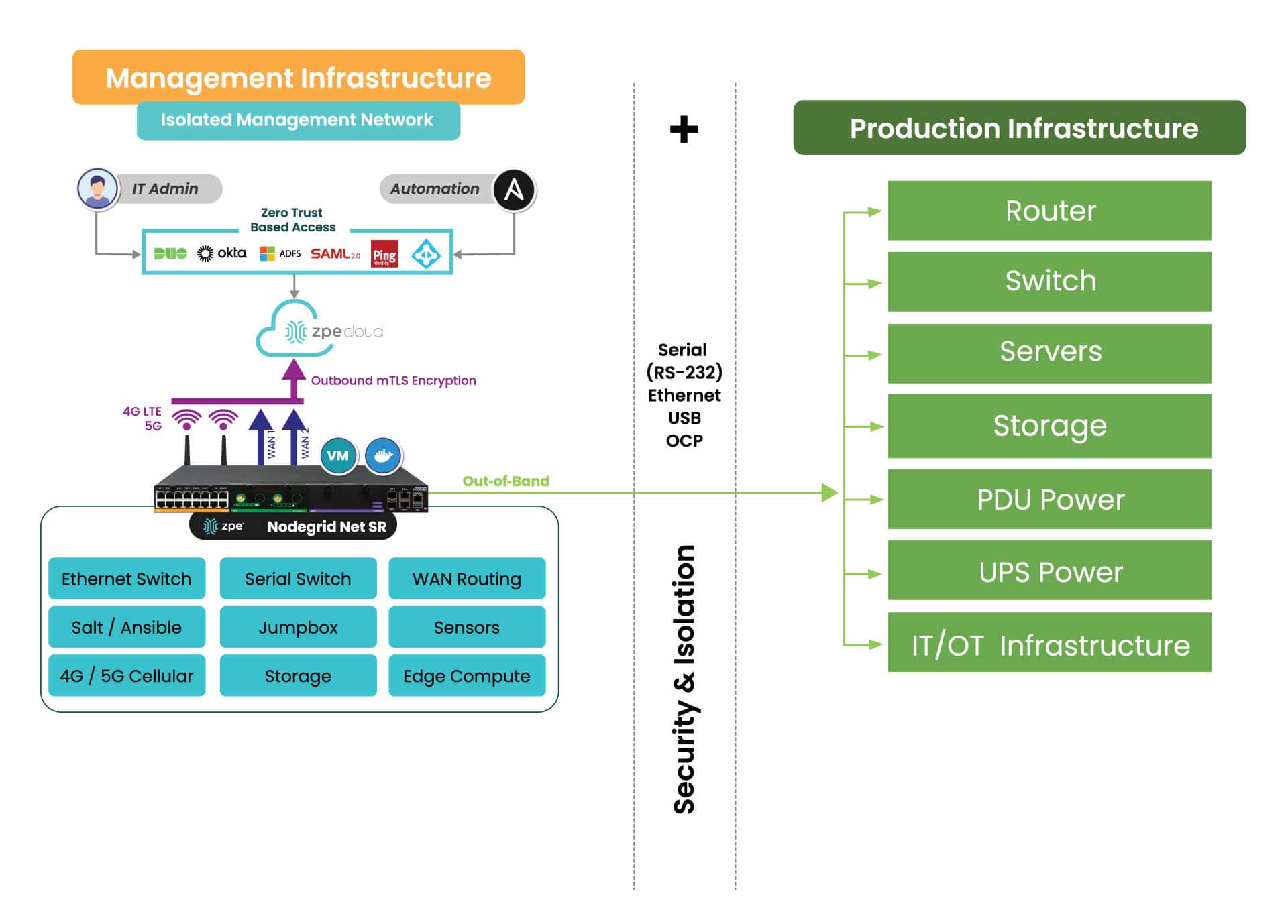
Understanding Serial Console Interfaces
A serial console (also known as a console server or terminal server) is a device that allows admins to manage critical network infrastructure like servers, routers, switches, and power distribution units (PDUs) without needing to log in to each piece of equipment individually. It also provides out-of-band (OOB) management, which creates an isolated network dedicated to infrastructure orchestration and troubleshooting. Serial console interfaces help improve management efficiency, accelerate recovery from outages and cyberattacks, and isolate the control plane from malicious actors.
This blog defines serial console interfaces and describes their technological evolution before discussing the benefits of using a modern serial console solution.
What is a serial console interface?
The term serial console interface could mean different things depending on the context and who’s saying it.
1. Some people use this term to refer to the serial console’s management GUI (graphical user interface), which administrators use to view and control data center devices.
")
2. Others use this term to refer to the individual connections between a serial console and each managed data center device. In addition to traditional RS-232 serial interfaces, a serial console may support RJ45, KVM (keyboard, video, mouse), IPMI (intelligent platform management interface), and USB (universal serial bus) interfaces.

3. Another potential (but less common) use of the term is for the text-based console interface (also known as a CLI, or command-line interface) used to configure and manage data center devices without a GUI. The console interface could be accessed in several ways, such as through a serial console’s GUI, or via a Telnet or SSH (secure shell) client like PuTTY.

4. Finally, it’s quite common to use the term serial console interface to describe the entire serial console solution, from the hardware itself to its managed ports, GUI, and CLI. The serial console acts as an interface between the production network (a.k.a., the data plane) and the management network (a.k.a., the control plane).
For the purposes of this discussion, we will use this fourth definition of serial console interfaces.
The evolution of serial console interfaces
First-generation
The first generation of serial consoles provides the basics: unified management of multiple data center devices, and an OOB network connection (such as a dial-up modem or cellular SIM card) so management workflows don’t rely on the main production network. A Gen 1 serial console interface allows administrators to access the CLI for each connected device even if the production network goes down from an ISP outage, equipment failure, or cyberattack. However, these serial consoles lack many of the advanced features required for modern network infrastructures, such as hardware encryption, third-party integrations, and automation capabilities. They typically only support standard RS-232 serial interfaces using a specific pinout.
")
Second-generation
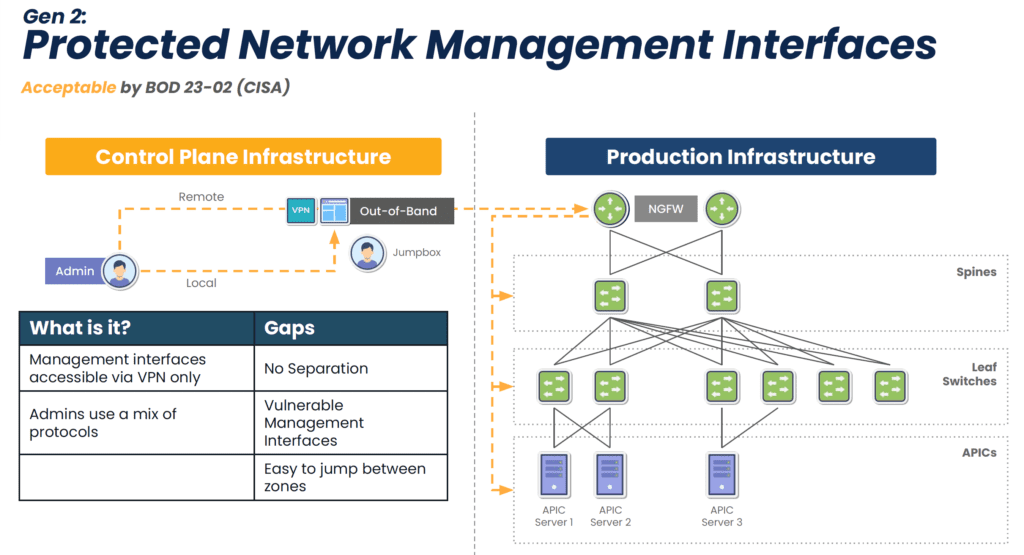
The second generation added built-in security features, advanced authentication methods, and the ability to manage multi-vendor devices. Some vendors also added support for Python scripts and other automation, as well as zero-touch provisioning (ZTP) for supported end devices. However, Gen 2 serial console interfaces have closed architectures that prevent full automation of multi-vendor infrastructure. Their management GUIs are also typically only available as an on-premises virtual machine (VM), so remote administrators must be on the enterprise network or connected via VPN to access them.
Third-generation
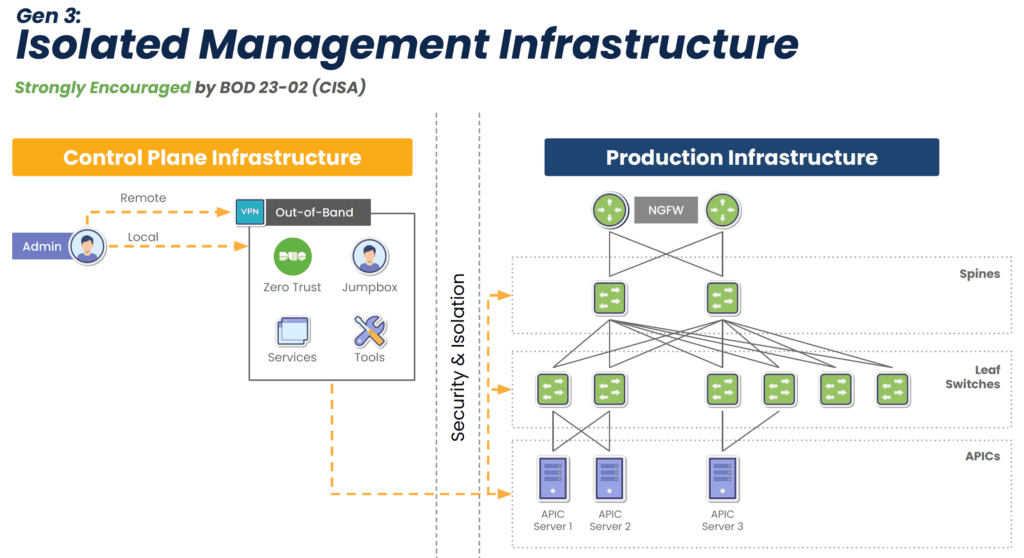
Third-generation serial consoles are completely vendor-neutral, so they can control – and extend automation to – every physical and virtual asset in your environment. They use high-speed OOB network interfaces such as 5G cellular, and offer cloud-based management software so teams can manage and troubleshoot remote infrastructure from anywhere in the world. Gen 3 serial console interfaces are built on an open, x86 Linux-based architecture that supports third-party integrations and can run other vendors’ software. They accommodate legacy pinouts to control a variety of devices, such as PDUs, IPMI devices, and environmental monitoring sensors, and also feature modules that allow you to customize or modify interface types.

Gen 3 serial consoles have enterprise-grade security features like an encrypted disk and TPM 2.0 security. They also support integrations with Zero Trust providers for multi-factor authentication (MFA) and single sign-on (SSO). The third generation enables end-to-end network infrastructure automation using third-party tools like Ansible, Chef, and Puppet, as well as customer-built tools in VMs, Docker, or Kubernetes. Gen 3 serial console interfaces are essentially infrastructure multi-tools capable of running and deploying any solution, at any time, from anywhere.
The benefits of a Gen 3 serial console interface
The latest generation of serial consoles provides three major advantages:
- Improved management efficiency. A vendor-neutral serial console allows administrators to manage infrastructure workflows and automation for large, complex network architectures from a single pane of glass. Teams can also extend automation to every infrastructure device, even legacy solutions that wouldn’t support it otherwise.
- Reduced network downtime. With fast, reliable Gen 3 OOB, infrastructure teams have a lifeline to troubleshoot and recover remote infrastructure when the WAN (wide area network) or LAN (local area network) goes down. They can remotely power-cycle frozen devices, view environmental monitoring logs, and automatically provision replacement equipment without the time or expense of on-site visits.
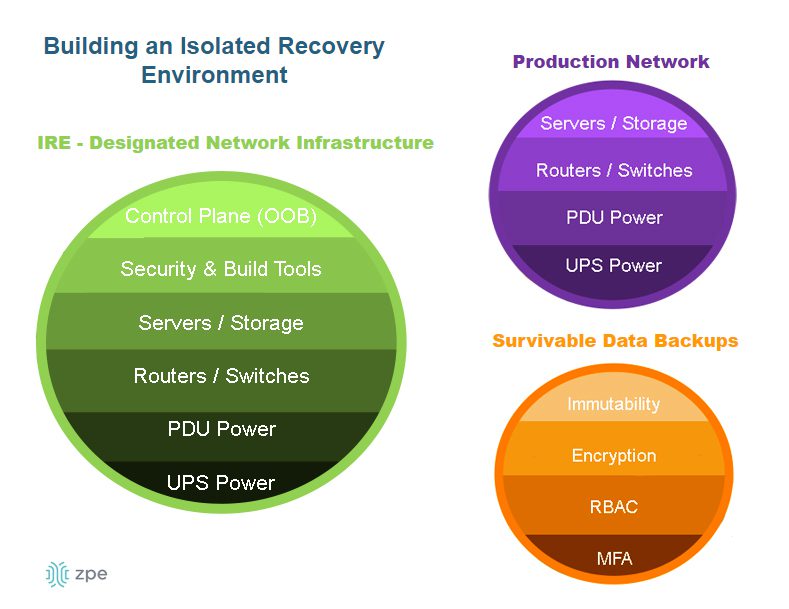
- Isolated management infrastructure (IMI). Gen 3 OOB creates an isolated control plane for network infrastructure, which helps protect management interfaces from malicious actors who have breached the production network. It also helps establish an isolated recovery environment (IRE) where teams can rebuild and restore systems without risking re-infection or re-compromise.

Want to learn more about serial consoles?
Gen 3 serial console interfaces like the Nodegrid Serial Console (NSC) from ZPE Systems use vendor-neutral architectures and end-to-end automation capabilities to help companies improve operational efficiency and network resilience. To learn more about how a Gen 3 solution can help with your biggest infrastructure pain points, watch a Nodegrid demo.