Edge Computing Architecture Guide
| Table of Contents |
What is edge computing?
The Open Glossary of Edge Computing defines it as deploying computing capabilities to the edges of a network to improve performance, reduce operating costs, and increase resilience. Edge computing reduces the number of network hops between data-generating devices and the applications that process and use that data, mitigating latency, bandwidth, and security concerns compared to cloud or on-premises computing.
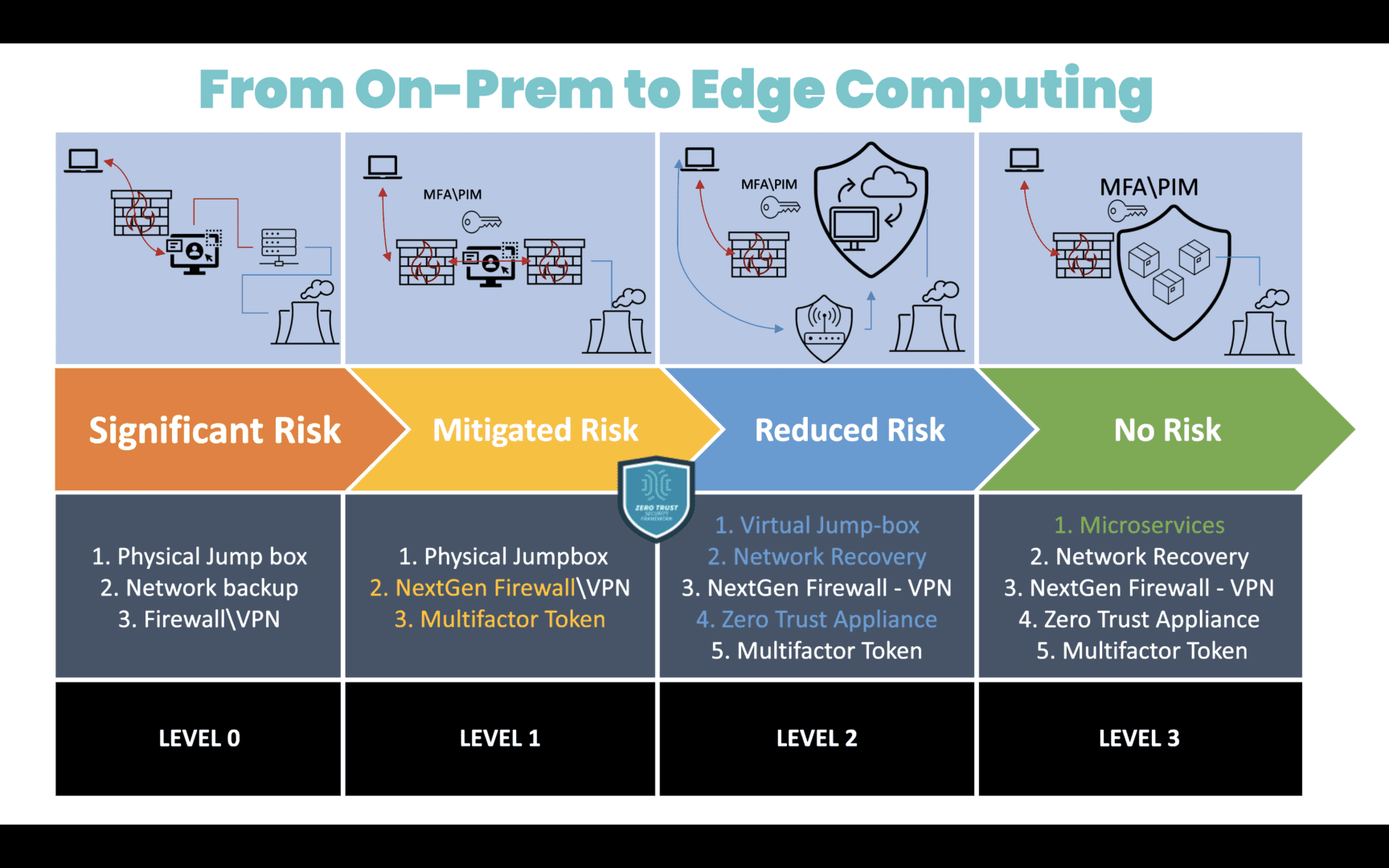
Image: A diagram showing the migration path from on-premises computing to edge computing, along with the associated level of security risk.
Edge-native applications
Edge-native applications are built from the ground up to harness edge computing’s unique capabilities while mitigating the limitations. They leverage some cloud-native principles, such as containers, microservices, and CI/CD (continuous integration/continuous delivery), with several key differences.
Edge-Native vs. Cloud-Native Applications
| Edge-Native | Cloud-Native | |
| Topology | Distributed | Centralized |
| Compute | Real-time processing with limited resources | Deep processing with scalable resources |
| Data | Constantly changing and moving | Long-lived and at rest in a centralized location |
| Capabilities | Contextualized | Standardized |
| Location | Anywhere | Cloud data center |
Source: Gartner
Edge-native applications integrate seamlessly with the cloud, upstream resources, remote management, and centralized orchestration, but can also operate independently as needed. Crucially, they allow organizations to actually leverage their edge data in real-time, rather than just collecting it for later processing.
Edge computing use cases
Nearly every industry has potential use cases for edge computing, including:
| Industry | Edge Computing Use Cases |
| Healthcare |
|
| Finance |
|
| Energy |
|
| Manufacturing |
|
| Utilities/Public Services |
|
To learn more about the specific benefits and uses of edge computing for each industry, read Distributed Edge Computing Use Cases.
Edge computing architecture design
An edge computing architecture consists of six major components:
| Edge Computing Components | Description | Best Practices |
| Devices generating edge data | IoT devices, sensors, controllers, smartphones, and other devices that generate data at the edge | Use automated patch management to keep devices up-to-date and protect against known vulnerabilities |
| Edge software applications | Analytics, machine learning, and other software deployed at the edge to use edge data | Look for edge-native applications that easily integrate with other tools to prevent edge sprawl |
| Edge computing infrastructure | CPUs, GPUs, memory, and storage used to process data and run edge applications | Use vendor-neutral, multi-purpose hardware to reduce overhead and management complexity |
| Edge network infrastructure and logic | Wired and wireless connectivity, routing, switching, and other network functions | Deploy virtualized network functions and edge computing on common, vendor-neutral hardware |
| Edge security perimeter | Firewalls, endpoint security, web filtering, and other enterprise security functionality | Implement edge-centric security solutions like SASE and SSE to prevent network bottlenecks while protecting edge data |
| Centralized management and orchestration | An EMO (edge management and orchestration) platform used to oversee and conduct all edge operations | Use a cloud-based, Gen 3 out-of-band (OOB) management platform to ensure edge resilience and enable end-to-end automation |
Click here to learn more about the infrastructure, networking, management, and security components of an edge computing architecture.
How to build an edge computing architecture with Nodegrid
Nodegrid is a Gen 3 out-of-band management platform that streamlines edge computing with vendor-neutral solutions and a centralized, cloud-based orchestrator.
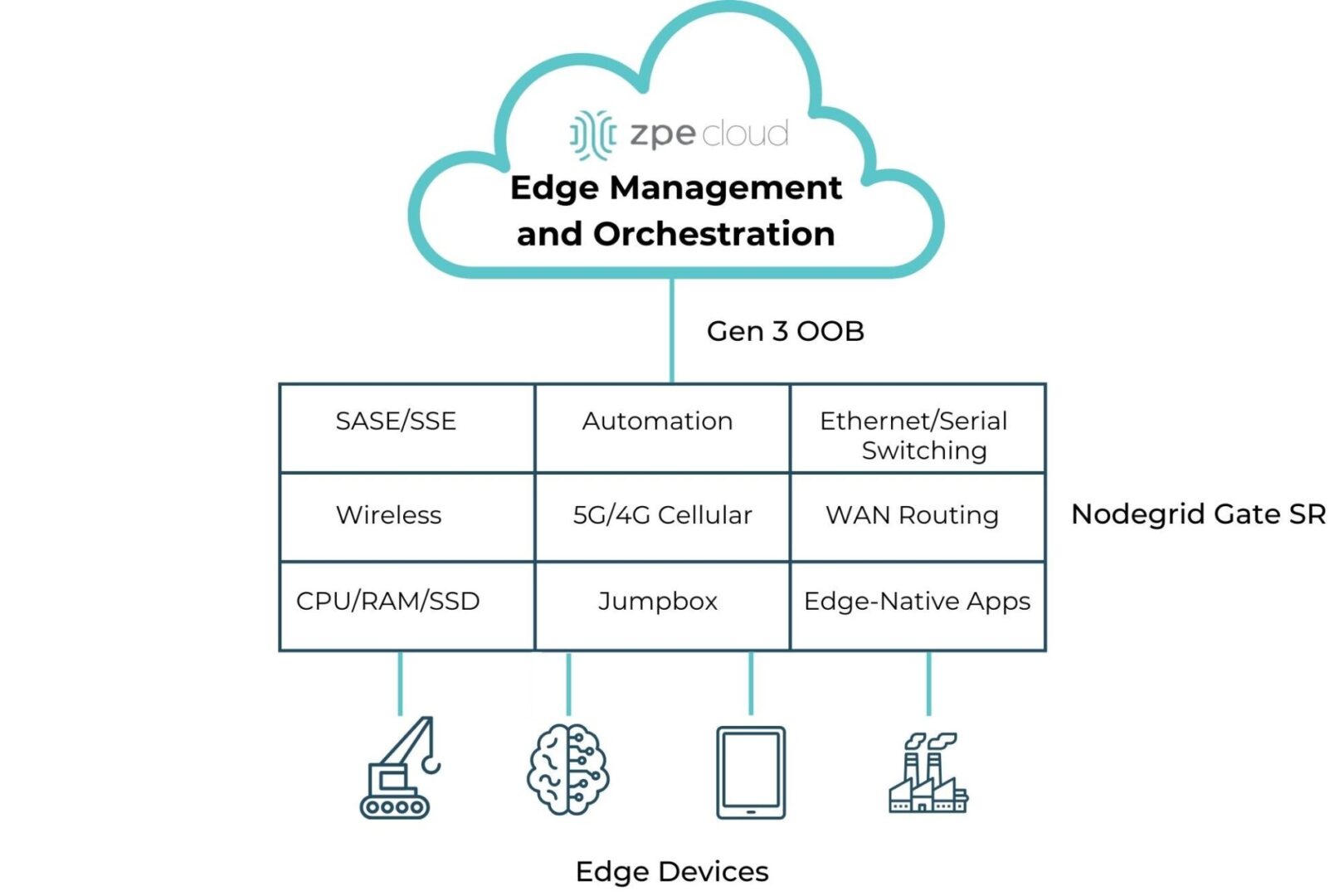
Image: A diagram showing all the edge computing and networking capabilities provided by the Nodegrid Gate SR.
Nodegrid integrated services routers deliver all-in-one edge computing and networking functionality while taking up 1RU or less. A Nodegrid box like the Gate SR provides Ethernet and Serial switching, serial console/jumpbox management, WAN routing, wireless networking, and 5G/4G cellular for network failover or out-of-band management. It includes enough CPU, memory, and encrypted SSD storage to run edge computing workflows, and the x86-64bit Linux-based Nodegrid OS supports virtualized network functions, VMs, and containers for edge-native applications, even those from other vendors. The new Gate SR also comes with an embedded NVIDIA Jetson Orin NanoTM module featuring dual CPUs for EMO of AI workloads and infrastructure isolation.
Nodegrid SRs can also host SASE, SSE, and other security solutions, as well as third-party automation from top vendors like Redhat and Salt. Remote teams use the centralized, vendor-neutral ZPE Cloud platform (an on-premises version is available) to deploy, monitor, and orchestrate the entire edge architecture. Management, automation, and orchestration workflows occur over the Gen 3 OOB control plane, which is separated and isolated from the production network. Nodegrid OOB uses fast, reliable network interfaces like 5G cellular to enable end-to-end automation and ensure 24/7 remote access even during major outages, significantly improving edge resilience.
Streamline your edge deployment
The Nodegrid platform from ZPE Systems reduces the cost and complexity of building an edge computing architecture with vendor-neutral, all-in-one devices and centralized EMO. Request a free Nodegrid demo to learn more.