Telecommunications networks are vast and extremely distributed, with critical network infrastructure deployed at core sites like Internet exchanges and data centers, business and residential customer premises, and access sites like towers, street cabinets, and cell site shelters. This distributed nature lends itself well to edge computing, which involves deploying computing resources like CPUs and storage to the edges of the network where the most valuable telecom data is generated. Edge computing allows telecom companies to leverage data from CPE, networking devices, and users themselves in real-time, creating many opportunities to improve service delivery, operational efficiency, and resilience.
This blog describes four edge computing use cases in telecom before describing the benefits and best practices for edge computing in the telecommunications industry.
4 Edge computing use cases in telecom
1. Enhancing the customer experience with real-time analytics
Each customer interaction, from sales calls to repair requests and service complaints, is a chance to collect and leverage data to improve the experience in the future. Transferring that data from customer sites, regional branches, and customer service centers to a centralized data analysis application takes time, creates network latency, and can make it more difficult to get localized and context-specific insights. Edge computing allows telecom companies to analyze valuable customer experience data, such as network speed, uptime (or downtime) count, and number of support contacts in real-time, providing better opportunities to identify and correct issues before they go on to affect future interactions.
2. Streamlining remote infrastructure management and recovery with AIOps
AIOps helps telecom companies manage complex, distributed network infrastructure more efficiently. AIOps (artificial intelligence for IT operations) uses advanced machine learning algorithms to analyze infrastructure monitoring data and provide maintenance recommendations, automated incident management, and simple issue remediation. Deploying AIOps on edge computing devices at each telecom site enables real-time analysis, detection, and response, helping to reduce the duration of service disruptions. For example, AIOps can perform automated root-cause analysis (RCA) to help identify the source of a regional outage before technicians arrive on-site, allowing them to dive right into the repair. Edge AIOps solutions can also continue functioning even if the site is cut off from the WAN or Internet, potentially self-healing downed networks without the need to deploy repair techs on-site.
3. Preventing environmental conditions from damaging remote equipment
Telecommunications equipment is often deployed in less-than-ideal operating conditions, such as unventilated closets and remote cell site shelters. Heat, humidity, and air particulates can shorten the lifespan of critical equipment or cause expensive service failures, which is why it’s recommended to use environmental monitoring sensors to detect and alert remote technicians to problems. Edge computing applications can analyze environmental monitoring data in real-time and send alerts to nearby personnel much faster than cloud- or data center-based solutions, ensuring major fluctuations are corrected before they damage critical equipment.
4. Improving operational efficiency with network virtualization and consolidation
Another way to reduce management complexity – as well as overhead and operating expenses – is through virtualization and consolidation. Network functions virtualization (NFV) virtualizes networking equipment like load balancers, firewalls, routers, and WAN gateways, turning them into software that can be deployed anywhere – including edge computing devices. This significantly reduces the physical tech stack at each site, consolidating once-complicated network infrastructure into, in some cases, a single device. For example, the Nodegrid Gate SR provides a vendor-neutral edge computing platform that supports third-party NFVs while also including critical edge networking functionality like out-of-band (OOB) serial console management and 5G/4G cellular failover.
Edge computing in telecom: Benefits and best practices
Edge computing can help telecommunications companies:
Get actionable insights that can be leveraged in real-time to improve network performance, service reliability, and the support experience.
Reduce network latency by processing more data at each site instead of transmitting it to the cloud or data center for analysis.
Lower CAPEX and OPEX at each site by consolidating the tech stack and automating management workflows with AIOps.
Prevent downtime with real-time analysis of environmental and equipment monitoring data to catch problems before they escalate.
Accelerate recovery with real-time, AIOps root-cause analysis and simple incident remediation that continues functioning even if the site is cut off from the WAN or Internet.
Management infrastructure isolation, which is recommended by CISA and required by regulations like DORA, is the best practice for improving edge resilience and ensuring a speedy recovery from failures and breaches. Isolated management infrastructure (IMI) prevents compromised accounts, ransomware, and other threats from moving laterally from production resources to the interfaces used to control critical network infrastructure.
To ensure the scalability and flexibility of edge architectures, the best practice is to use vendor-neutral platforms to host, connect, and secure edge applications and workloads. Moving away from dedicated device stacks and taking a “platformization” approach allows organizations to easily deploy, update, and swap out functions and services on demand. For example, Nodegrid edge networking solutions have a Linux-based OS that supports third-party VMs, Docker containers, and NFVs. Telecom companies can use Nodegrid to run edge computing workloads as well as asset management software, customer experience analytics, AIOps, and edge security solutions like SASE.
Vendor-neutral platforms help reduce hardware overhead costs to deploy new edge sites, make it easy to spin-up new NFVs to meet increased demand, and allow telecom organizations to explore different edge software capabilities without costly hardware upgrades. For example, the Nodegrid Gate SR is available with an Nvidia Jetson Nano card that’s optimized for AI workloads, so companies can run innovative artificial intelligence at the edge alongside networking and infrastructure management workloads rather than purchasing expensive, dedicated GPU resources.
Finally, to ensure teams have holistic oversight of the distributed edge computing architecture, the best practice is to use a centralized, cloud-based edge management and orchestration (EMO) platform. This platform should also be vendor-neutral to ensure complete coverage and should use out-of-band management to provide continuous management access to edge infrastructure even during a major service outage.
Streamlined, cost-effective edge computing with Nodegrid
Nodegrid’s flexible, vendor-neutral platform adapts to all edge computing use cases in telecom. Watch a demo to see Nodegrid’s telecom solutions in action.
Retail organizations must constantly adapt to meet changing customer expectations, mitigate external economic forces, and stay ahead of the competition. Technologies like the Internet of Things (IoT), artificial intelligence (AI), and other forms of automation help companies improve the customer experience and deliver products at the pace demanded in the age of one-click shopping and two-day shipping. However, connecting individual retail locations to applications in the cloud or centralized data center increases network latency, security risks, and bandwidth utilization costs.
Edge computing mitigates many of these challenges by decentralizing cloud and data center resources and distributing them at the network’s “edges,” where most retail operations take place. Running applications and processing data at the edge enables real-time analysis and insights and ensures that systems remain operational even if Internet access is disrupted by an ISP outage or natural disaster. This blog describes five potential edge computing use cases in retail and provides more information about the benefits of edge computing for the retail industry.
5 Edge computing use cases in retail
.
1. Security video analysis
Security cameras are crucial to loss prevention, but constantly monitoring video surveillance feeds is tedious and difficult for even the most experienced personnel. AI-powered video surveillance systems use machine learning to analyze video feeds and detect suspicious activity with greater vigilance and accuracy. Edge computing enhances AI surveillance by allowing solutions to analyze video feeds in real-time, potentially catching shoplifters in the act and preventing inventory shrinkage.
2. Localized, real-time insights
Retailers have a brief window to meet a customer’s needs before they get frustrated and look elsewhere, especially in a brick-and-mortar store. A retail store can use an edge computing application to learn about customer behavior and purchasing activity in real-time. For example, they can use this information to rotate the products featured on aisle endcaps to meet changing demand, or staff additional personnel in high-traffic departments at certain times of day. Stores can also place QR codes on shelves that customers scan if a product is out of stock, immediately alerting a nearby representative to provide assistance.
3. Enhanced inventory management
Effective inventory management is challenging even for the most experienced retail managers, but ordering too much or too little product can significantly affect sales. Edge computing applications can improve inventory efficiency by making ordering recommendations based on observed purchasing patterns combined with real-time stocking updates as products are purchased or returned. Retailers can use this information to reduce carrying costs for unsold merchandise while preventing out-of-stocks, improving overall profit margins. .
Using IoT devices to monitor and control building functions such as HVAC, lighting, doors, power, and security can help retail organizations reduce the need for on-site facilities personnel, and make more efficient use of their time. Data analysis software helps automatically optimize these systems for efficiency while ensuring a comfortable customer experience. Running this software at the edge allows automated processes to respond to changing conditions in real-time, for example, lowering the A/C temperature or routing more power to refrigerated cases during a heatwave.
5. Warehouse automation
The retail industry uses warehouse automation systems to improve the speed and efficiency at which goods are delivered to stores or directly to users. These systems include automated storage and retrieval systems, robotic pickers and transporters, and automated sortation systems. Companies can use edge computing applications to monitor, control, and maintain warehouse automation systems with minimal latency. These applications also remain operational even if the site loses internet access, improving resilience.
Edge computing decreases the number of network hops between devices and the applications they rely on, reducing latency and improving the speed and reliability of retail technology at the edge.
Real-time insights
Edge computing can analyze data in real-time and provide actionable insights to improve the customer experience before a sale is lost or reduce waste before monthly targets are missed.
Improved resilience
Edge computing applications can continue functioning even if the site loses Internet or WAN access, enabling continuous operations and reducing the costs of network downtime.
Risk mitigation
Keeping sensitive internal data like personnel records, sales numbers, and customer loyalty information on the local network mitigates the risk of interception and distributes the attack surface.
Edge computing can also help retail companies lower their operational costs at each site by reducing bandwidth utilization on expensive MPLS links and decreasing expenses for cloud data storage and computing. Another way to lower costs is by using consolidated, vendor-neutral solutions to run, connect, and secure edge applications and workloads.
For example, the Nodegrid Gate SR integrated branch services router delivers an entire stack of edge networking, infrastructure management, and computing technologies in a single, streamlined device. The open, Linux-based Nodegrid OS supports VMs and Docker containers for third-party edge computing applications, security solutions, and more. The Gate SR is also available with an Nvidia Jetson Nano card that’s optimized for AI workloads to help retail organizations reduce the hardware overhead costs of deploying artificial intelligence at the edge.
Consolidated edge computing with Nodegrid
Nodegrid’s flexible, scalable platform adapts to all edge computing use cases in retail. Watch a demo to see Nodegrid’s retail network solutions in action.
The world as we know it is connected to IT, and IT relies on its underlying infrastructure. Organizations must prioritize maintaining this infrastructure; otherwise, any disruption or breach has a ripple effect that takes services offline for millions of users (take 2024’s CrowdStrike outage, for example). A big part of this maintenance is ensuring that all hardware components, including console servers, are up-to-date and secure. Most console servers reach end-of-life (EOL) and need to be replaced, but for many reasons, whether budgetary concerns or the “if it isn’t broken” mentality, IT teams often keep their EOL devices. Let’s look at the risks of using EOL console servers, and why replacing them goes hand-in-hand with securing IT.
The Risks of Using End-of-Life Console Servers
End-of-life console servers can undermine the security and functionality of IT systems. These risks include:
1. Lack of Security Features and Updates
Aging console servers lack adequate hardware and management security features, meaning they can’t support a zero trust approach. On top of this, once a console server reaches EOL, the manufacturer stops providing security patches and updates. The device then becomes vulnerable to newly discovered CVEs and complex cyberattacks (like the MOVEit and Ragnar Locker breaches). Cybercriminals often target outdated hardware because they know that these devices are no longer receiving updates, making them easy entry points for launching attacks.
2. Compliance Issues
Many industries have stringent regulatory requirements regarding data security and IT infrastructure. DORA, NIS2 (EU), NIST2 (US), PCI 4.0 (finance), and CER Directive are just a few of the updated regulations that are cracking down on how organizations architect IT, including the management layer. Using EOL hardware can lead to non-compliance, resulting in fines and legal repercussions. Regulatory bodies expect organizations to use up-to-date and secure equipment to protect sensitive information.
3. Prolonged Recovery
EOL console servers are prone to failures and inefficiencies. As these devices age, their performance deteriorates, leading to increased downtime and disruptions. Most console servers are Gen 2, meaning they offer basic remote troubleshooting (to address break/fix scenarios) and limited automation capabilities. When there is a severe disruption, such as a ransomware attack, hackers can easily access and encrypt these devices to lock out admin access. Organizations then must endure prolonged recovery (like the CrowdStrike outage, or 2023’s MGM attack) because they need to physically decommission and restore their infrastructure.
The Importance of Replacing EOL Console Servers
Here’s why replacing EOL console servers is essential to securing IT:
1. Modern Security Approach
Zero trust is an approach that uses segmentation across IT assets. This ensures that only authorized users can access resources necessary for their job function. This approach requires SAML, SSO, MFA/2FA, and role-based access controls, which are only supported by modern console servers. Modern devices additionally feature advanced security through encryption, signed OS, and tampering detection. This ensures a complete cyber and physical approach to security.
2. Protection Against New Threats
New CVEs and evolving threats can easily take advantage of EOL devices that no longer receive updates. Modern console servers benefit from ongoing support in the form of firmware upgrades and security patches. Upgrading with a security-focused device vendor can drastically shrink the attack surface, by addressing supply chain security risks, codebase integrity, and CVE patching.
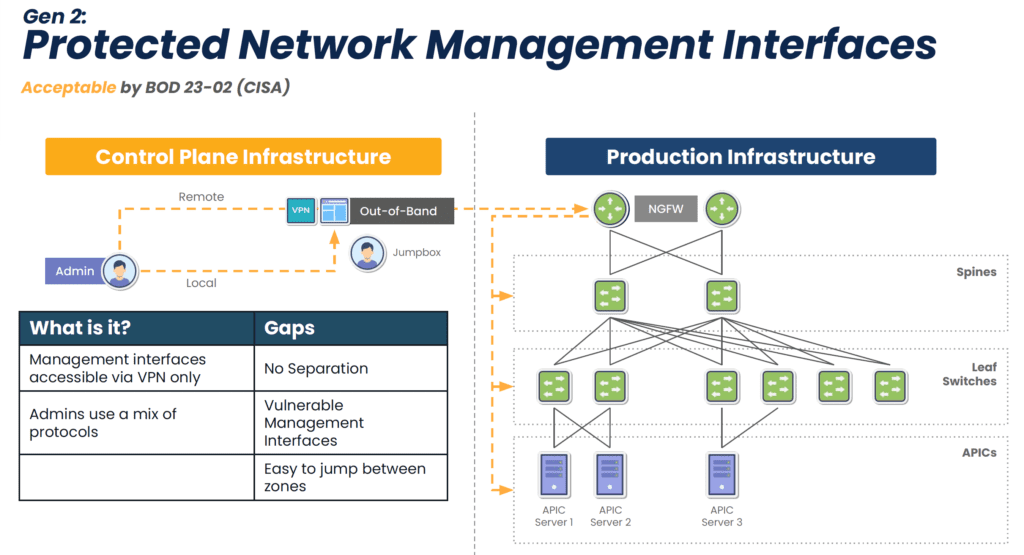
3. Ease of Compliance
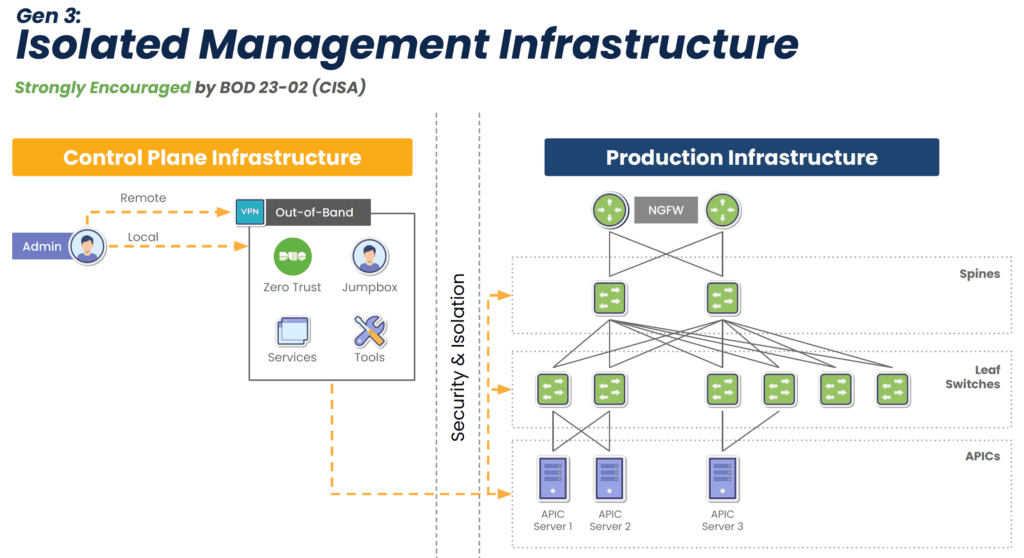
EOL devices lack modern security features, but this isn’t the only reason why they make it difficult or impossible to comply with regulations. They also lack the ability to isolate the control plane from the production network (see Diagram 1 below), meaning attackers can easily move between the two in order to launch ransomware and steal sensitive information. Watchdog agencies and new legislation are stipulating that organizations follow the latest best practice of separating the control plane from production, called Isolated Management Infrastructure (IMI). Modern console servers make this best practice simple to achieve by offering drop-in out-of-band that is completely isolated from production assets (see Diagram 2 below). This means that the organization is always in control of its IT assets and sensitive data.
Diagram 1: Though an acceptable approach, Gen 2 out-of-band lacks isolation and leaves management interfaces vulnerable to the internet.
Diagram 2: Gen 3 out-of-band fully isolates the control plane to guarantee organizations retain control of their IT assets and sensitive info.
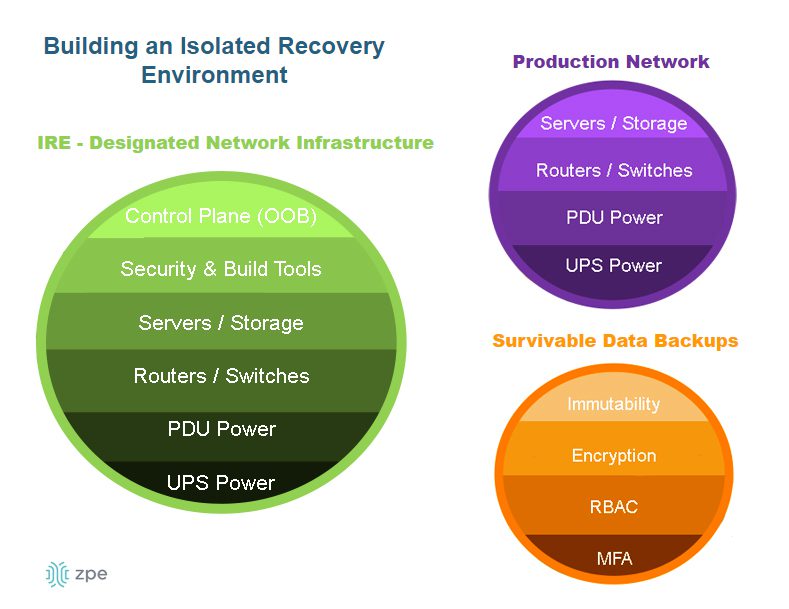
4. Faster Recovery
New console servers are designed to handle more workloads and functions, which eliminates single-purpose devices and shrinks the attack surface. They can also run VMs and Docker containers to host applications. This enables what Gartner calls the Isolated Recovery Environment (IRE) (see Diagram 3 below), which is becoming essential for faster recovery from ransomware. Since the IMI component prohibits attackers from accessing the control plane, admins retain control during an attack. They can use the IMI to deploy their IRE and the necessary applications — remotely — to decommission, cleanse, and restore their infected infrastructure. This means that they don’t have to roll trucks week after week when there’s an attack; they just need to log into their management infrastructure to begin assessing and responding immediately, which significantly reduces recovery times.
Diagram 3: The Isolated Recovery Environment allows for a comprehensive and rapid response to ransomware attacks.
Get a Walkthrough of IMI and IRE
Let’s cover what IMI and IRE would look like in your environment and walk through some outage recovery scenarios. Use the link below to set up a technical discussion.
Visit booth C10 at Cisco Live Amsterdam to chat about IMI, IRE, and replacing end-of-life console servers. You can also catch my 10-minute presentation on Wednesday, February 11 at 1:50pm in the Speakers Corner. I’ll cover From Pilot Projects to Global Rollouts: Why Out-of-Band Management is Crucial for Scaling AI Infrastructure, with more concepts and network diagrams showing how to achieve true resilience. Visit our Cisco Live page below to let me know you’re coming. See you at the show!
On July 19, 2024, CrowdStrike, a leading cybersecurity firm renowned for its advanced endpoint protection and threat intelligence solutions, experienced a significant outage that disrupted operations for many of its clients. This outage, triggered by a software upgrade, resulted in crashes for Windows PCs, creating a wave of operational challenges for banks, airports, enterprises, and organizations worldwide. This blog post explores what transpired during this incident, what caused the outage, and the broader implications for the cybersecurity industry.
What happened?
The incident began on the morning of July 19, 2024, when numerous CrowdStrike customers started reporting issues with their Windows PCs. Users experienced the BSOD (blue screen of death), which is when Windows crashes and renders devices unusable. As the day went on, it became evident that the problem was widespread and directly linked to a recent software upgrade deployed by CrowdStrike.
Timeline of Events
Initial Reports: Early in the day, airports, hospitals, and critical infrastructure operators began experiencing unexplained crashes on their Windows PCs. The issue was quickly reported to CrowdStrike’s support team.
Incident Acknowledgement: CrowdStrike acknowledged the issue via their social media channels and direct communications with affected clients, confirming that they were investigating the cause of the crashes.
Root Cause Analysis: CrowdStrike’s engineering team worked diligently to identify the root cause of the problem. They soon determined that a software upgrade released the previous night was responsible for the crashes.
Mitigation Efforts: Upon isolating the faulty software update, CrowdStrike issued guidance on how to roll back the update and provided patches to fix the issue.
What caused the CrowdStrike outage?
The root cause of the outage was a software upgrade intended to enhance the functionality and security of CrowdStrike’s Falcon sensor endpoint protection platform. However, this upgrade contained a bug that conflicted with certain configurations of Windows PCs, leading to system crashes. Several factors contributed to the incident:
Insufficient Testing: The software update did not undergo adequate testing across all possible configurations of Windows PCs. This oversight meant that the bug was not detected before the update was deployed to customers.
Complex Interdependencies: The incident highlights the complex interdependencies between software components and operating systems. Even minor changes can have unforeseen impacts on system stability.
Rapid Deployment: In the cybersecurity industry, quick responses to emerging threats are crucial. However, the pressure to deploy updates rapidly can sometimes lead to insufficient testing and quality assurance processes.
We need to remember one important fact: whether software is written by humans or AI, there will be mistakes in coding and testing. When an issue slips through the cracks, the customer lab is the last resort to catch it. Usually, this can be done with a controlled rollout, where the IT team first upgrades their lab equipment, performs further testing, puts in place a rollback plan, and pushes the update to a less critical site. But in a cloud-connected SaaS world, the customer is no longer in control. That’s why they sign waivers stating that if such an incident occurs, the company that caused the problem is not liable. Experts are saying the only way to address this challenge is to have an infrastructure that’s designed, deployed, and operated for resilience. We discuss this architecture further down in this article.
How to recover from the CrowdStrike outage
CrowdStrike gives two options for recovering:
Option 1: Reboot in Safe Mode – Reboot the affected device in Safe Mode, locate and delete the file “C-00000291*.sys”, and then restart the device.
Option 2: Re-image – Download and configure the recovery utility to create a new Windows image, add this image to a USB drive, and then insert this USB drive into the target device. The utility will automatically find and delete the file that’s causing the crash.
The biggest obstacle that is costing organizations a lot of time and money is that with either of these recovery methods, IT staff need to be physically present to work on each affected device. They need to go one by one manually remediating via Safe Mode or physically inserting the USB drive. What makes this more difficult is that many organizations use physical and software/management security controls to limit access. Locked device cabinets slow down physical access to devices, and things like role-based access policies and disk encryption can make Safe Mode unusable. Because this outage is affecting more than 8.5 million computers, this kind of work won’t scale efficiently. That’s why organizations are turning to Isolated Management Infrastructure (IMI) and the Isolated Recovery Environment (IRE).
How IMI and IRE help you recover faster
IMI is a dedicated control plane network that’s meant for administration and recovery of IT systems, including Windows PCs affected by the CrowdStrike outage. It uses the concept of out-of-band management, where you deploy a management device that is connected to dedicated management ports of your IT infrastructure (e.g., serial ports, IPMI ports, and other ethernet management ports). IMI also allows you to deploy recovery services for your digital estate that is immutable and near-line when recovery needs to take place.
IMI does not rely at all on the production assets, as it has its own dedicated remote access via WAN links like 4G/5G, and can contain and encrypt recovery keys and tools with zero trust.
IMI gives teams remote, low-level access to devices so they can recover their systems remotely without the need to visit sites. Organizations that employ IMI are able to revert back to a golden image through automation, or deploy bootable tools to all the computers at the site to rescue them without data loss.
The dedicated out-of-band access to serial/IPMI and management ports gives automation software the same abilities as if a physical crash cart was pulled up to the servers. ZPE Systems’ Nodegrid (now a brand of Legrand) enables this architecture as explained next. Using Nodegrid and ZPE Cloud, teams can use either option to recoverfrom the CrowdStrike outage:
Option 1: Reboot in Pre-Execution Environment Software – Nodegrid gives low-level network access to connected Windows as if teams were sitting directly in front of the affected device. This means they can remote-in, reboot to a network image, remote into the booted image, delete the faulty file, and restart the system.
Option 2: Re-image – ZPE Cloud serves as a file repository and orchestration engine. Teams can upload their working Windows image, and then automatically push this across their global fleet of affected devices. This option speeds up recovery times exponentially.
Option 3: – Run Windows Deployment server on the IMI device at the location and re-image servers and workstations if a good backup of the data has been located. This backup can be made available through the IMI after the initial image has been deployed. The IMI can provide dedicated secure access to the InTune services in your M365 cloud, and the backups do not have to transit the entire internet for all workstations at the time, speeding up recovery many times over.
All of these options can be performed at scale or even automated. Server recovery with large backups, although it may take a couple of hours, can be delivered locally and tracked for performance and consistency.
But what about the risk of making mistakes when you have to repeat these tasks? Won’t this cause more damage and data loss?
Any team can make a mistake repeating these recovery tasks over a large footprint, and cause further damage or loss of data, slowing the recovery further. Automated recovery through the IMI addresses this, and can provide reliable recording and reporting to ensure that the restoration is complete and trusted.
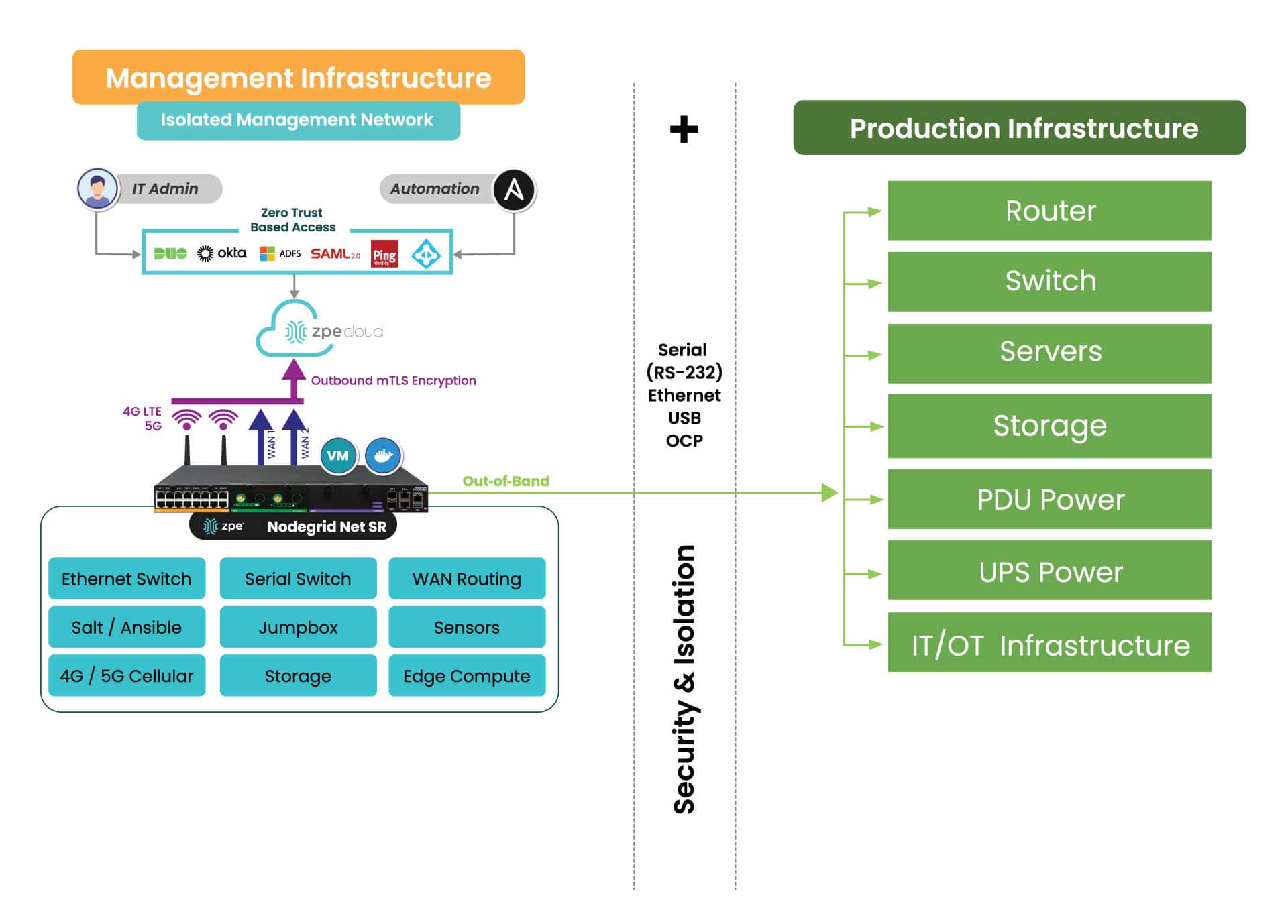
What does IMI look like?
Here’s a simplified view of Isolated Management Infrastructure. You can see that ZPE’s Nodegrid device is needed, which sits beside production infrastructure and provides the platform for hosting all the tools necessary for fast recovery.
What you need to deploy IMI for recovery:
Out-of-band appliance with serial, USB, ethernet interfaces (e.g., ZPE’s Nodegrid Net SR)
Switchable PDU: Legrand Server Tech or Raritan PDU
Windows PXE Boot image
Here’s the order of operations for a faster CrowdStrike outage recovery:
Option 1 – Recover
IMI deployed with a ZPE Nodegrid device that will start Pre-Execution Environment (PXE) which are Windows boot images that the Nodegrid will push to the computers when they boot up
Send recovery keys from Intune to IMI remote storage over ZPE Cloud’s zero trust platform easily available in cloud or air-gapped through Nodegrid Manager
Enable PXE service (automated across entire enterprise) and define the PXE recovery image
Use serial or IP control of power to the computers, or if possible Intel vPro or IPMI capable machines, to reboot all machines
All machines will boot and check in to a control tower for PXE, or be made available to remote into using stored passwords on the PXE environment, Windows AD, or other Privileged Access Management (PAM)
Delete Files
Reboot
Option 2 – Lean re-image
IMI deployed with a Windows Pre-Execution boot image running PXE service
Enable access to cloud and Azure Intune to the IMI remote storage for the local image for the PC
Enable PXE service (automated across entire enterprise) and define the PXE recovery image
Use serial or IP control of power to the computers, or if possible, Intel vPro or IPMI capable machines, to reboot all machines
Machines will boot and check in to Intune either through the IMI or through normal Internet access and finish imaging
Once the machine completes the InTune tasks, InTune will signal backups to come down to the machines. If these backups are offsite, they can be staged on the IMI through backup software running on a virtual machine located on the IMI appliance to speed up recovery and not impede the Internet connection at the remote site
Pre-stage backups onto local storage, push recovery from the virtual machine on the IMI
Option 3 – Windows controlled re-image
Windows Deployment Server (WDS) installed as a virtual machine running on the IMI appliance (offline to prevent issues or online but under a slowed deployment cycle in case there was an issue)
Send recovery keys from Intune to IMI remote storage over a zero trust interface in cloud or air-gapped
Use serial or IP control of power to the computers, or if possible, Intel vPro or IPMI capable machines, to reboot all machines
Machines will boot and check in to the WDS for re-imaging
Machines will boot and check in to Intune either through the IMI or through normal Internet access and finish imaging
Once the machine completes the InTune tasks, InTune will signal backups to come down to the machines. If these backups are offsite, they can be staged on the IMI through backup software running on a virtual machine located on the IMI appliance to speed up recovery and not impede the Internet connection at the remote site
Pre-stage backups onto local storage, push recovery from the virtual machine on the IMI
Deploy IMI to avoid the next outage
Get in touch for help choosing the right size IMI deployment for your organization. Nodegrid and ZPE Cloud are the drop-in solution to recovering from outages, with plenty of device options to fit any budget and environment size. Contact ZPE Sales now or download the blueprint to help you begin implementing IMI.
Edge computing delivers data processing and analysis capabilities to the network’s “edge,” at remote sites like branch offices, warehouses, retail stores, and manufacturing plants. It involves deploying computing resources and lightweight applications very near the devices that generate data, reducing the distance and number of network hops between them. In doing so, edge computing reduces latency and bandwidth costs while mitigating risk, enhancing edge resilience, and enabling real-time insights. This blog discusses the five biggest benefits of edge computing, providing examples and additional resources for companies beginning their edge journey. .
5 benefits of edge computing
Edge Computing:
Description
Reduces latency
Leveraging data at the edge reduces network hops and latency to improve speed and performance.
Mitigates risk
Keeping data on-site at distributed edge locations reduces the chances of interception and limits the blast radius of breaches.
Lowers bandwidth costs
Reducing edge data transmissions over expensive MPLS lines helps keep branch costs low.
Enhances edge resilience
Analyzing data on-site ensures that edge operations can continue uninterrupted during ISP outages and natural disasters.
Enables real-time insights
Eliminating off-site processing allows companies to use and extract value from data as soon as it’s generated.
1. Reduces latency
Edge computing leverages data on the same local network as the devices that generate it, cutting down on edge data transmissions over the WAN or Internet. Reducing the number of network hops between devices and applications significantly decreases latency, improving the speed and performance of business intelligence apps, AIOps, equipment health analytics, and other solutions that use edge data.
Some edge applications run on the devices themselves, completely eliminating network hops and facilitating real-time, lag-free analysis. For example, an AI-powered surveillance application installed on an IoT security camera at a walk-up ATM can analyze video feeds in real-time and alert security personnel to suspicious activity as it occurs.
Edge computing mitigates security and compliance risks by distributing an organization’s sensitive data and reducing off-site transmission. Large, centralized data stores in the cloud or data center are prime targets for cybercriminals because the sheer volume of data involved increases the chances of finding something valuable. Decentralizing data in much smaller edge storage solutions makes it harder for hackers to find the most sensitive information and also limits how much data they can access at one time.
Keeping data at the edge also reduces the chances of interception in transit to cloud or data center storage. Plus, unlike in the cloud, an organization maintains complete control over who and what has access to sensitive data, aiding in compliance with regulations like the GDPR and PCI DSS 4.0. .
Many organizations use MPLS (multi-protocol label switching) links to securely connect edge sites to the enterprise network. MPLS bandwidth is much more expensive than regular Internet lines, which makes transmitting edge data to centralized data processing applications extremely costly. Plus, it can take months to provision MPLS at a new site, delaying launches and driving up overhead expenses.
Edge computing significantly reduces MPLS bandwidth utilization by running data-hungry applications on the local network, reserving the WAN for other essential traffic. Combining edge computing with SD-WAN (software-defined wide area networking) and SASE (secure access service edge) technologies can markedly decrease the reliance on MPLS links, allowing organizations to accelerate branch openings and see faster edge ROIs. .
Since edge computing applications run on the same LAN as the devices generating data, they can continue to function even if the site loses Internet access due to an ISP outage, natural disaster, or other adverse event. This also allows uninterrupted edge operations in locations with inconsistent (or no) Internet coverage, like offshore oil rigs, agricultural sites, and health clinics in isolated rural communities. Edge computing ensures that organizations don’t miss any vital health or safety alerts and facilitates technological innovation using AI and other data analytics tools in challenging environments..
.
Sending data from the edge to a cloud or on-premises data lake for processing, transformation, and ingestion by analytics or AI/ML tools takes time, preventing companies from acting on insights at the moment when they’re most useful. Edge computing applications start using data as soon as it’s generated, so organizations can extract value from it right away. For example, a retail store can use edge computing to gain actionable insights on purchasing activity and customer behavior in real-time, so they can move in-demand products to aisle endcaps or staff extra cashiers as needed. .
To learn more about the potential uses of edge computing technology, read Edge Computing Examples.
Simplify your edge computing deployment with Nodegrid
The best way to achieve the benefits of edge computing described above without increasing management complexity or hardware overhead is to use consolidated, vendor-neutral solutions to host, connect, and secure edge workloads. For example, the Nodegrid Gate SR from ZPE Systems delivers an entire stack of edge networking and infrastructure management technologies in a single, streamlined device. The open, Linux-based Nodegrid OS supports VMs and containers for third-party applications, with an Nvidia Jetson Nano card capable of running AI workloads alongside non-AI data analytics for ultimate efficiency.
Improve your edge computing deployment with Nodegrid
Nodegrid consolidates edge computing deployments to improve operational efficiency without sacrificing performance or functionality. Schedule a free demo to see Nodegrid in action.
The current cyber threat landscape is daunting, with attacks occurring so frequently that security experts recommend operating under the assumption that your network is already breached. Major cyber attacks – and the disruptions they cause – frequently make news headlines. The MGM hack, LendingTree breach, and CDK Global attack are just a few examples that affected thousands of people per incident and now have many organizations rethinking their resilience strategies.
The zero trust security methodology outlines the best practices for limiting the blast radius of a successful breach by preventing malicious actors from moving laterally through the network and accessing the most valuable or sensitive resources. Many organizations have already begun their zero trust journey by implementing role-based access controls (RBAC), multi-factor authentication (MFA), and other security solutions, but still struggle with coverage gaps that result in ransomware attacks and other disruptive breaches. This blog provides advice for improving your zero trust security posture with a multi-layered strategy that mitigates weaknesses for complete coverage.
Use edge-centric solutions like SASE to extend zero trust policies and controls to remote network traffic, devices, and users.
Gain a full understanding of your protect surface
Many security strategies focus on defending the network’s “attack surface,” or all the potential vulnerabilities an attacker could exploit to breach the network. However, zero trust is all about defending the “protect surface,” or all the data, assets, applications, and services that an attacker could potentially try to access. The key difference is that zero trust doesn’t ask you to try to cover any possible weakness in a network, which is essentially impossible. Instead, it wants you to look at the resources themselves to determine what has the most value to an attacker, and then implement security controls that are tailored accordingly.
Gaining a full understanding of all the resources on your network can be extraordinarily challenging, especially with the proliferation of SaaS apps, mobile devices, and remote workforces. There are automated tools that can help IT teams discover all the data, apps, and devices on the network. Application discovery and dependency mapping (ADDM) tools help identify all on-premises software and third-party dependencies; cloud application discovery tools do the same for cloud-hosted apps by monitoring network traffic to cloud domains. Sensitive data discovery tools scan all known on-premises or cloud-based resources for personally identifiable information (PII) and other confidential data, and there are various device management solutions to detect network-connected hardware, including IoT devices. ,
Tip: This step can’t be completed one time and then forgotten – teams should execute discovery processes on a regular, scheduled basis to limit gaps in protection.
Micro-segment your network with micro-perimeters
Micro-segmentation is a cornerstone of zero-trust networks. It involves logically separating all the data, applications, assets, and services according to attack value, access needs, and interdependencies. Then, teams implement granular security policies and controls tailored to the needs of each segment, establishing what are known as micro-perimeters. Rather than trying to account for every potential vulnerability with one large security perimeter, teams can just focus on the tools and policies needed to cover the specific vulnerabilities of a particular micro-segment.
Network micro-perimeters help improve your zero trust security posture with:
Granular access policies granting the least amount of privileges needed for any given workflow. Limiting the number of accounts with access to any given resource, and limiting the number of privileges granted to any given account, significantly reduces the amount of damage a compromised account (or malicious actor) is capable of inflicting.
Targeted security controls addressing the specific risks and vulnerabilities of the resources in a micro-segment. For example, financial systems need stronger encryption, strict data governance monitoring, and multiple methods of trust verification, whereas an IoT lighting system requires simple monitoring and patch management, so the security controls for these micro-segments should be different.
Trust verification using context-aware policies to catch accounts exhibiting suspicious behavior and prevent them from accessing sensitive resources. If a malicious outsider compromises an authorized user account and MFA device – or a disgruntled employee uses their network privileges to harm the company – it can be nearly impossible to prevent data exposure. Context-aware policies can stop a user from accessing confidential resources outside of typical operating hours, or from unfamiliar IP addresses, for example. Additionally, user entity and behavior analytics (UEBA) solutions use machine learning to detect other abnormal and risky behaviors that could indicate malicious intent.
Isolate and defend your management infrastructure
For zero trust to be effective, organizations must apply consistently strict security policies and controls to every component of their network architecture, including the management interfaces used to control infrastructure. Otherwise, a malicious actor could use a compromised sysadmin account to hijack the control plane and bring down the entire network.
According to a recent CISA directive, the best practice is to isolate the network’s control plane so that management interfaces are inaccessible from the production network. Many new cybersecurity regulations, including PCI DSS 4.0, DORA, NIS2, and the CER Directive, also either strongly recommend or require management infrastructure isolation.
Isolated management infrastructure (IMI) prevents compromised accounts, ransomware, and other threats from moving laterally to or from the production LAN. It gives teams a safe environment to recover from ransomware or other cyberattacks without risking reinfection, which is known as an isolated recovery environment (IRE). Management interfaces and the IRE should also be protected by granular, role-based access policies, multi-factor authentication, and strong hardware roots of trust to further mitigate risk.
The easiest and most secure way to implement IMI is with Gen 3 out-of-band (OOB) serial console servers, like the Nodegrid solution from ZPE Systems. These devices use alternative network interfaces like 5G/4G LTE cellular to ensure complete isolation and 24/7 management access even during outages. They’re protected by hardware security features like TPM 2.0 and GPS geofencing, and they integrate with zero trust solutions like identity and access management (IAM) and UEBA to enable consistent policy enforcement.
Defend your cloud resources
The vast majority of companies host some or all of their workflows in the cloud, which significantly expands and complicates the attack surface while making it more challenging to identify and defend the protect surface. Some organizations also lack a complete understanding of the shared responsibility model for varying cloud services, increasing the chances of coverage gaps. Additionally, many orgs struggle with “shadow IT,” which occurs when individual business units implement cloud applications without going through onboarding, preventing security teams from applying zero trust controls.
The first step toward improving your zero trust security posture in the cloud is to ensure you understand where your cloud service provider’s responsibilities end and yours begin. For instance, most SaaS providers handle all aspects of security except IAM and data protection, whereas IaaS (Infrastructure-as-a-Service) providers are only responsible for protecting their physical and virtual infrastructure.
It’s also vital that security teams have a complete picture of all the cloud services in use by the organization and a way to deploy and enforce zero trust policies in the cloud. For example, a cloud access security broker (CASB) is a solution that discovers all the cloud services in use by an organization and allows teams to monitor and manage security for the entire cloud architecture. A CASB provides capabilities like data governance, malware detection, and adaptive access controls, so organizations can protect their cloud resources with the same techniques used in the on-premises environment. .
Example Cloud Access Security Broker Capabilities
Visibility
Compliance
Threat protection
Data security
Cloud service discovery
Monitoring and reporting
User authentication and authorization
Data governance and loss prevention
Malware (e.g., virus, ransomware) detection
User and entity behavior analytics (UEBA)
Data encryption and tokenization
Data leak prevention
Extend zero trust to the edge
Modern enterprise networks are highly decentralized, with many business operations taking place at remote branches, Internet of Things (IoT) deployment sites, and end-users’ homes. Extending security controls to the edge with on-premises zero trust solutions is very difficult without backhauling all remote traffic through a centralized firewall, which creates bottlenecks that affect performance and reliability. Luckily, the market for edge security solutions is rapidly growing and evolving to help organizations overcome these challenges.
Security Access Service Edge (SASE) is a type of security platform that delivers core capabilities as a managed, typically cloud-based service for the edge. SASE uses software-defined wide area networking (SD-WAN) to intelligently and securely route edge traffic through the SASE tech stack, allowing the application and enforcement of zero trust controls. In addition to CASB and next-generation firewall (NGFW) features, SASE usually includes zero trust network access (ZTNA), which offers VPN-like functionality to connect remote users to enterprise resources from outside the network. ZTNA is more secure than a VPN because it only grants access to one app at a time, requiring separate authorization requests and trust verification attempts to move to different resources.
Accelerating the zero trust journey
Zero trust is not a single security solution that you can implement once and forget about – it requires constant analysis of your security posture to identify and defend weaknesses as they arise. The best way to ensure adaptability is by using vendor-agnostic platforms to host and orchestrate zero trust security. This will allow you to add and change security services as needed without worrying about interoperability issues.
For example, the Nodegrid platform from ZPE Systems includes vendor-neutral serial consoles and integrated branch services routers that can host third-party software such as SASE and NGFWs. These devices also provide Gen 3 out-of-band management for infrastructure isolation and network resilience. Nodegrid protects management interfaces with strong hardware roots-of-trust, embedded firewalls, SAML 2.0 integrations, and other zero trust security features. Plus, with Nodegrid’s cloud-based or on-premises management platform, teams can orchestrate networking, infrastructure, and security workflows across the entire enterprise architecture.
Improve your zero trust security posture with Nodegrid
Using Nodegrid as the foundation for your zero trust network infrastructure ensures maximum agility while reducing management complexity. Watch a Nodegrid demo to learn more.
ZPE Systems delivers innovative solutions to simplify infrastructure managment at the datacenter, branch, and edge.
Learn how our Zero Pain Ecosystem can solve your biggest network orchestration pain points.

")






")