Edge Management and Orchestration
")
Organizations prioritizing digital transformation by adopting IoT (Internet of Things) technologies generate and process an unprecedented amount of data. Traditionally, the systems used to process that data live in a centralized data center or the cloud. However, IoT devices are often deployed around the edges of the enterprise in remote sites like retail stores, manufacturing plants, and oil rigs. Transferring so much data back and forth creates a lot of latency and uses valuable bandwidth. Edge computing solves this problem by moving processing units closer to the sources that generate the data.
IBM estimates there are over 15 billion edge devices already in use. While edge computing has rapidly become a vital component of digital transformation, many organizations focus on individual use cases and lack a cohesive edge computing strategy. According to a recent Gartner report, the result is what’s known as “edge sprawl”: many individual edge computing solutions deployed all over the enterprise without any centralized control or visibility. Organizations with disjointed edge computing deployments are less efficient and more likely to hit roadblocks that stifle digital transformation.
The report provides guidance on building an edge computing strategy to combat sprawl, and the foundation of that strategy is edge management and orchestration (EMO). Below, this post summarizes the key findings from the Gartner report and discusses some of the biggest edge computing challenges before explaining how to solve them with a centralized EMO platform.
Table of Contents |
Key findings from the Gartner report
Many organizations already use edge computing technology for specific projects and use cases – they have an individual problem to solve, so they deploy an individual solution. Since the stakeholders in these projects usually aren’t architects, they aren’t building their own edge computing machines or writing software for them. Typically, these customers buy pre-assembled solutions or as-a-service offerings that meet their specific needs.
However, a piecemeal approach to edge computing projects leaves organizations with disjointed technologies and processes, contributing to edge sprawl and shadow IT. Teams can’t efficiently manage or secure all the edge computing projects occurring in the enterprise without centralized control and visibility. Gartner urges I&O (infrastructure & operations) leaders to take a more proactive approach by developing a comprehensive edge computing strategy encompassing all use cases and addressing the most common challenges.
Edge computing challenges
Gartner identifies six major edge computing challenges to focus on when developing an edge computing strategy:
Let’s discuss these challenges and their solutions in greater depth.
- Enabling extensibility – Many organizations deploy purpose-built edge computing solutions for their specific use case and can’t adapt when workloads change or grow. The goal is to attempt to predict future workloads based on planned initiatives and create an edge computing strategy that leaves room for that growth. However, no one can really predict the future, so the strategy should account for unknowns by utilizing common, vendor-neutral technologies that allow for expansion and integration.
- Extracting value from edge data – The generation of so much IoT and sensor data gives organizations the opportunity to extract additional value in the form of business insights, predictive analysis, and machine learning training. Quickly extracting that value is challenging when most data analysis and AI applications still live in the cloud. To effectively harness edge data, organizations should look for ways to deploy artificial intelligence training and data analytics solutions alongside edge computing units.
- Governing edge data – Edge computing deployments often have more significant data storage constraints than central data centers, so quickly distinguishing between valuable data and destroyable junk is critical to edge ROIs. With so much data being generated, it’s often challenging to make this determination on the fly, so it’s important to address data governance during the planning process. There are automated data governance solutions that can help, but these must be carefully configured and managed to avoid data loss.
- Supporting edge-native applications – Edge applications aren’t just data center apps lifted and shifted to the edge; they’re designed for edge computing from the bottom up. Like cloud-native software, edge apps often use containers, but clustering and cluster management are different beasts outside the cloud data center. The goal is to deploy platforms that support edge-native applications without increasing the technical debt, which means they should use familiar container management technologies (like Docker) and interoperate with existing systems (like OT applications and VMs).
- Securing the edge – Edge deployments are highly distributed in locations that may lack many physical security features in a traditional data center, such as guarded entries and biometric locks, which adds risk and increases the attack surface. Organizations must protect edge computing nodes with a multi-layered defense that includes hardware security (such as TPM), frequent patches, zero-trust policies, strong authentication (e.g., RADIUS and 2FA), and network micro-segmentation.
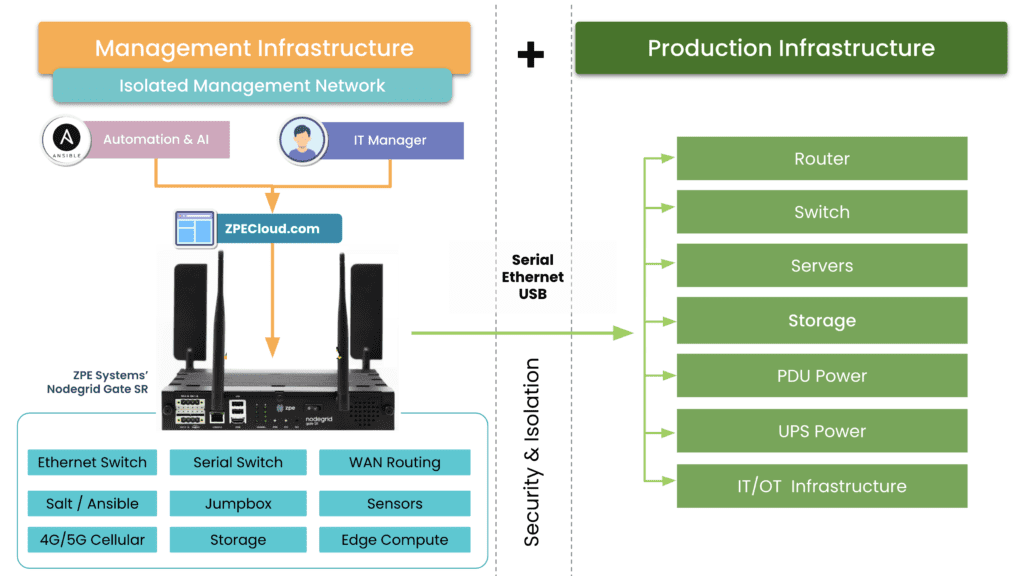
- Edge management and orchestration – Moving computing out of the climate-controlled data center creates environmental and power challenges that are difficult to mitigate without an on-site technical staff to monitor and respond. When equipment failure, configuration errors, or breaches take down the network, remote teams struggle to meet resilience requirements to keep business operations running 24/7. The sheer number and distribution area of edge computing units make them challenging to manage efficiently, increasing the likelihood of mistakes, issues, or threat indicators slipping between the cracks. Addressing this challenge requires centralized edge management and orchestration (EMO) with environmental monitoring and out-of-band (OOB) connectivity.
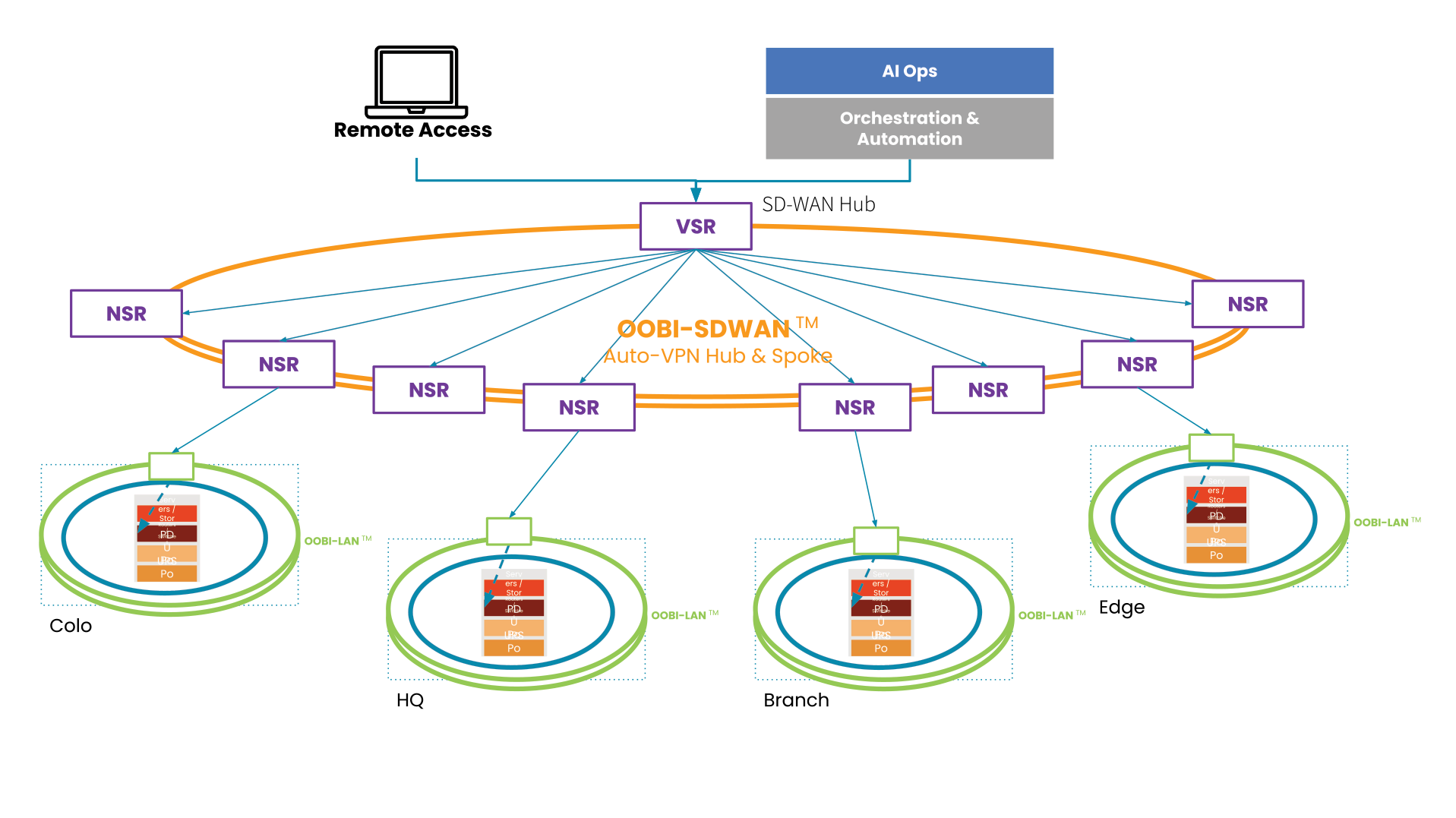
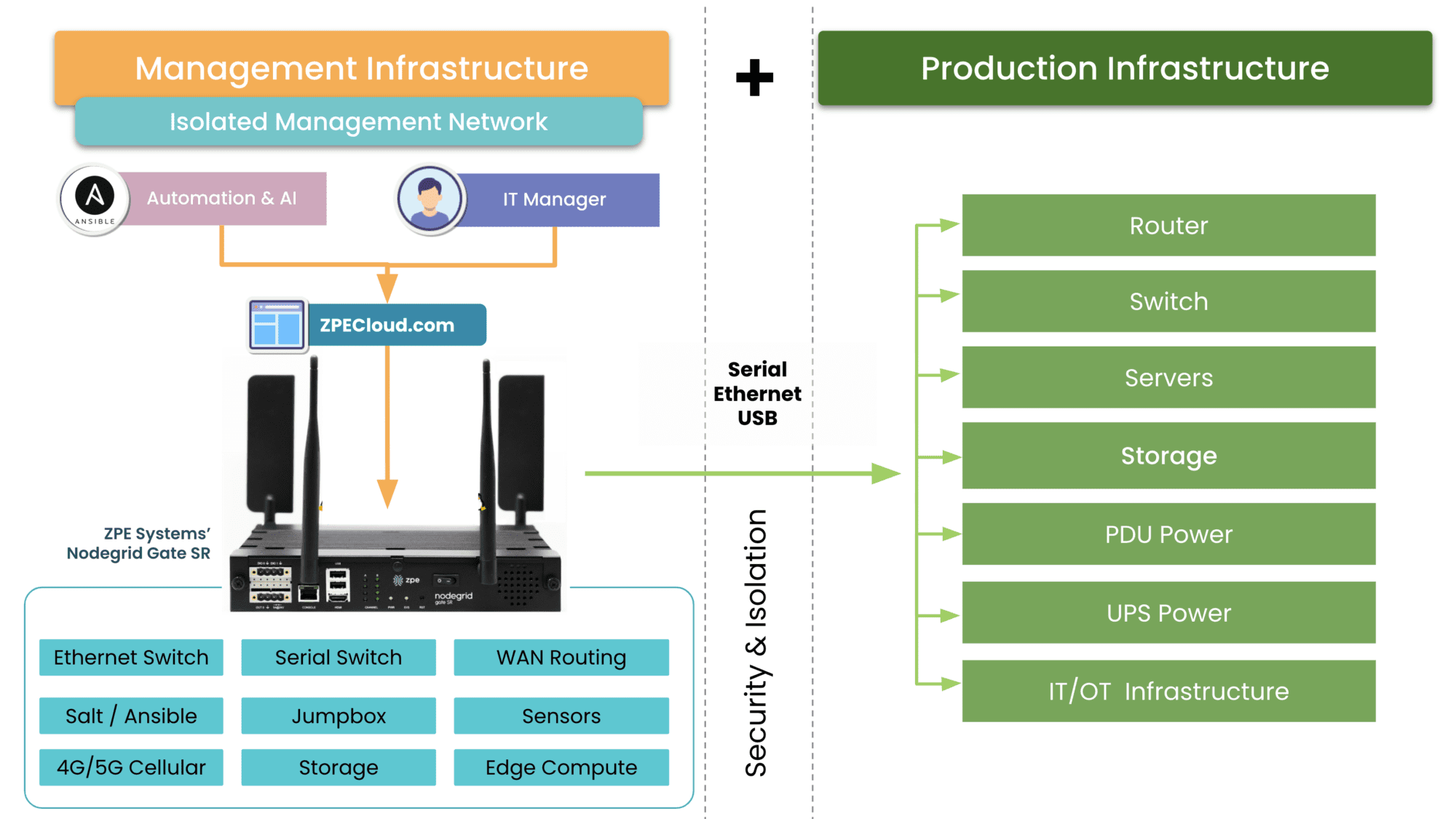
A centralized EMO platform gives administrators a single-pane-of-glass view of all edge deployments and the supporting infrastructure, streamlining management workflows and serving as the control panel for automation, security, data governance, cluster management, and more. The EMO must integrate with the technologies used to automate edge management workflows, such as zero-touch provisioning (ZTP) and configuration management (e.g., Ansible or Chef), to help improve efficiency while reducing the risk of human error. Integrating environmental sensors will help remote technicians monitor heat, humidity, airflow, and other conditions affecting critical edge equipment’s performance and lifespan. Finally, remote teams need OOB access to edge infrastructure and computing nodes, so the EMO should use out-of-band serial console technology that provides a dedicated network path that doesn’t rely on production resources.
Gartner recommends focusing your edge computing strategy on overcoming the most significant risks, challenges, and roadblocks. An edge management and orchestration (EMO) platform is the backbone of a comprehensive edge computing strategy because it serves as the hub for all the processes, workflows, and solutions used to solve those problems.
| Learn more about zero trust on the control plane |
Edge management and orchestration (EMO) with Nodegrid
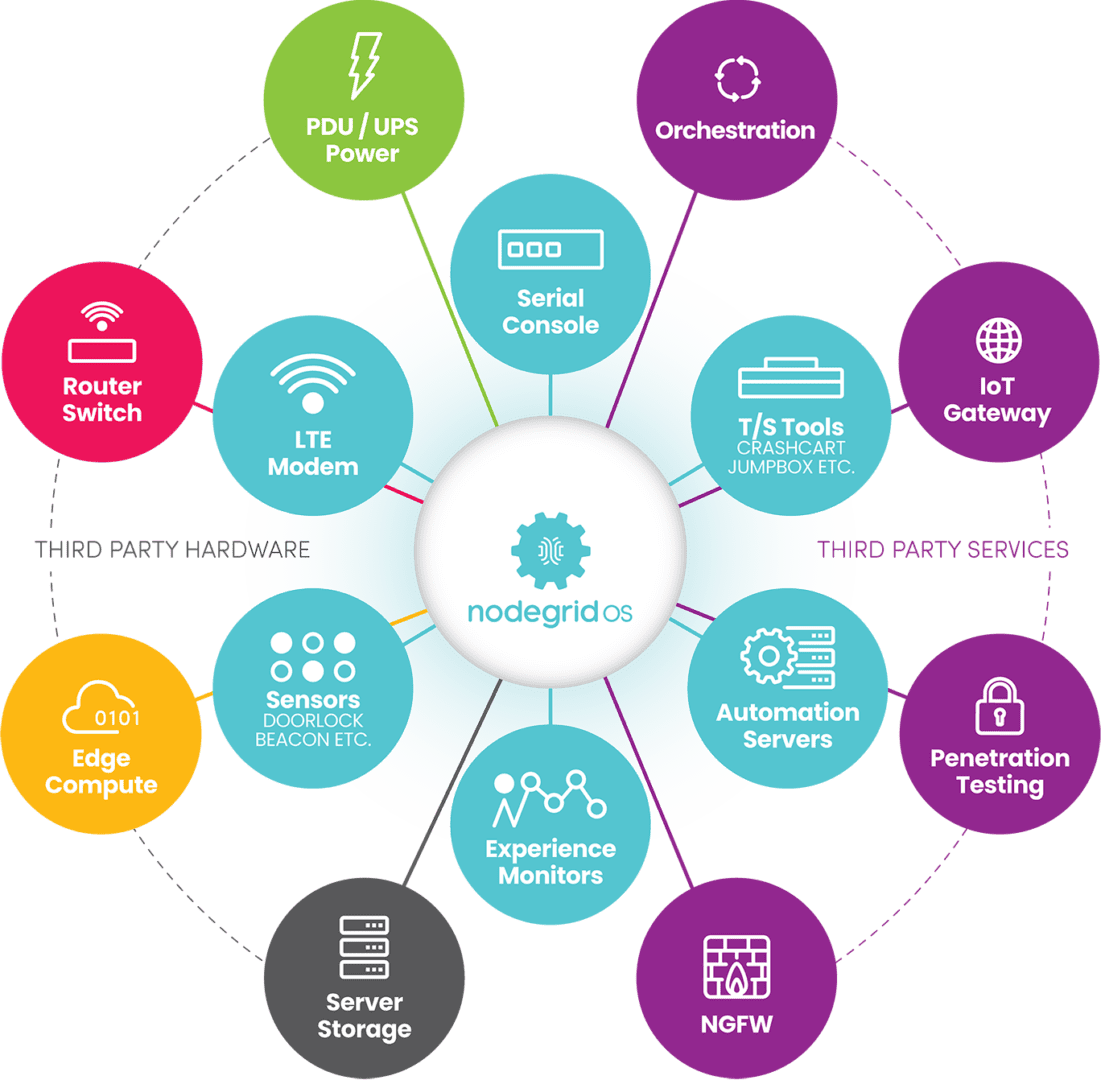
Nodegrid is a vendor-neutral edge management and orchestration (EMO) platform from ZPE Systems. Nodegrid uses Gen 3 out-of-band technology that provides 24/7 remote management access to edge deployments while freely interoperating with third-party applications for automation, security, container management, and more. Nodegrid environmental sensors give teams a complete view of temperature, humidity, airflow, and other factors from anywhere in the world and provide robust logging to support data-driven analytics.
The open, Linux-based Nodegrid OS supports direct hosting of containers and edge-native applications, reducing the hardware overhead at each edge deployment. You can also run your ML training, AIOps, data governance, or data analytics applications from the same box to extract more value from your edge data without contributing to sprawl.
In addition to hardware security features like TPM and geofencing, Nodegrid supports strong authentication like 2FA, integrates with leading zero-trust providers like Okta and PING, and can run third-party next-generation firewall (NGFW) software to streamline deployments further.
The Nodegrid platform brings all the components of your edge computing strategy under one management umbrella and rolls it up with additional core networking and infrastructure management features. Nodegrid consolidates edge deployments and streamlines edge management and orchestration, providing a foundation for a Gartner-approved edge computing strategy.
Want to learn more about how Nodegrid can help you overcome your biggest edge computing challenges?
Contact ZPE Systems for a free demo of the Nodegrid edge management and orchestration platform.



 before discussing 5G RAN challenges, solutions, and use cases.")