Network Disaster Recovery Plan Checklist

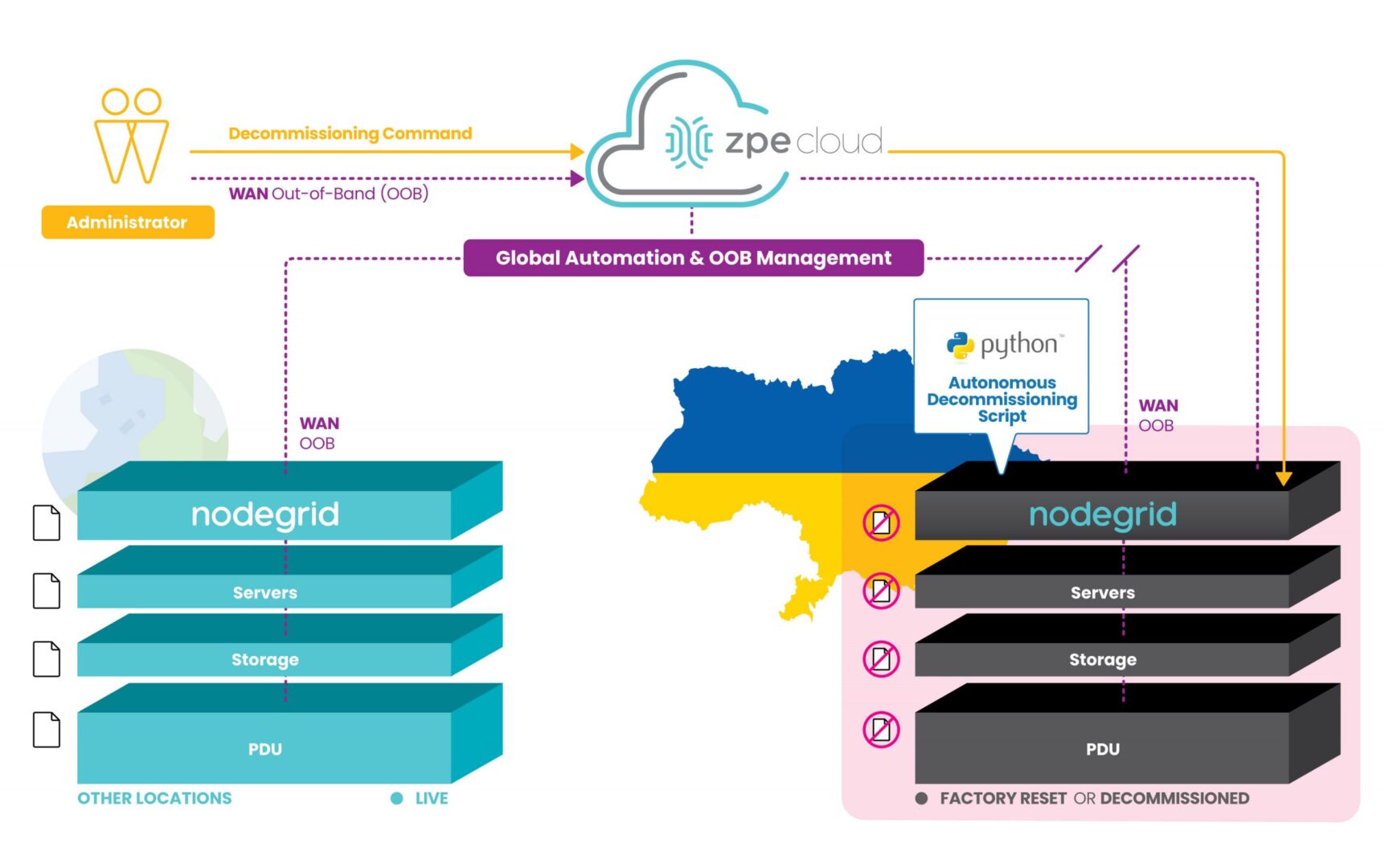
Your organization may feel secure now, but a disaster could occur at any moment. For example, the war in Ukraine took the world by surprise and left many organizations scrambling to protect and recover critical infrastructure, applications, and data from Ukrainian facilities.
To ensure you’re ready to weather any crisis, you need a robust disaster recovery (DR) plan that accounts for many different scenarios and challenges. This blog provides a network disaster recovery plan checklist to help you establish protocols for protecting your systems, data, and business.
Your network disaster recovery plan checklist
Identify potential disasters
There’s no one-size-fits-all disaster recovery plan—recovering from ransomware is a much different process than recovering from a tornado. You need to determine what types of disasters are most likely to occur and assess each scenario’s individual risk to your facilities, systems, and data.
Network disaster recovery plan checklist:
□ Make a list of disasters (natural, man-made, and otherwise) that could pose a threat to your organization.
□ Briefly describe what each disaster would look like and how they would impact your company.
□ Prioritize your list of disasters based on how likely they are to occur.
Establish the potential impact of a disaster
You should conduct what’s known as a business impact analysis to define how each of these disaster scenarios would impact your organization.
Network disaster recovery plan checklist:
□ Determine which business processes, systems, and data are affected by each disaster scenario on your list.
★ Tip: Don’t forget your cloud and edge resources
□ Outline precisely how operations will be disrupted by losing or disrupting critical business services.
□ Analyze the impact on every aspect of your organization, including productivity, revenue, reputation, etc.
□ Calculate the estimated cost of each disaster, both in terms of lost revenue and recovery costs.
Create recovery protocols
What steps do you need to take to recover from a disaster, and what technology will you use to do it? You should create specific recovery protocols for each high-priority disaster scenario on your list.
Network disaster recovery plan checklist:
□ Make a detailed list of all recovery procedures and who is responsible for each.
□ Make a list of all the technology that will be leveraged in a disaster (e.g., backup data solutions, network failover)
□ Outline instructions for every step in every recovery procedure, including branching recovery paths in case one or more of your recovery systems is unavailable.
Set expectations and timelines
Once you know how you’ll recover from each potential disaster scenario, you need to determine the realistic timeline for recovery. This timeline should be based on data and information from the individual team members involved in recovery efforts, as well as the business impact analysis you performed earlier.
Network disaster recovery plan checklist:
□ Define how long it would take to complete the recovery procedures for each disaster.
□ Compare this to the business impact analysis showing the estimated cost of a disaster to see if your recovery protocols will work quickly enough to prevent unacceptable losses.
★ Tip: If your recovery protocols are too time-consuming, you may need to return to step 3 and re-evaluate your technologies and procedures.
Define individual roles and responsibilities
When disaster strikes, it’s crucial to take action immediately. This is only possible if everyone involved in disaster recovery knows their responsibilities clearly and who is in charge of decision-making.
Network disaster recovery plan checklist:
□ Identify disaster recovery team members and determine how they should be contacted when there’s an emergency.
□ List the stakeholders who must be kept updated on the recovery status.
□ Assign a person (or team) responsible for monitoring the business impact of an ongoing disaster.
□ Assign people at each site who will decide on evacuation or relocation of staff and assets.
□ Identify the people who have access to secure systems and/or can grant access to others.
Establish lines of communication
Everyone in your organization needs to know who’s in charge of communicating vital information and how to get in touch with key members of the disaster recovery team. You should also identify a single person (or small team of people) responsible for communicating relevant updates to the public to ensure consistent messaging.
Network disaster recovery plan checklist:
□ Determine how to communicate with the disaster recovery team (and the rest of the organization) if email and phones are down.
□ Create a flowchart outlining who should be contacted in what order for each specific disaster scenario and recovery step.
□ Identify a single point of contact responsible for disseminating critical information to staff.
□ Make a list (in multiple locations to ensure constant availability) of vendor and support phone numbers to call in case of a cloud or service-related outage.
★ Tip: Also include the support numbers for all your recovery-related technology.
□ Identify a single point of contact through which all information about your disaster will be disseminated to the public/customers.
Create a disaster recovery playbook
You should collect all of the information gathered and analyzed in the previous steps into a single playbook that will act as the source of truth for your disaster recovery efforts. This playbook should be made readily available to everyone involved in the disaster recovery plan and duplicated across redundant systems to ensure it’s accessible when a disaster occurs. Essential information from the playbook (such as points of contact) should be shared with everyone in your organization, even if they don’t have a role to play in recovery.
Test your plan regularly
How do you know your plan actually works? You need to test your plan after implementation and then test again on a regular basis. Conduct employee drills to make sure everyone involved knows what they need to do if a disaster occurs. Test your processes and technologies to make sure they still function correctly and that you can recover within the timeline outlined above. Regular testing will let you know if any processes, instructions, or contact points are outdated.
The challenge of network disaster recovery
Even with the most robust network disaster recovery plan, you’re likely to face some hurdles when it comes time to execute your protocols.
For example, what if a disaster occurs at a remote branch office or data center? If you lose network access to your remote infrastructure, do you have a way to remotely troubleshoot and recover, or do you need to lose time and money to truck rolls or local consultants?
How do you deploy replacement devices if remote hardware fails or is irreparably damaged? Do you have staff on-site who can install and configure new devices? If you stage new equipment at HQ and then ship it to the remote site, what happens if a malicious actor intercepts the package?
Do you have a way to monitor your infrastructure centrally and orchestrate your disaster recovery efforts? Can that system dig its hooks into every network architecture component, including legacy systems?
How ZPE Systems empowers streamlined network disaster recovery
The Nodegrid solution from ZPE Systems helps you execute your disaster recovery plan while avoiding all the most common challenges. Remote out-of-band management gives you access to all your remote network infrastructure via a dedicated link so you can still view, troubleshoot, and recover systems during an outage.
Ultra-secure zero touch provisioning (ZTP) allows you to ship factory-default equipment to remote sites and deploy configurations in a matter of moments, so you can recover faster. Plus, the vendor-neutral ZPE Cloud management platform gives you complete control and visibility on your distributed network infrastructure so you can monitor for issues and implement recovery protocols from anywhere in the world.
Learn more about network disaster recovery:
★ Customer Strategies in Ukraine to Protect Privacy and IP
★ Data Center Environmental Monitoring: How to Stop Disaster Before It Strikes
★ 3 Tips to Improve Edge Network Resilience
Execute your network disaster recovery plan checklist with the Nodegrid solution from ZPE Systems.
Get in contact with us or call 1-844-4ZPE-SYS for a free demo.
")
")
")

")