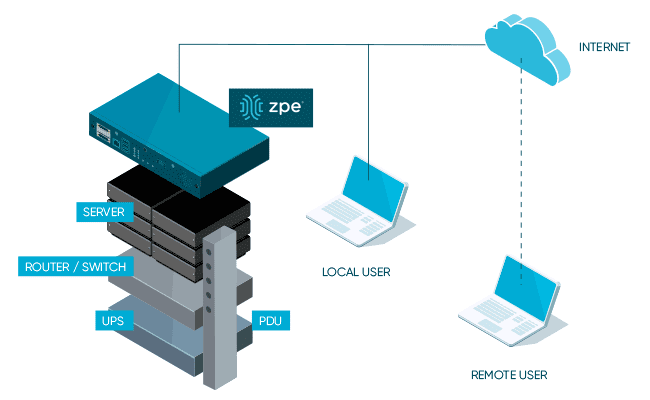
The Nodegrid product line from ZPE Systems simplifies the tech stack in data centers and network closets with all-in-one infrastructure management solutions. Nodegrid devices roll up gateway routing, switching, Wi-Fi, and 5G/4G/LTE out-of-band management to cut down on the number of boxes in the rack. They’re also enterprise solutions, which means they can be onboarded with your security team and covered by your monitoring, intrusion detection, antivirus, and other security controls.
In addition, all Nodegrid boxes are protected by hardware security features such as BIOS protection, self-encrypted disk (SED), UEFI Secure Boot, and Signed OS. Plus, Nodegrid’s hardware and software are completely vendor-neutral, allowing easy integrations with third-party security solutions and SAML 2.0 authentication. Nodegrid can even directly host other vendors’ security software to further reduce your tech stack.
Key Nodegrid features
To learn more about the benefits of Nodegrid’s Intel NUC alternatives, contact ZPE Systems.
Nodegrid product comparison
The Nodegrid family of network edge routers delivers secure, Gen 3 OOB management for reliable remote access to distributed customer sites like branch offices or manufacturing centers.
Nodegrid Service Delivery Platform Family
The Nodegrid family of Intel NUC alternatives from ZPE Systems can help MSPs and MSSPs ensure secure, reliable remote management access to customer infrastructure without increasing costs.
Ready for a Demo?
To see one of ZPE’s Intel NUC alternatives in action, request a free Nodegrid demo! Request a Demo



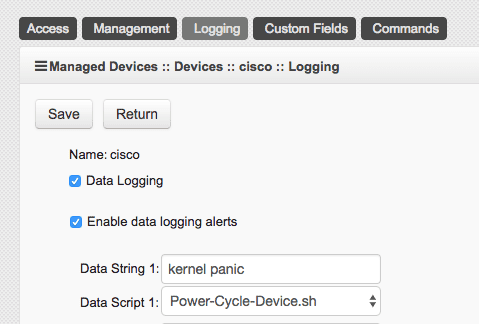 Set actionable string alerts and notifications whenever a known problem occurs – Choose any or all of the following notification types: e-mail, text, syslog, or snmptrap.
Set actionable string alerts and notifications whenever a known problem occurs – Choose any or all of the following notification types: e-mail, text, syslog, or snmptrap.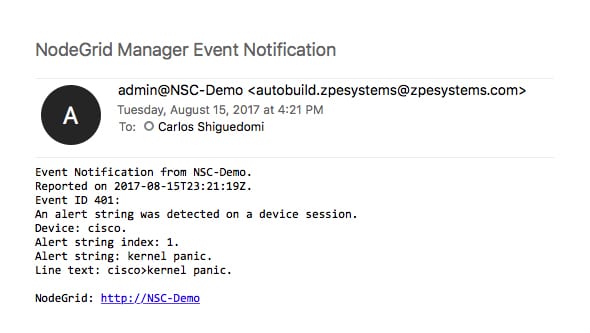 Nodegrid allows you to take actions based on string matches and console output. A recurring issue pops up, if its string matches, your selected script will be executed to alleviate the problem. Automate your fixes to save time and money.
Nodegrid allows you to take actions based on string matches and console output. A recurring issue pops up, if its string matches, your selected script will be executed to alleviate the problem. Automate your fixes to save time and money.