How to build a secure isolated recovery environment (SIRE)
.")
Ransomware is one of the biggest cybersecurity threats to enterprises. Sophos reports that in 2024, 59% of organizations suffered a ransomware attack, and the average cost to recover (excluding ransom payment) was $2.73 million. The frequency of ransomware attacks is so high that it’s no longer a question of ‘if,’ but ‘when’ an organization will be hit. Since ransomware encrypts critical data, applications, and systems, an attack can be extremely disruptive to business. During prolonged downtime, revenue slows or stops altogether, recovery costs skyrocket, and the company’s reputation and customers’ trust are severely damaged.
To reduce ransomware recovery times, companies must shift their focus away from prevention and detection and instead invest more time and money into recovery strategies. Ransomware recovery is especially challenging because of how easily its malicious code can spread from production into backup data and systems. What’s needed, according to the experts at Gartner, is a designated, secure isolated recovery environment (SIRE) that’s fully separated from the production infrastructure.
What is a secure isolated recovery environment (SIRE)?
A recovery environment is made up of systems and network resources that are dedicated to recovering from ransomware and other cybersecurity breaches. The recovery environment is where teams work to restore data and rebuild applications before they’re pushed back to the production network.
Many organizations implement a recovery environment by creating an isolated VLAN on the enterprise network. However, if the recovery environment has any dependencies on the production network, there’s a risk that ransomware will cut off access. For example, if malware infects authentication systems, routers, or switches, then admins might lose access to the recovery VLAN. In addition, production dependencies provide a way for ransomware to jump to the recovery environment, reinfecting systems and spoiling recovery efforts.
A secure isolated recovery environment (SIRE) uses a designated network infrastructure that’s completely separate from the production environment. The SIRE uses tools like Retention Lock, role-based access control (RBAC), and out-of-band (OOB) management to ensure that admins can quickly recover critical business services without the risk of reinfection. Let’s discuss these components in greater detail, as well as how to implement them to create an IRE.
How to build a secure isolated recovery environment
The ideal SIRE is built around three concepts: survivable data, separation and isolation, and designated infrastructure.

Survivable data
Ransomware earned its name because it encrypts data and systems and demands a ransom (typically in the form of cryptocurrency) to get the decryption key. However, there’s no guarantee that the attackers will provide a valid decryption key upon receiving their bounty, so it’s best to avoid the cost and risk altogether by ensuring you have clean backup data. These backups are known as survivable data – data that can’t be removed or encrypted by attackers.
To ensure your backup data is survivable, you should implement:
- Immutability: Something is considered immutable if it can’t be changed in any way, such as immutable infrastructure. Immutable data backups can’t be modified once they’re in place, which makes it impossible for ransomware and other malware to encrypt or corrupt the files. Data immutability can be enforced with tools such as Retention Lock.
- Encryption: For backup data to be survivable, it must be encrypted both in transit and at rest. This is sort of like fighting fire with fire – if your data is already encrypted, it will be much harder for ransomware to apply its own encryption. Plus, encrypting data in transit makes it harder for attackers to intercept and steal it as it’s moving between your production, backup, and recovery environments.
- RBAC: Role-based access control, or RBAC, refers to policies that restrict access based on an account’s role or function (e.g., ‘administrators,’ or ‘human resources’). Ideally, only the key personnel involved in recovery operations (their role may be ‘recovery engineers,’ for example) will have access to backup systems, which limits the risk that over-privileged accounts will be compromised and used to exfiltrate data.
- MFA: Multi-factor authentication, or MFA, forces users to prove their identity in multiple ways before they can access a system or application. For example, an admin may need to provide their username and password, plus a six-digit code sent to their authorized mobile device or email address, to prove that they are who they say they are. If an attacker steals an admin’s username and password, MFA prevents them from being able to access, steal, or encrypt backup systems.
Separation and isolation
Recovery efforts need to take place in an isolated environment so there’s no risk that malware will cross over from the production network. Newly recovered systems, applications, and data also need to be scanned and verified to ensure they’re clean before they’re reintegrated into production. The only way to achieve this is by building a completely isolated environment using a designated network infrastructure.
Designated infrastructure
The SIRE needs to be both physically and logically separated from the production network to ensure there’s a completely clean environment in which to perform system, application, and data restoration. That means the SIRE should have its own routers, switches, storage devices, compute options, and power. In addition, the SIRE needs its own out-of-band (OOB) control plane that’s accessible via a dedicated network interface (such as 4G or 5G cellular). This will ensure that admins have continuous remote access to the SIRE even if the LAN or WAN goes down due to configuration errors or other problems.
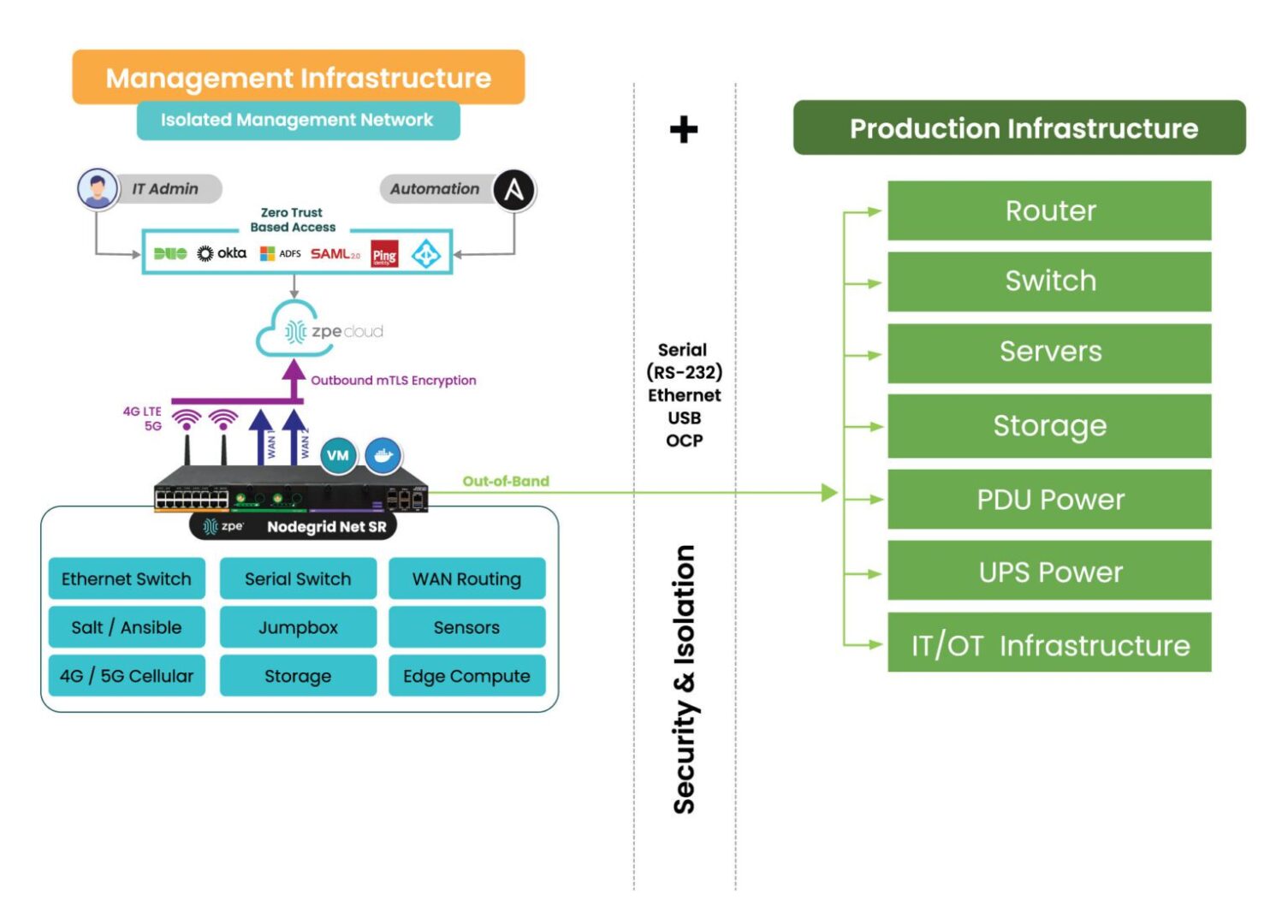
Image: Deploying a SIRE is only possible through the use of a dedicated control plane, or Isolated Management Infrastructure shown here.
Teams will also need access to their security and build tools in the SIRE, so these need to be configured and ready to go before an attack occurs. Organizations also must ensure the secure isolated recovery environment has enough storage to handle all of the backup data and server rebuilds.
Additional resources for building a secure isolated recovery environment (SIRE)
A secure isolated recovery environment (SIRE) ensures that admins have a dedicated environment in which to rebuild and restore critical business services during a ransomware attack. Survivable data backups, complete isolation, and designated infrastructure are needed to maintain the integrity of recovery operations and prevent reinfection.
For more information about how to recover from ransomware using a secure isolated recovery environment, download our whitepaper, 3 Steps to Ransomware Recovery.
Implementing and using a SIRE requires Isolated Management Infrastructure. IMI provides the management foundation and is a best practice recommended by CISA, because it fully separates admin access from relying on production infrastructure. Through IMI, teams gain a host of capabilities including out-of-band management and remote access, which not only help with ransomware recovery, but also for break/fix troubleshooting, device monitoring, and outage recovery. The ZPE Systems team created the blueprint that organizations can use to implement this crucial IMI foundation.
To get the blueprint for building Isolated Management Infrastructure, download the Network Automation Blueprint.
Want to see the Secure Isolated Recovery Environment in action?
Our engineers are ready to show you what it takes to recover from ransomware. Click the button to get in touch, and we’ll walk you through IMI, out-of-band, and the Secure Isolated Recovery Environment.



")
