Data Center Environmental Sensors: Everything You Need to Know
According to a recent Uptime Institute survey, severe outages can cost more than $1 million USD and lead to reputational loss as well as business and customer disruption. Humidity, air particulates, and other problems could shorten the lifetime of critical equipment or cause outages. Unfortunately, much of a business’s critical digital infrastructure and services are housed in remote data centers, making it difficult for busy IT teams to keep eyes on the environmental conditions.
Data center environmental sensors can help teams prevent downtime by monitoring conditions in remote infrastructure deployments and alerting administrators to any problems before they lead to equipment failure. This blog explains how environmental sensors work and describes the ideal environmental monitoring solution for minimizing outages.
How data center environmental sensors reduce downtime
Data center environmental sensors are deployed around the rack, cabinet, or cage to collect information about various conditions that could negatively affect equipment like routers, servers, and switches.
Mitigating environmental risks with data center environmental sensors
| Environmental Risk | Description | How Environmental Sensors Help |
|---|---|---|
| Temperature | All data center equipment has an optimal operating temperature range, as well as a max temp threshold above which devices may overheat. | Environmental sensors monitor ambient temperatures and trigger automated alerts when it gets too hot or too cold in the data center. |
| Humidity | If the air in the data center gets too humid, moisture may collect on the internal components of devices and cause corrosion, shorts, or other failures. | Environmental sensors monitor the relative humidity in the DC and alert administrators when there’s a danger of moisture accumulation. |
| Fire | A fire in the data center could burn equipment, raise the ambient temperature beyond acceptable limits, or activate automatic fire suppression controls that damage devices. | Environmental sensors detect the heat and smoke from fires, giving DC teams time to shut down systems before they’re damaged. |
| Tampering | A malicious actor who’s able to get past data center security (such as an inside threat) could potentially tamper with equipment to damage or breach it. | Tamper detection sensors alert remote teams when data center cabinet doors are opened or a device is physically moved. |
| Air Particulates | Smoke, ozone, and other air particulates could potentially damage data center infrastructure by oxidizing components or clogging vents. | Environmental sensors monitor air quality and automatically alert teams when particulates are detected. |
These sensors report back to monitoring software that’s either deployed on-premises in the data center or hosted in the cloud. Administrators use this software to view real-time conditions or to configure automated alerts.
Environmental monitoring sensors help reduce outages by giving remote IT teams advance warning that something is wrong with conditions in the data center, enabling them to potentially fix the problem before any systems go down. However, traditional monitoring solutions suffer from a number of limitations.
- They need a stable internet connection to allow remote access, so if there’s an ISP outage or unknown failure, teams lose their ability to monitor the situation.
- Many of them use on-premises software that requires administrators to connect via VPN to monitor or manage the solution, creating security risks and management hurdles.
- Most environmental monitoring systems don’t easily integrate with other remote management tools, leaving administrators with a disjointed patchwork of platforms to wrestle with.
The ideal data center environmental monitoring solution
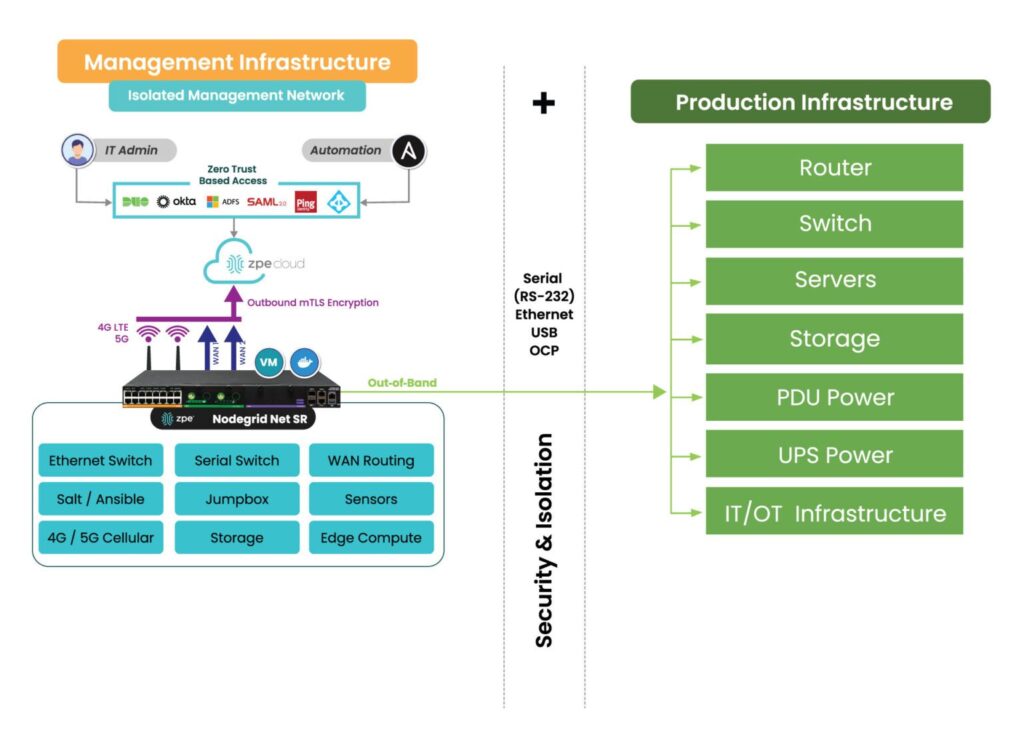
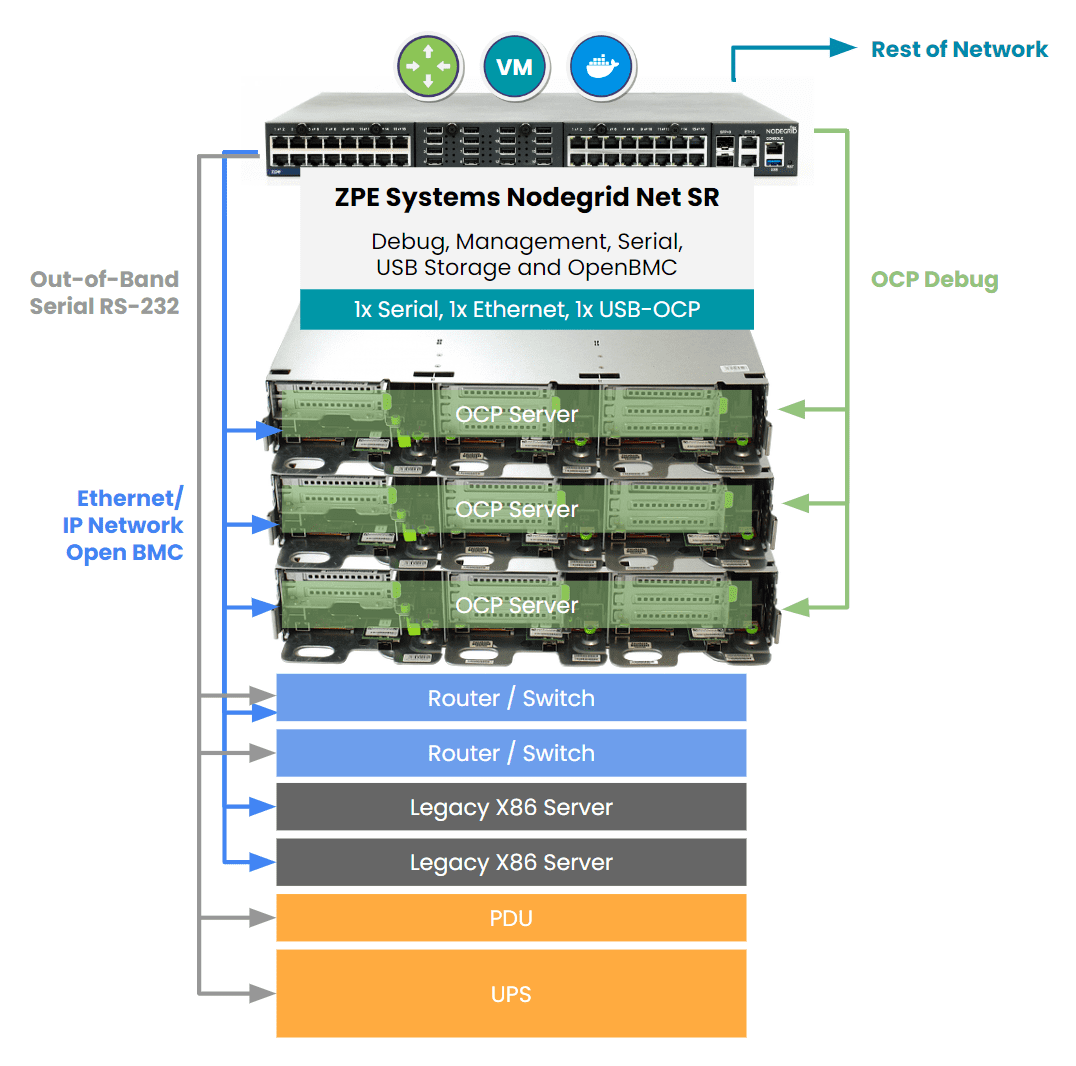
The Nodegrid data center environmental monitoring platform overcomes these challenges with a combination of out-of-band management, cloud-based software, and a vendor-agnostic architecture.
Nodegrid environmental sensors work with Nodegrid serial consoles to provide remote teams with a virtual presence in the data center. These devices create an instant out-of-band network that uses a dedicated internet connection to provide continuous remote access to all connected sensors and infrastructure. This network doesn’t rely on the primary ISP or production network resources, giving administrators a lifeline to monitor and recover remote data center devices during an outage. The addition of Nodegrid Data Lake also allows teams to collect environmental monitoring data, discover trends and insights, and create better automation to address issues.
Nodegrid’s data center environmental monitoring and infrastructure management software is available on-premises or in the cloud, allowing teams to access critical equipment and respond to alerts from anywhere in the world. Plus, all Nodegrid hardware and software is vendor-neutral, supporting seamless integrations with third-party tools for automation, security, and more.
Schedule a free Nodegrid demo to see our data center environmental sensors and vendor-neutral management platform in action!