OOB Network Management Software Tools
")
Network management software tools enable administrators to provision, monitor, and maintain networks and network infrastructure without manually touching each individual device or service. We’ve previously covered the best network management software for both cloud-based and hardware-based networks. This post dives deeper into the hardware-based network management tools deployed in on-premises or private cloud environments via serial consoles (a.k.a. console servers, serial console servers, serial console routers, or serial switches).
These network management software tools provide out-of-band (OOB) management access to connected network infrastructure in data centers and remote sites. Serial consoles directly interface with network systems and devices, creating an isolated management network that doesn’t depend on the production LAN, WAN, or ISP. OOB management ensures continuous remote access even during major outages, so teams can troubleshoot and recover branch offices, edge computing sites, and other remote environments without costly truck rolls or managed service support. OOB console servers also unify management of all connected infrastructure, giving administrators a single platform to monitor, control, and automate the entire distributed network architecture.
Looking for a new out-of-band network management device? Read our guide:
We compare offerings from the four best OOB network management software tool providers and discuss the features, advantages, and disadvantages of each to help network teams make the best choice for their environment.
The best OOB network management software tools
Disclaimer: This comparison was written by a 3rd party in collaboration with ZPE Systems using data gathered from publicly available data sheets and admin guides, as of 10/13/2023. Please email us if you have corrections or edits, or want to review additional attributes: Matrix@zpesystems.com
ZPE Systems Nodegrid Manager/ZPE Cloud
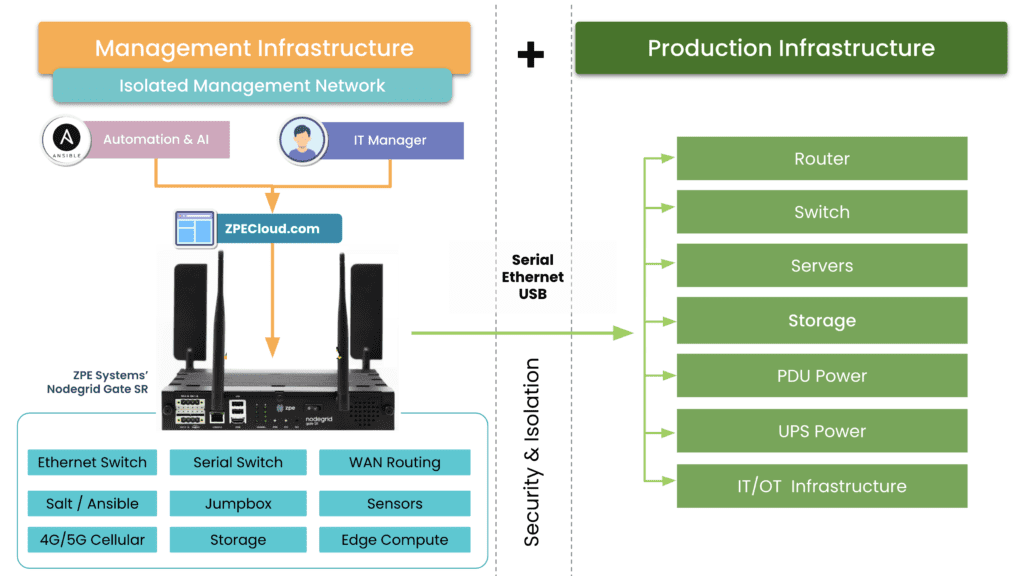
ZPE Systems offers two network management software tools based on their Nodegrid line of serial consoles and integrated edge routers. Nodegrid Manager is on-premises software, and ZPE Cloud is a cloud-based tool, but both provide out-of-band management access to on-premises infrastructure in data centers, branches, private clouds, and other remote sites. Nodegrid hardware offers a variety of connectivity options for OOB, failover, and WAN, including Wi-Fi and 5G. Nodegrid also supports a full range of environmental monitoring sensors for greater control over conditions in remote deployments.
Nodegrid solutions are protected by robust hardware and software security features, including UEFI Secure Boot, an embedded firewall with selectable cryptographic protocols, and 2FA and SAML 2.0 authentication. The x86 CPU architecture and Linux-based OS support Guest OSes and Docker containers, so Nodegrid boxes can directly host third-party software for security, automation, orchestration. Both Nodegrid Manager and ZPE Cloud are also completely vendor-neutral, supporting third-party automation scripts and tools including RedHat Ansible, Chef, Python, Ruby, and more. Nodegrid can even extend ZTP and other automation to legacy infrastructure that otherwise wouldn’t support it.
Nodegrid’s open platform essentially makes it a customizable network management multi-tool that’s capable of consolidating many different software solutions and network services. The primary limitation to this vendor-neutrality is that some other providers may require the purchase of additional licenses to run their tools on the Nodegrid platform.
For a real-world example of Nodegrid’s ability to streamline network management, read our case study, Vapor IO: Re-architecting the Internet.
.
Vertiv Avocent DSView
The DSViewTM network management software works with Vertiv Avocent out-of-band serial consoles, the ACS 800 and ACS 8000, which use 4G LTE cellular for out-of-band management and failover. Like the other options on this list, DSView consolidates the management of connected network infrastructure in a single web-based platform. In addition to serial port control, this software also provides keyboard/video/mouse (KVM) and MIB-based (Management Information Base) controls. It also supports environmental monitoring via sensors, but ACS8000 serial console servers only come with one sensor port – and the ACS800 doesn’t have one at all.
DSView management software includes automation support for Zero Touch Provisioning (ZTP), SOAP API, Python, and Perl scripts, and automated PDU (power distribution unit) and UPS (uninterruptible power supply) management. It also provides console event logging and notifications, such as “dying gasp” alarms when systems unexpectedly lose power. However, the software is not extensible with third-party automation or orchestration integrations, and the ACS800 and ACS8000 serial console hardware solutions run on an ARM CPU architecture that can’t support VMs or Docker.
.
PerleVIEW
PerleVIEW network management software tools are based on Perle’s IOLAN SCG & SCR OOB console servers. The platform includes automated device discovery, automatic event handling, device scripting, ZTP, and collection of device statistics and health statuses. Perle focuses on meeting the FCAPS network management framework created by the International Organization for Standardization (ISO). FCAPS standards for Fault management, Configuration, Administration, Performance management, and Security management, and PerleVIEW’s features target each of these areas. For example, fault management is streamlined through automated event handling with customizable alerts and SNMP probes.
However, the software does not support any third-party integrations, limiting its automation and security capabilities. Aside from automated device discovery and event handling, PerleVIEW doesn’t offer any automation for end devices. It also doesn’t support two-factor authentication (2FA), and only supports single sign-on (SSO) for in-band connections.
.
Opengear Lighthouse
Lighthouse is a network management platform that works with Opengear console servers, such as the OM2200 Operations Manager and the CM8100. The base version of Lighthouse provides out-of-band management access, integrated SAML and AAA authentication, and integrations with third-party notification and alert systems. Lighthouse supports over 100 power vendors’ equipment to streamline PDU and UPS management, and the x86 processor can run Guest OSes and automation.
With additional licenses, Lighthouse software is extensible with Opengear NetOps modules that provide greater automation capabilities with support for Bash, Docker, Pearl, Python, and Ruby. The upgraded Automation edition also includes ZTP for end devices and RESTful APIs. Beyond that, however, automation and orchestration abilities are limited because Lighthouse isn’t vendor-neutral, and Opengear has a limited ecosystem of integrations.
.
Key takeaways
All four options on this list provide out-of-band (OOB) access to remote network infrastructure, giving teams a lifeline in case of production failures or outages. Vertiv Avocent’s DSView software provides some automation capabilities and environmental monitoring, but doesn’t support third-party automation, VMs, or Docker containers. PerleVIEW focuses on meeting FCAPS network management standards but has very limited automation and security capabilities. Opengear Lighthouse is extensible with NetOps modules and other automation features, but they require additional licenses or fees, and you’re limited to Opengear’s ecosystem of integrations.
ZPE Systems offers Nodegrid Manager as an on-premises application or ZPE Cloud as a cloud-based tool. Both options use vendor-neutral hardware and software to create an open platform you can customize with your favorite third-party apps and integrations. ZPE’s OOB network management software tools enable end-to-end automation over a highly secure and reliable out-of-band control plane for a more resilient network infrastructure.
Deploy the best OOB network management software tools with ZPE Systems
Reach out to ZPE to learn how to build a resilient network with Nodegrid OOB network management software tools. Contact Us





 before discussing 5G RAN challenges, solutions, and use cases.")
