KVM Switch vs. Serial Console: Understanding the Key Differences and Best Use Cases

In IT infrastructure management, two essential tools often come into play: KVM switches and serial consoles. While they may seem similar at first glance, understanding their distinct functionalities is crucial for system administrators. In this guide, we’ll break down their differences, use cases, and how they can work together for optimal infrastructure management.
What is a KVM Switch?
A KVM (Keyboard, Video, Mouse) switch is a hardware device that allows users to control multiple computers from a single keyboard, monitor, and mouse. This setup eliminates the need for multiple peripherals, streamlining IT operations.
Benefits of using a KVM switch:
- Centralized Management: Control multiple servers from one console.
- Space & Cost Efficiency: Reduces clutter and hardware costs in server rooms.
- Graphical Interface Access: Enables GUI-based management for various operating systems.
- Remote Management: Some KVM switches offer IP-based remote access for IT teams.
KVM switches are ideal for data centers, server management, and IT environments where GUI access is necessary.
What is a Serial Console?
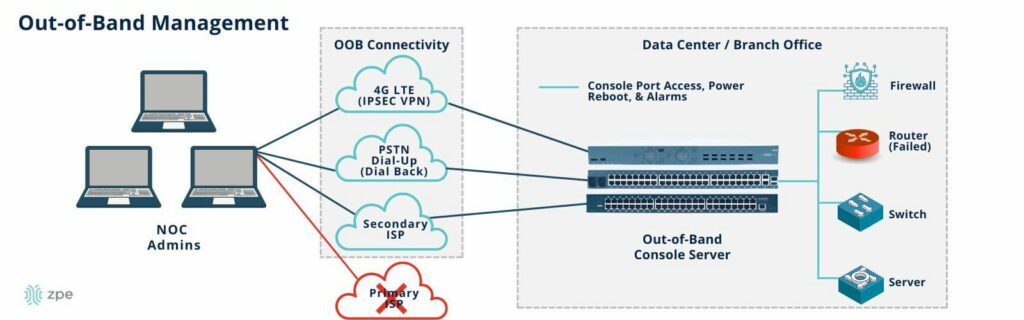
A serial console, also called a console server, provides remote access to devices via serial ports. It is primarily used to manage network equipment such as routers, switches, and firewalls — especially when network access is unavailable.
Key advantages of serial consoles:
- Out-of-Band Management: Provides access even when the primary network is down.
- Command-Line Interface (CLI) Support: Essential for configuring network devices.
- Improved Security: Enables remote troubleshooting without exposing devices to the main network.
- Multi-Vendor Support: Works with various networking and industrial hardware.
Serial consoles are indispensable for network management, disaster recovery, and remote troubleshooting of mission-critical systems. They provide low-level access to equipment and serve as an administrative lifeline when the primary network is not working properly.
KVM Switch vs. Serial Console: A Side-By-Side Comparison
When to Use a KVM Switch vs. Serial Console
Choose a KVM switch if:
- You need to manage multiple servers with a graphical interface.
- Your IT infrastructure includes Windows, Linux, or other GUI-based systems.
- Remote desktop-style management is required.
Choose a serial console if:
- You need to configure network hardware like routers and firewalls.
- Out-of-band management is crucial for your IT setup.
- You need access when the primary network fails.
Combining KVM Switches and Serial Consoles for More Capability
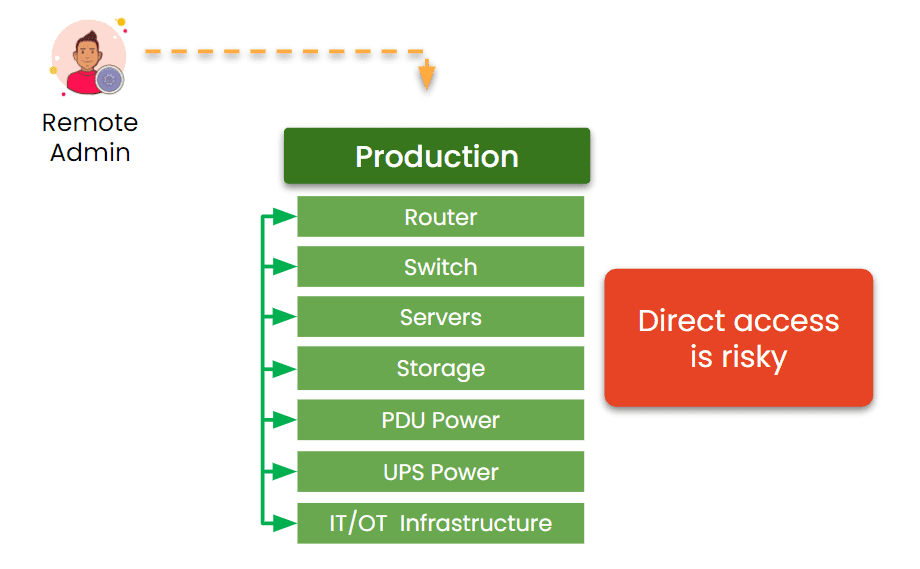
Many IT environments benefit from using both KVM switches and serial consoles in tandem. This setup allows IT teams to efficiently manage both graphical and command-line-based systems, ensuring comprehensive remote access and troubleshooting capabilities. The drawback to this is that it requires deploying more devices, which not only increases costs, but also increases complexity and workloads for IT teams.
Simplify IT Management with ZPE Systems’ Nodegrid Devices
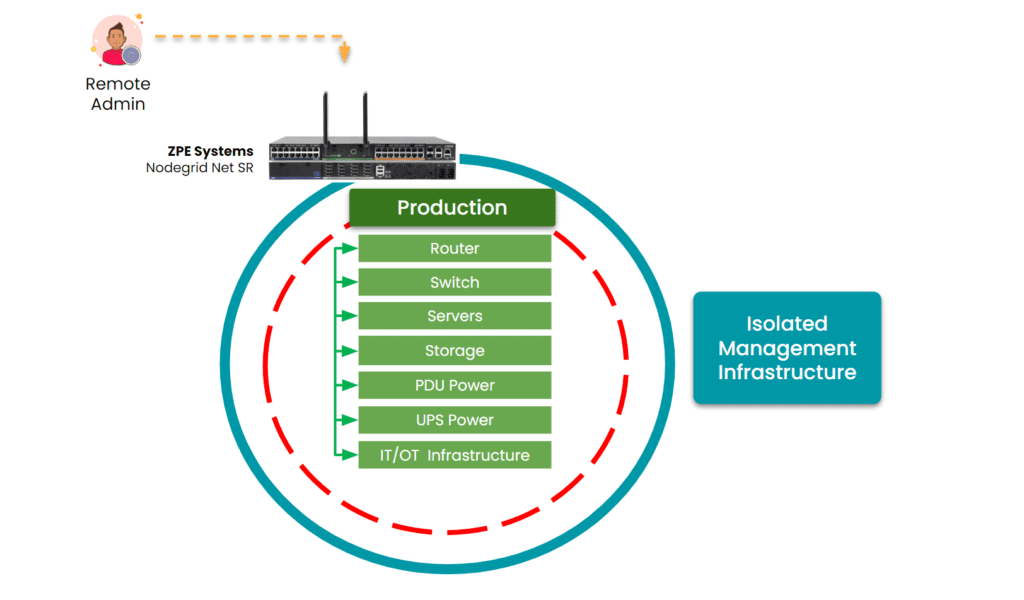
Why choose between a KVM switch and a serial console when you can have both in a single device? ZPE Systems’ Nodegrid solutions combine KVM and serial console functionality into an all-in-one platform, simplifying IT infrastructure management.
Why choose Nodegrid?
- Unified Management: Access servers, routers, switches, and more from one interface.
- Enhanced Security: Secure out-of-band management with built-in Zero Trust architecture.
- Remote Access: Control your entire infrastructure from anywhere, even during network failures.
- Scalability: Streamline operations for edge, branch, and data center environments.
Upgrade your IT management with the versatile, secure, and efficient out-of-band solution. Browse our collection of products that combine KVM and serial console functionalities, and get in touch for a free demo.
See KVM & Serial Console Functionality in This Tech Demo
Jordan Baker (Tech Writer) shows how to migrate your existing solution to Nodegrid, and gives a 5-minute tech demo of what it’s like to manage serial connections, PDUs, and KVM switches, all from one interface. Watch now and visit our serial console migration page for special offers.