Best Network Performance Monitoring Tools

Comparing best network performance monitoring tools
Disclaimer: This comparison was written by a 3rd party in collaboration with ZPE Systems using data gathered from publicly available data sheets and admin guides, as of 10/20/2023. Please email us if you have corrections or edits, or want to review additional attributes: Matrix@zpesystems.com
SolarWinds Network Performance Monitor (NPM)
The Network Performance Monitor (NPM) is part of the SolarWinds Orion platform of integrated products. This mature and richly featured monitoring software is delivered as a cloud-based service and can observe SaaS (software as a service), cloud, hybrid cloud, and on-premises infrastructure. With advanced features like deep packet inspection (DPI), WAN optimization monitoring, automatic network mapping, and automated diagnostic tools, SolarWinds NPM is meant to be a complete, enterprise-grade observability solution. As part of the Orion platform, it’s also extensible with other products from the SolarWinds ecosystem, such as a Network Configuration Manager. As an enterprise solution, SolarWinds NPM comes with a high price tag that grows even larger as additional monitoring agents are added, limiting the scalability. Another important factor to consider is that SolarWinds recently suffered a high-profile hack that compromised thousands of customers, so there are security risks involved in trusting the Orion supply chain. Additionally, despite a large library of integrations, SolarWinds is a closed ecosystem that doesn’t work well with 3rd-party tools or custom scripts.
Kentik
Kentik is an end-to-end network observability platform for cloud, multi-cloud, hybrid cloud, SaaS, and data center infrastructure. In addition to network performance monitoring, the platform includes monitoring solutions for SaaS application performance and SD-WAN performance. Other observability features include SaaS uptime monitoring, AI-driven insights and alerts, network security monitoring, and QoE (Quality of Experience) monitoring. Kentik also recently launched a Kubernetes network monitoring solution called Kentik Kube that provides end-to-end cluster visibility. Overall, Kentik is a powerful network observability platform that includes many of its most innovative features in its “Essentials” and “Pro” pricing packages, providing a lot of bang for your buck. The downside is that you can’t subscribe to features individually and must purchase a whole package, meaning you could end up paying for features you don’t need. Because Kentik is not a large vendor, its customer service may be slow to respond in some cases. Additionally, although Kentik does have a large library of integrations, it is not a vendor-neutral platform.
ThousandEyes
ThousandEyes is a digital experience monitoring platform primarily focused on network and application synthetic testing, end-user performance monitoring, and ISP Internet monitoring for SaaS, cloud, and on-premises networks. Additionally, ThousandEyes is part of the Cisco family and can be used to monitor and optimize Cisco SD-WAN architectures. Across its family of observability products, ThousandEyes includes features like wireless network visibility, SaaS performance visualizations, cloud application outage detection, and SD-WAN performance forecasting. The major advantage of the ThousandEyes platform is that it provides true end-to-end visibility of the entire service delivery chain, including end-user device performance and third-party provider availability. One downside is the endpoint agent-based monitoring solution requires on-premises VMs to run, which can be cumbersome to maintain and limits scalability. The pricing is expensive compared to similar solutions, and you may have to combine products to get all the features you need. Additionally, ThousandEyes is not a vendor-neutral platform and has a relatively small library of integrations.
Conclusion
Each of the solutions on this list has advantages that make it well-suited to certain environments, as well as limitations to consider. Solarwinds NPM is part of a large ecosystem of observability and management solutions that includes advanced features like DPI, but it’s suffering from a major security incident and has a closed ecosystem. Kentik packs a lot of innovative, AI-driven monitoring capabilities into its platform offerings, but its pricing tiers are inflexible, and it doesn’t have the large, enterprise-grade support team of its larger competitors. ThousandEyes provides end-to-end visibility of the entire service delivery chain and works seamlessly with Cisco DNA software, but it has a steep learning curve and a limited library of integrations.
How to run the best network performance monitoring tools
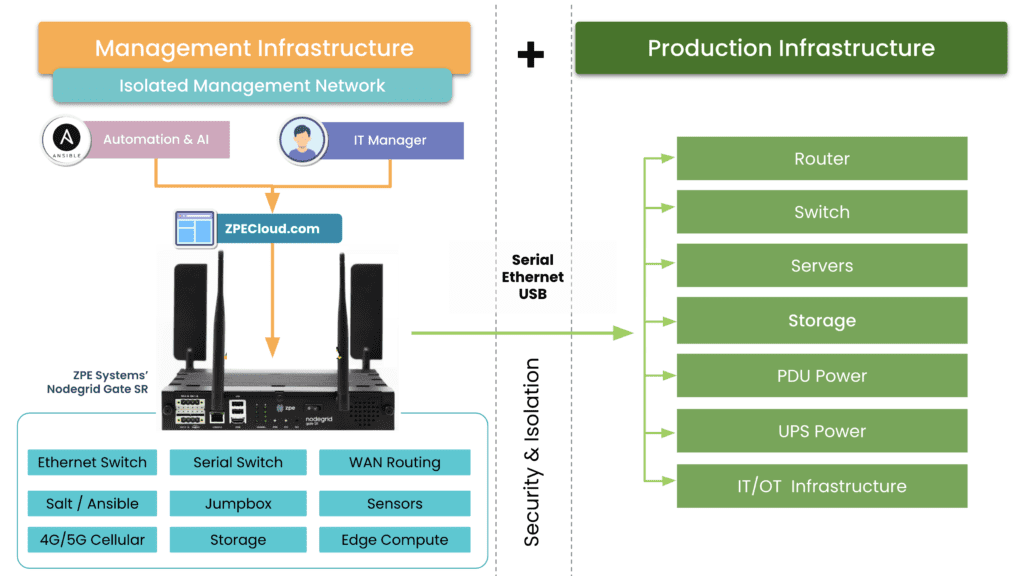
Most network performance monitoring tools – even cloud-based SaaS offerings – communicate with endpoint agents using software deployed on VMs (virtual machines) running on-premises in each business location. Running these VMs on fully provisioned servers or PCs is expensive, but deploying them on NUCs is highly insecure, especially as organizations scale out with distributed branches and edge computing sites. What’s needed is a consolidated hardware solution that combines critical branch, edge, and data center networking functionality with vendor-neutral VM and application hosting, such as the Nodegrid platform from ZPE Systems. Nodegrid’s serial switches and network edge routers run the open, Linux-based Nodegrid OS, which can host your choice of third-party software – including Docker containers – for network performance monitoring, SD-WAN, security, automation, and more. Nodegrid’s versatile, modular hardware solutions also provide out-of-band (OOB) management access to critical remote infrastructure and monitoring solutions, giving teams a lifeline to recover from outages and ransomware attacks. Nodegrid uses innovative, enterprise-grade security features like Secure Boot, self-encrypted disk, and two-factor authentication (2FA), and its onboard software is frequently patched for vulnerabilities to defend against a breach. Deploying Nodegrid at each business site consolidates your network to reduce hardware overhead, streamlining management and enabling easy scalability.
Deploy the best network performance monitoring tools with Nodegrid
Reach out to ZPE Systems to see a demo of how the best network performance monitoring tools run on the Nodegrid platform.
Contact Us



")

