Dissecting the MGM Cyberattack: Lions, Tigers, & Bears, Oh My!

This article was written by James Cabe, CISSP, whose cybersecurity expertise has helped major companies including Microsoft and Fortinet.
The recent MGM cyberattack reportedly caused the company to lose millions in revenue per day. The successful kill chain attack — originally a military tactic used to accomplish a particular objective — granted inside access to the attackers, who encrypted and held for ransom some of MGM’s most prized assets. These ‘crown jewel’ assets, as they’re called in the cybersecurity realm, are most critical to the accomplishment of an organization’s mission. Because ransomware attacks persist in corporate networks until fully cleared, organizations must be ready to “fight through” an attack using resilient systems and effective procedures. This should involve identifying these crown jewels and designing them in a way that ensures they can operate through attacks.
When these types of large-profile attacks occur, many cast their eyes at cybersecurity leaders for failing to fend off the bad guys. The reality is these leaders struggle to get budget, corporate buy-in, and digital assets that are required to build a strong defense for business continuity. For MGM, it’s likely they also faced difficulty operationalizing current assets across a gigantic digital estate, and ultimately lacked a plan to recover from a total outage of crown jewel assets.
From the attacker’s perspective, an exceptional level of intelligence and preparation are required in order to understand a target’s internal operations and architecture and execute a successful kill chain. Successfully attacking a sophisticated organization like MGM requires rapid information stealing to capture and leverage cloud credentials, as well as to lock up those resources and lock out the most important support staff in an organization. This is the crux of the issue: infostealers and ransomware automate the mass grabbing of resources and quickly set up a denial of services for the stakeholders that are responsible for fixing these systems.
How did the MGM cyberattack start? After MGM discovered the breach, how did the attacker stay one step ahead? What approach should organizations take to ensure they can recover if they’re targeted?
Who Started The MGM Cyberattack, and How?
The MGM cyberattack began after an adversary group named “Scattered Spider” used phishing over the phone, an approach called ‘vishing,’ to convince MGM’s customer support rep into granting them access with elevated privileges. Scattered Spider is the same group responsible for the SIM-swapping campaign that happened a few months ago, where they successfully subverted multifactor authentication. Their primary tactic involves social engineering, which they use to steal personal information from employees.
MGM and many other casinos currently use advanced Zero Trust identity security from Okta. However, the attacker was able to trick the service desk into resetting a password to gain access into the network. Even with newer Zero Trust identity solutions, most organizations unravel once attackers get to the real “chewy center” of the network: the humans operating them.

Okta is quoted saying, “In recent weeks, multiple US-based Okta customers have reported a consistent pattern of social engineering attacks against their IT service desk personnel, in which the caller’s strategy was to convince service desk personnel to reset all multi-factor authentication (MFA) factors enrolled by highly privileged users.” Okta further warned, “The attackers then leveraged their compromise of highly privileged Okta Super Administrator accounts to abuse legitimate identity federation features that enabled them to impersonate users within the compromised organization.”
The MGM cyberattack and those like it are more about processes than technology. Let’s explore how the attack progressed, and how the criminals were successful at staying persistent and ultimately hitting their goal.
How Did A Simple Authentication Attack Morph Into a Complex Attack?
The Scattered Spider threat actors use a platform written by UNC3944 or AlphaV (known by several names). This is a middleware developer for attack platforms that allow criminals to follow a specific set of instructions (a kill chain) to gain access and ultimately encrypt and exfiltrate data from a targeted company. AlphaV’s platform is called BlackCat, which they use to establish a foothold, establish Command and Control (C2) for the malware, and exfiltrate data, to ultimately get paid.
With elevated Okta privileges at MGM, Scattered Spider deployed a file containing a Java-based remote access trojan, which became a “vending machine” for other remote access trojans (RATs) that sought out other nearby machines to spread quickly. The AlphaV RAT would ‘pwn‘ MGM’s Azure virtual servers to gain access, then sniff for more user passwords and create dummy accounts.
These RATs leveraged a built-in tool called “POORTRY,” the Microsoft Serial Console driver turned malicious, to terminate selected processes on Windows systems (e.g., Endpoint Detection and Response (EDR) agents on endpoints). AlphaV, the platform maintainer, signed the POORTRY driver with a Microsoft Windows Hardware Compatibility Authenticode signature. This helped the malware to evade most Endpoint Detection software.
This tool was used to get elevated and persistent access to the Okta Proxy servers that were in the scope of the attack and accessible remotely by the attacker. This attack can evade a lot of detection tools. This access allowed them to capture AM\IAM accounts that allowed them greater access to the organization. This stealing of credentials from the Okta Proxy servers was confirmed by Okta responders as well as the threat actor on their blog. This is called a “living off the land” attack.

How Did MGM Discover the Cyberattack?
The first notification of the hack was dropped on the VXUnderground forums. The staff there verified through chat contact with the threat group UNC3944\AlphaV, who works in conjunction with the Scattered Spider threat actor, The attacker also confirmed this on their blog on the darknets.
On September 11, 2023, anyone attempting to visit MGM’s website was greeted by a message stating that the website was currently unavailable. The attack also stopped hotel card readers, gaming machines, and other equipment critical to MGM’s day-to-day operations and revenue generating activities.
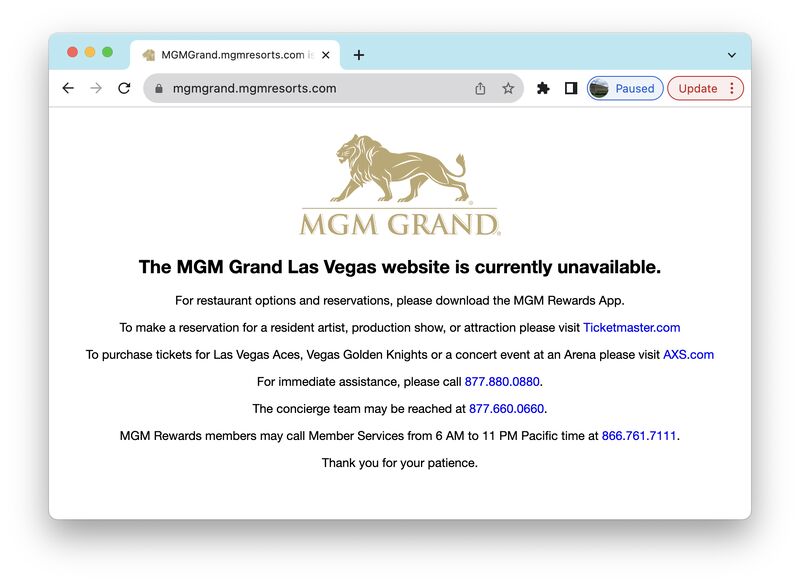
How Did the Attacker Maintain Control?
The initial attack allowed AlphaV, who runs the C2 (Command and Control) networks for the RattyRat trojan, to have remote access to the VMware server farm that services the guest systems, the gaming control platforms, and possibly the payment processing systems. They maintained control despite all of MGM’s attempts to mitigate the problem, because they were able to establish elevated access in places the organization could not easily remove them from without removing access to the whole organization. They established something called “persistence.”
From the attacker’s blog on the darknet, “MGM made the hasty decision to shut down every one of their Okta Sync servers after learning that we had been lurking on their Okta Agent servers sniffing passwords of people whose passwords couldn’t be cracked from their domain controller hash dumps. At this point MGM being completely locked out of their local environment. Meanwhile the attacker continued having super administrator privileges to their Okta, along with Global Administrator privileges to their Azure tenant. They made an attempt to evict us after discovering that we had access to their Okta environment, but things did not go according to plan. On Sunday night, MGM implemented conditional restrictions that barred all access to their Okta (MGMResorts.okta.com) environment due to inadequate administrative capabilities and weak incident response playbooks. Their network has been infiltrated since Friday. Due to their network engineers’ lack of understanding of how the network functions, network access was problematic on Saturday. They then made the decision to ‘take offline’ seemingly important components of their infrastructure on Sunday. After waiting a day, we successfully launched ransomware attacks against more than 100 ESXi hypervisors in their environment on September 11th after trying to get in touch but failing.“
MGM tried many things to remove access into their network. However, because of an advanced attack that installed a shadow identity provider in their own Identity Solution, they were able to maintain access long enough to redeploy access to most of the assets they found to be the backbone of the company. AlphaV was then able to encrypt most of the crown jewels of MGM’s operations network.
Is There a Way to Stop These Types of Attacks?
The MGM cyberattack required physical reconnaissance, patience, and a lot of planning to set up the kill chain. Playbooks that can protect against this kind of attack are hard to create, because it can mean taking all guest services offline for a period, which requires very high authority in the organization. One of the comments from the attacker was that the organization did not act fast enough to take all remote access offline to their management framework that consisted of Okta Proxy Servers. When they did, the adversary was then able to lock them out by submitting a Multifactor Authentication Reset. To stall the attacker, they would have had to induce a full outage of their crown jewels while a formal assessment of all assets could be performed. Taking assets offline requires buy-in at the board level and executive level, which are difficult to come by even if an organization emphasizes its operational excellence, detection, and defense.
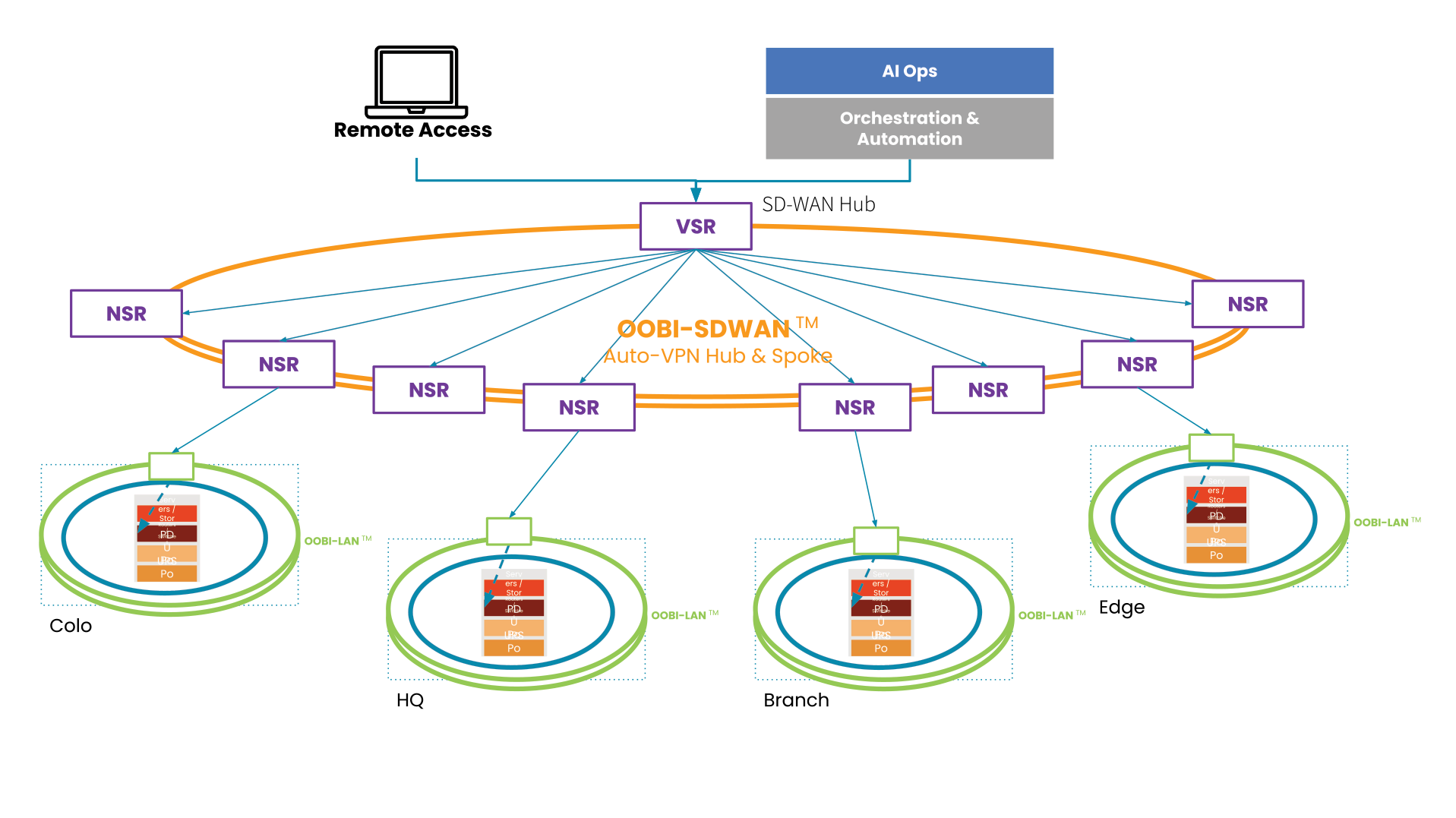
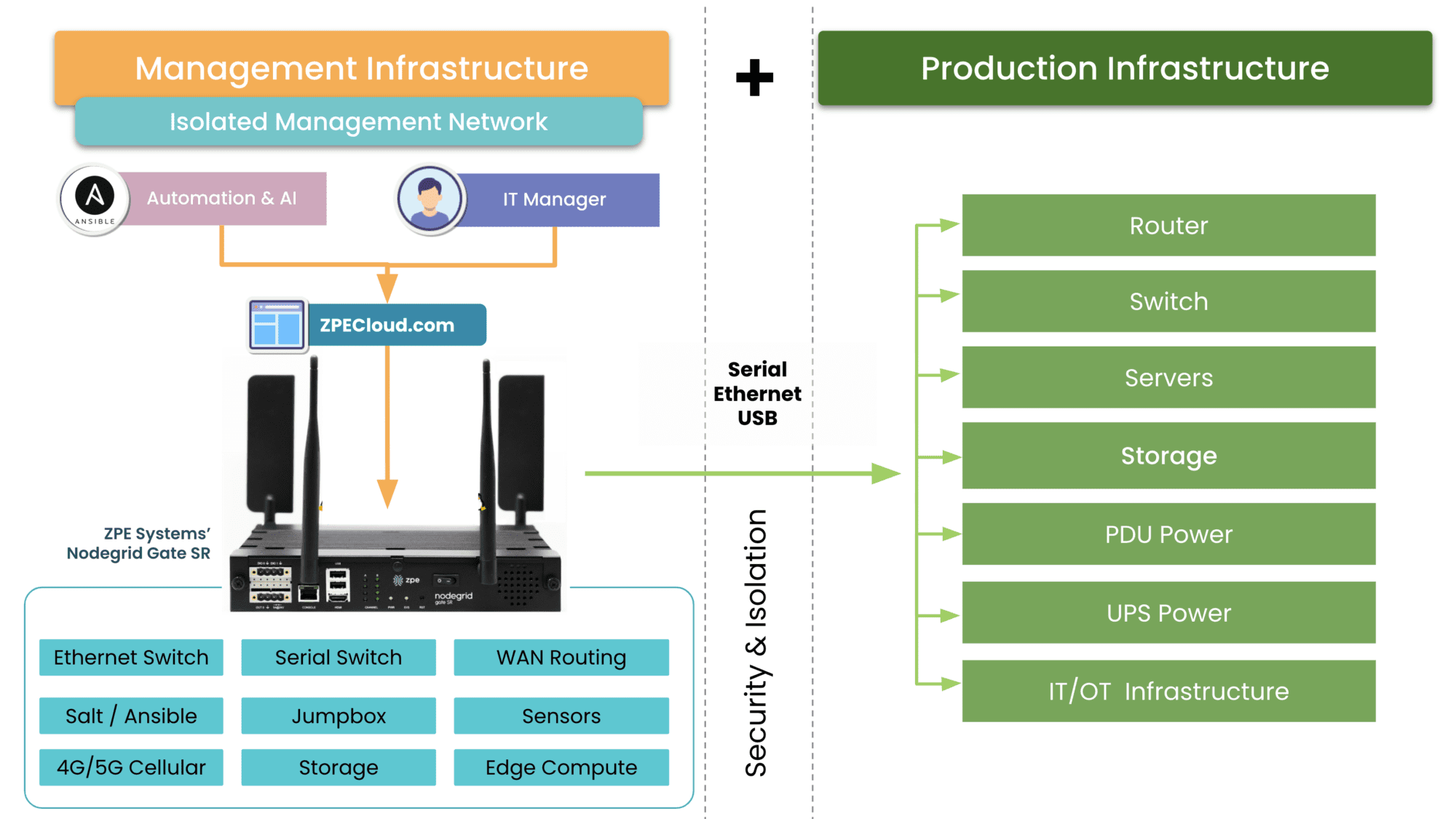
Organizations should have a plan to quickly recover from a total loss of a site, outside of backups (which can be lost) and disaster recovery sites. Organizations need to be properly hard-segmented into a full IMI (Isolated Management Infrastructure). Keeping crown jewels safe from an attacker that targets the chewiest part of an organization should be top of any list going from 2023 budget to 2024 planning.
The following is a light version of what can be done in a fully-automated response that can take mere hours instead of days for an outage (a full operations blueprint will be out in the near future).
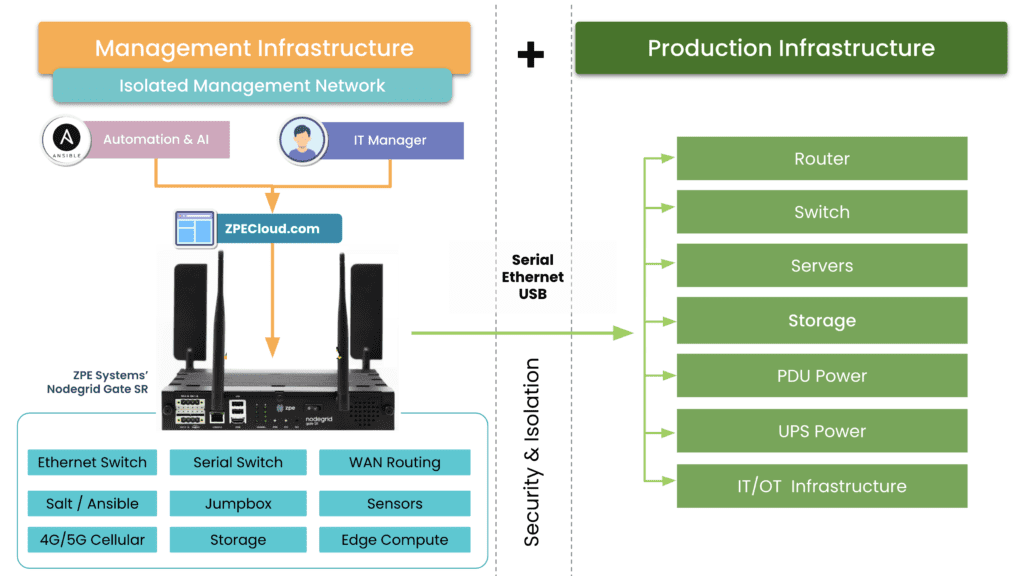
An IMI can host an IRE (Isolated Recovery Environment), which is used to cut off all user data and remote access (except for OOB) to an entire infected site. A properly implemented recovery environment should automate most of these activities to speed up the recovery. One of the first considerations is the requirement for a secondary organization in your IAM that is not attached to normal operations. This is what is known as a set of “Break the Glass” accounts. These are known in military circles but have made it into formal practice as part of a strong playbook for ransomware. Once you do this, you can instantiate selected Zero Trust remote access to the site using credentials that are not in the scope of the attack, and then bring up a communications channel for a virtual war room using software like Rocket Chat, Jitsi, Slack, or other standalone communications tools that are installable on the IRE environment.
Avoiding normal authentication methods or IAM and normal communication channels is required for the integrity of the recovery and strengthens the recovery playbook. During this time, no email may be used that is associated directly with the organization. Ideally, email should never touch an account that is associated with it either.
The next step is to create a new set of clean side networks that do not directly connect to the main backbone or put it behind another firewall for triage good/bad. Using a sniffer software running on the IRE, the recovery team can then run a passive scan or an active scanner against all machines continuing to try to send email to exchange\M365. You can give access to people that are deemed good (not sending traffic) but lock off (with an EDR) the ability to open Outlook for a while, while keeping them on the web email. From there, continue working through to find all the sending drivers to see if they have a good backup. If not, back up the infected drive for offline data retrieval for later. Then reimage while scanning the UEFI BIOS during boot (if needed, run an IPMI scan). If the site has a list of assets that are considered crown jewels, prioritize these.
Once you have a segmented “clean side” established with all the network services required to operate the site (DNS, IAM, DHCP), then Internet access can be restored to this site on a limited basis; which means only out-bound communications, nothing in-bound. Restorative operations can continue apace. making sure that the infected side assets are captured in backup for later forensics following chain-of-custody if damages exceeding insurance limits are found to be the case. This is decided in the war room.
Get the Blueprint for Isolated Management Infrastructure
Maintaining control of critical systems is something security practitioners deal with in the Operational Technology (Industrial Control Systems) side of an organization. For them, the critical and most impactful part of the problem is the loss of control rather than the loss of data, a problem highlighted by the MGM cyberattack. Operational Technology Safety and Security teams set up and maintain Safety Systems as a fallback measure in case of any kind of disaster. This automation allows fallback of services safely, from which point they can recover operations. In 2023, most of our business is done on computers and networks. It is how to plan for business continuity. Now is the time that IT started following this safety system blueprint as well.
Download the Network Automation Blueprint now, which helps you lay the groundwork for your IMI so you can recover from any attack.
Get in touch with me!
True security can only be achieved through resilience, and that’s my mission. If you want help shoring up your defenses, building an IMI, and implementing a Resilience System, get in touch with me. Here are links to my social media accounts: