rednesp is São Paulo’s Research and Education Network, serving more than 20 universities, research institutions, and innovation centers across Brazil. rednesp provides critical network infrastructure for the scientific community, meaning uptime and performance are key.
Operating a research and education network at scale, however, comes with unique challenges. End users need to have reliable connectivity for performing experiments and simulations, and they need a high-performance network for transferring large datasets and running distributed workloads. Any outage could disrupt innovative work and potentially delay scientific breakthroughs. For rednesp, this means having total operational control over the infrastructure, and ZPE Systems’ out-of-band is the only solution that can live up to their needs.
Read the case study now to see how ZPE’s independent management plane, rapid recovery, and centralized control deliver the always-on, high-performance connectivity that rednesp’s community depends on.
Managed service providers rely on remote access to keep customer environments running. VPNs, jump hosts, and centralized access tools make it possible to manage infrastructure across dozens or hundreds of sites without leaving the operations center.
But during outages, these tools can become part of the problem. When remote access depends on the production network, even routine failures can cut off the access engineers need to fix issues. What should be a quick recovery turns into a prolonged outage that requires on-site intervention.
Here are some of the most common failure scenarios MSPs face, and a look at the architecture that helps overcome them.
Routing Failures
Many routing failures stem from human error. According to 2025 research from the Uptime Institute, almost 40% of organizations suffered a major outage due to human error in the last three years. If a core router experiences a misconfiguration, control-plane crash, or routing instability, the network paths that connect engineers to the environment may disappear entirely.
Common examples include:
BGP route leaks or policy errors that remove upstream connectivity
OSPF adjacency failures that break internal routing between segments
VRF or VLAN misconfigurations that isolate management subnets
Routing table corruption during firmware upgrades
In these situations, VPN sessions drop immediately because the path between the engineer and the VPN gateway no longer exists. Worse, the router responsible for the failure may be fully operational from a hardware perspective and all it needs is a configuration correction. But engineers can’t gain remote console access to make this correction.
What should have been a 30-second configuration rollback becomes a multi-hour recovery effort.
Firewall Policy Errors
Firewall misconfigurations are one of the most common causes of remote access loss. Modern firewalls enforce highly automated policies through orchestration systems, policy templates, or automated compliance updates. These systems are great for consistency, but they introduce new failure modes.
A few examples include:
A security policy update accidentally blocking VPN management traffic
A zone-based firewall rule preventing internal device access
A NAT configuration error breaking inbound VPN connections
An automated policy sync overwriting existing allow rules
A lot of times, the firewall itself remains online and functional. The only issue is a misconfigured rule. Because the firewall sits directly in the remote access path, it becomes unreachable (just like the router we mentioned in the previous example). Engineers may be able to confirm the outage through monitoring systems, but without access to the firewall CLI or console, there is no way to correct the configuration remotely.
WAN or ISP Outages
Many MSP environments rely on customer WAN circuits to provide remote management access. Failures on these circuits cut remote connectivity regardless of the health of the internal infrastructure. Fiber cuts, for example, are one of the most common causes of outages that last 48 hours or longer.
Common scenarios include:
Carrier fiber cuts (looking at you, backhoe operators 😜)
DDoS mitigation events that disrupt inbound traffic
Image: Behold, the natural predator of fiber cables.
Customer networks may still be operating internally. Devices are running, servers are responding, and monitoring systems might still be collecting metrics locally. But engineers outside the network have no path into the environment. Even simple recovery actions like restarting an edge router or verifying a routing table may require on-site access.
Authentication Infrastructure Failures
Jump host environments depend on centralized authentication systems such as Active Directory, LDAP directories, or identity federation platforms. When these go down, engineers get locked out of their own management infrastructure.
Engineers can probably still reach the jump host in these scenarios, but they can’t log in because authentication fails. The result is the same: engineers can see the problem, but they can’t access the systems required to fix it.
DNS and Management Service Failures
Another subtle failure mode occurs when core infrastructure services degrade. Many management environments rely on DNS resolution, certificate validation, or internal service discovery mechanisms.
If DNS services fail or management service endpoints become unavailable:
Jump hosts may not resolve device hostnames
SSH connections fail due to certificate validation errors
Automation platforms lose connectivity to managed infrastructure
The devices themselves may still be reachable, but the tools engineers rely on stop working.
The Pattern Behind These Failures
These scenarios might seem unrelated, but they all share the same root issue: remote access depends on the production network.
When that network fails, whether due to routing, security, WAN, or service issues, engineers lose the ability to reach the infrastructure they need to fix. That’s when recovery slows down, truck rolls and labor costs increase, and SLA risks rise.
Image: When remote management access depends on the production network, outages cut off both links, leaving engineers unable to remotely recover.
What should be routine incidents turn into operational disruptions. Engineers are unable to gain remote console access for recovery, and any tools running on the production network become useless. The only way to bring the network back online is to put engineers on site.
How To Overcome The Top Network Failure Scenarios
VPNs and jump hosts are effective, and they’re useful tools for day-to-day operations. But, MSPs won’t be able to overcome these top network failure scenarios if they rely on VPNs and jump hosts as the only path to critical infrastructure.
The key is being able to maintain access even when the production network goes down.
Image: A dedicated out-of-band management path ensures engineers can remotely access their infrastructure, even when there’s a complete outage on the production network.
What Can Engineers Do With Out-of-Band?
Modern OOB and IMI setups allow engineers to see what’s going on and act, no matter what’s happening on the production network.
This dedicated management path means MSP teams can:
Access device consoles directly, even if routing is broken
Perform config rollbacks on routers and firewalls after failed changes
Power-cycle/reboot equipment remotely (no on-site help needed)
Troubleshoot WAN failures from inside the network
Maintain access to infrastructure during ISP outages or authentication failures
Outages that would normally drag on for hours can now be resolved in minutes from the NOC. Check out our demonstration video to see what this looks like in action!
Calculate the Impact of MSP Network Failures
The most important question to ask is: can your engineers still reach the infrastructure when the network itself is down?
If the answer is no, it’s time to calculate how much these failure scenarios are costing in truck rolls, labor, and SLA penalties.
Use the MSP Downtime Cost Worksheet to quantify your exposure and see how much faster recovery could improve your margins.
MSPs and Managed Network Service providers depend on remote access every day. Engineers connect to firewalls, routers, switches, hypervisors, and servers across dozens or even hundreds of customer environments. It’s a core function of operations, and without it, MSPs just wouldn’t exist.
The foundation of the remote access model is familiar for many providers: VPN tunnels combined with jump hosts or bastion servers. These tools allow engineers to log into a centralized environment and reach infrastructure across customer networks. This model works reasonably well when there are few customers. But as MSPs add sites, scale their customer base, and deploy more infrastructure, this traditional model becomes unmanageable.
Let’s find out why by looking at how VPN and jump host architectures actually work during real-world failure scenarios.
The MSP Remote Access Model
Most MSP/MNS environments rely on a layered remote access architecture. Engineers connect through a VPN gateway hosted either by the MSP or the customer environment. Once authenticated, they reach an internal jump host or bastion server that acts as a controlled entry point to the network infrastructure.
From the jump host/bastion server, they access infrastructure including:
Edge routers and firewalls
Core switches
Hypervisors and storage systems
Monitoring servers
Identity services
Virtual infrastructure platforms (like VMware, Microsoft Hyper-V, etc.)
Image: MSP remote access relies on the very infrastructure it manages.
This architecture has some benefits. It centralizes access control for the specific customer environment, somewhat simplifies credential management, and allows security teams to enforce authentication policies before engineers reach sensitive systems.
But remote access relies on the assumption that all of this production infrastructure remains operational.
What happens when it fails?
When In-Band Management Breaks: Common Failure Scenarios
VPNs and jump hosts operate entirely in-band, meaning they rely on the same network infrastructure they are meant to manage.
We covered this dependency at length in our last MSP article. Essentially, in-band management is cut off during failures, turning small issues into big outages that eat into MSP margins. And there’s a whole range of failures that can occur. Here are just a few of the common scenarios that lead to long outages and truck rolls:
Routing failures can entirely remove the path between engineers and the environment. A BGP misconfiguration, OSPF failure, or even a bad firmware update can drop VPN sessions instantly. The device causing the issue may still be running, but without access, engineers can’t fix it.
Firewall policy errors often block management traffic. A single misapplied rule or automated update can cut off access to internal systems. The firewall is online but unreachable, making a simple rule change impossible without on-site help.
WAN or ISP outages eliminate remote connectivity altogether. Even if the internal network is still functioning, engineers outside the environment have no way in. What should be a quick fix becomes a truck roll.
Authentication failures can lock engineers out of jump hosts, even when systems are otherwise healthy. If identity services like Active Directory or LDAP are unavailable, login attempts fail and troubleshooting stops.
Core service failures, such as DNS or certificate validation issues, can also break access indirectly. Devices may still be reachable, but the tools used to connect to them stop working.
We’ll break these scenarios down further in a separate article, but the pattern is clear: Even when infrastructure is still running, engineers lose the ability to reach it when it matters most.
Why the Problem Gets Worse as MSPs Scale
Let’s set aside the fragility of this in-band remote access model and talk strictly about scale. When you’re managing dozens of customer environments, each introduces more VPN gateways, firewalls/policies, routing domains, identity integrations, etc.
That simple remote access model turns into a highly distributed patchwork of VPN tunnels, jump hosts, bastion servers, and authentication systems spanning multiple networks. It doesn’t take a large leap of the imagination to see why this doesn’t scale.
Access is Fragmented
Engineers rarely connect to a single management environment (unless of course they’re using ZPE Cloud). Instead, they maintain separate access paths for each customer, which looks like this:
Different VPN clients or portals
Separate credential sets
Unique bastion hosts
Different network segmentation models
Image: MSPs need to juggle multiple access paths, credentials, and infrastructure for different customers.
Troubleshooting a single outage may require navigating several access layers before even reaching the affected device. This slows response time and increases the likelihood of access failures during incidents.
Ops Overhead Grows
As environments get bigger, so does the job of maintaining access infrastructure. MSP teams need to set up and maintain VPN gateways, manage identity federation between organizations, monitor jump host infrastructure, rotate/secure access credentials, and fix connectivity issues.
It’s easy for engineers to spend as much time maintaining the access system as they do managing the infrastructure itself.
Recovery Delays Multiply Across Sites
One incident is manageable. But imagine there’s a regional ISP outage or widespread software bug that takes down a dozen customer sites. Engineers are forced to:
Queue troubleshooting tasks across environments
Dispatch all their technicians to remote locations
Coordinate access with third-party facilities
Work around broken VPN connectivity
Image: Software bugs, like the one that caused 2024’s CrowdStrike outage, can render mission-critical PCs useless until remedied by on-site intervention.
As the number of managed sites grows, these recovery delays compound and the limitations of traditional remote access become clear.
Operational Costs Rise Quietly
When managing so many sites and incidents per year, the financial impact adds up. That practical remote access solution becomes a hefty cost of doing business, especially when incidents require additional troubleshooting hours, escalations to senior engineers, on-site recovery/travel expenses, and SLA penalties/credits.
Engineering Turns Into Firefighting
One of the biggest impacts on business is when engineers can no longer focus on optimizing the network, automating jobs, or rolling out security enhancements, and instead have to focus on putting out ops fires. When strategic improvements take a back seat to remote access failures and reactive outage recovery, teams become less productive.
How To Fix It: Separate Management From Production
Out-of-band architectures introduce a separate management path that operates independently of the production network. Instead of relying solely on VPN connectivity through the customer infrastructure, engineers can reach devices through a dedicated management plane designed specifically for recovery and operational control. This includes:
Direct console access to network and other devices
Independent connectivity using secondary and tertiary WAN links
Centralized management gateways that remain reachable during major outages
This management plane is reachable via 5G/cellular, satellite (like Starlink), secondary ISP, and other links. Modern serial console servers, like the Nodegrid Serial Console Plus, also include enterprise-grade security features like multi-factor authentication and zero trust controls, and isolation to keep the management plane completely hidden from threats. MSPs remain in control whether they’re battling a widespread outage or active cyberattack.
Image: Out-of-band management allows MSPs to securely connect to infrastructure, even when the production network fails.
If routing breaks, engineers can still reach the router console.
If firewall policies block access, engineers can log in through the out-of-band path and correct the rule.
If the WAN circuit fails entirely, cellular/satellite connectivity still provides a path into the environment.
The key difference is that management access no longer depends on the health of the production network. Management access becomes completely independent and always reachable.
Simplify Operations Across Many Environments
Out-of-band helps address the operational complexity that scales with traditional in-band management. Engineers no longer need to juggle separate VPNs, credentials, jump hosts, etc. for each customer. They get one management infrastructure that centralizes access and standardizes connectivity across sites. MSP teams get to:
Maintain consistent access workflows across customers
Enforce centralized authentication and authorization policies
Audit administrative activity across all managed environments
Reduce the number of tools required to access infrastructure
Image: Out-of-band helps MSPs streamline day-to-day operations by eliminating the need to juggle multiple VPNs, credentials, jump hosts, and other access layers for each customer.
For MSPs that use the secure management portal ZPE Cloud, they can log in once and simply click to switch between customer environments (here’s a cool video showing how easy it is). This simplifies day-to-day operations and outage recovery, and helps teams become more productive.
Combine Resilient Access and Centralized Control
Modern platforms combine out-of-band connectivity with centralized orchestration to provide both operational resilience and secure access management. Solutions like ZPE’s Nodegrid are designed to act as a dedicated management gateway for distributed infrastructure. Within this single platform, MSPs can:
Maintain always-available console access to networking, computing, and their full stack of devices
Connect to remote sites through independent cellular or secondary links
Enforce role-based access controls and identity integration
Record and audit administrative sessions with detailed logging
Manage thousands of devices across geographically distributed environments
Image: ZPE’s Nodegrid devices combine 9+ functions into one and create an isolated management infrastructure ideal for secure, reliable access to production assets.
This architecture effectively creates an isolated management plane that remains available even when the production network is experiencing failures.
Make Recovery Predictable Instead of Reactive
For MSPs, the real advantage of this model is operational. When engineers know they will always be able to reach infrastructure during an outage, recovery becomes faster and more consistent. Troubleshooting can begin immediately, configuration errors can be corrected remotely, and incidents that used to require on-site intervention can be resolved from the operations center.
At scale, these improvements translate directly into measurable outcomes:
Faster mean time to resolution
Fewer truck rolls
Lower operational overhead
Improved SLA performance
In other words, the architecture changes how teams handle operations and how efficiently MSPs grow their business.
Understanding the Financial Impact
For many providers, the operational costs of traditional remote access models remain hidden until they analyze how often incidents require on-site intervention or extended troubleshooting.
To help MSP teams quantify this impact, we created a simple worksheet that estimates the true cost of downtime across managed environments.
It walks through common inputs such as incident volume, technician time, truck roll costs, and SLA penalties to calculate the annual financial impact of outage recovery.
From there, it shows how resilient management infrastructure can significantly reduce those costs. Download it now to analyze your costs and see your potential ROI by adopting out-of-band.
Managed service providers have never had more technology at their disposal. Real-time alerts stream in from monitoring platforms. Engineers can troubleshoot off-site using remote access tools. Automation handles patching, configuration updates, and routine maintenance. On paper, today’s MSP toolkit is powerful and mature.
But when serious network outages happen, many providers still struggle to get back to normal. Restoring services can require hours of coordination, travel, and escalation. It’s this disconnect that raises an important question:
If the tools are better than ever, why is it so hard to recover from downtime?
There’s A Hidden Dependency Inside Traditional Remote Management
Some of the tools MSPs have at their fingertips are VPN tunnels, remote desktop sessions, and internally hosted jump environments. These are effective for routine maintenance. But this traditional remote management approach hides a major dependency: it all relies on the production network.
This is called in-band management, and it’s the biggest obstacle MSPs face when trying to get back online. In-band management is where admin access depends on the very infrastructure it grants access to. It works great when everything is working. But if a core router fails, firewall policies break, a WAN link drops, or an upstream provider experiences disruption, access disappears entirely.
Image: With in-band management, remote admin access is cut off when there is a production network outage.
At the basic level, this is a problem with the underlying management architecture (or lack thereof). Here are common obstacles that stem from in-band management and make MSPs struggle with network downtime.
Minor Issues Easily Turn Into Long Interruptions
Monitoring and alerting platforms excel at detecting problems. They can identify packet loss, device failures, link instability, and performance degradation within seconds. Engineers are immediately in the loop when something goes wrong.
The problem is these systems don’t provide the ability to act. If routing fails or firewall rules change unexpectedly, engineers lose the remote path needed to investigate. If an ISP circuit drops, VPN access vanishes with it. If DNS or authentication services become unavailable, login attempts stall.
Alerts keep coming in, dashboards light up, and customer complaints keep the phones ringing. But without direct device-level access, there’s no way to remotely reach the underlying infrastructure. What would have been a few minutes of troubleshooting turns into a prolonged service event requiring on-site support.
Physical Access Turns Into A Waiting Game
When remote access fails, on-site intervention becomes the only option, but this can also stand in the way.
Technicians often need to:
Drive several hours to the colocation or branch facility
Wait for security approval or badge verification
Schedule access windows during limited hours
Coordinate with third-party support
Navigate strict escort requirements
Deal with weather delays, travel logistics, or facility staffing shortages
Once they arrive, they also might have to wait longer for cage access, compliance checks, or coordination with other on-site personnel. Meanwhile, customer services remain degraded or offline.
No amount of monitoring can compensate for losing the path to the devices themselves.
Scale Turns Occasional Friction into Business Risk
These delays might feel like a small inconvenience. An engineer goes on site, fixes the problem, and moves on. It seems manageable.
But as MSPs scale, the friction compounds as each outage consumes:
High-value engineering hours
Travel budgets
SLA margin buffers
Customer satisfaction and positive reviews
As incident volume grows, recovery delays begin to affect staffing efficiency and profitability. Travel time expands. Skilled engineers spend more hours away from high-value work. Response windows widen, and maintaining consistent service-level performance becomes more difficult. The “manageable” approach becomes a structural drag on growth.
Traditional in-band management does not scale cleanly. It scales cost, complexity, and operational risk.
Why Better Tools Alone Won’t Solve the Problem
It’s tempting to think that you can solve the problem with more monitoring, automation, remote software, or other investments. But if you can’t reach the infrastructure when it matters most, no amount of tooling will save you.
The core issue is this: How do you get dependable, guaranteed access during failures? In even simpler words, how do you recover without rolling a truck?
Image: When MSPs rely on in-band management, they can be easily cut off from remote admin access to customer sites.
Rethinking What “Prepared for Outages” Really Means
Resilient management access doesn’t mean what it did 20 years ago, when it was enough to plug in a console server and modem to be able to fix 90% of incidents. This outdated approach relies at least partly on production infrastructure, and even though out-of-band devices are used, they’re not set up on a proper out-of-band network. MSPs using this management model (and many still do) are only kind of prepared for outages…but not really.
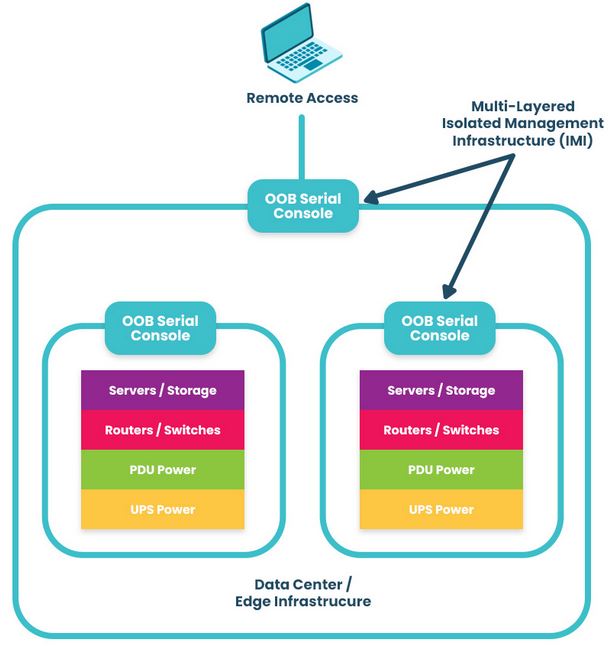
True resilience requires physical and logical separation between management access and production traffic. Instead of relying solely on in-band connectivity, forward-looking MSPs are deploying dedicated out-of-band and isolated management infrastructure (IMI). This approach creates a separate, resilient access path that remains available even when the primary network fails. In other words, MSPs stay in control no matter what disruptions occur.
Image: With dedicated out-of-band and isolated management infrastructure, MSPs can remotely access any managed device even during complete production network outages.
This architecture enables engineers to:
Maintain console-level access during WAN outages or cyberattacks
Remotely access power and BIOS controls for hard reboots
Reach network devices even if routing is misconfigured
Begin immediate troubleshooting and recovery without going on site
Image: ZPE Systems’ Nodegrid allows MSPs to easily deploy out-of-band and IMI across branch, colocation, and data center sites.
Out-of-band and IMI help MSPs pivot from a reactive recovery posture to a proactive, engineered-resilience approach. But one major hurdle remains: How do you build this architecture?
Solutions like ZPE Systems’ Nodegrid are built specifically for setting up a proper out-of-band network and IMI. Nodegrid devices combine all the functions necessary, like routing, switching, cellular/satellite, and others, with an on-prem or cloud management model. In fact, Nodegrid can be used to set up an out-of-band network in less than an hour.
Beyond remote access, Nodegrid integrates identity enforcement, granular authorization, session logging and auditing, and dozens of enterprise-grade security features directly into its architecture. That means MSPs improve operational recovery and security posture simultaneously.
With out-of-band and IMI, MSPs can be confident that they’re prepared for any type of outage.
Calculate the Real Cost of Your Recovery Model
How much are outages actually costing you in truck rolls, labor, and SLA penalties? Get our free download to calculate your current costs and how much you could save by switching to Nodegrid. It only takes a few minutes. Download the guided walkthrough now!
Mercado Libre, la plataforma de comercio electrónico y fintech más grande de América Latina, da soporte a más de 148 millones de usuarios con servicios de compras en línea, pagos y logística. Con más de 200 unidades operativas en toda la región, el uptime es crítico; un solo minuto de downtime puede retrasar envíos, paralizar pagos y afectar la confianza del cliente.
¿El desafío? Solo el 25 % de las unidades cuenta con personal de TI dedicado, lo que hace que las caídas del sistema sean costosas y lentas de resolver. Las fallas de Internet o de los enlaces del centro de datos pueden derribar aplicaciones principales, mientras que los errores de configuración en dispositivos clave pueden tardar hasta un día entero en solucionarse. Mercado Libre necesitaba una forma de simplificar la gestión a escala, garantizar la continuidad del negocio y evitar costosas intervenciones presenciales.
Al adoptar la plataforma Nodegrid de ZPE Systems, Mercado Libre obtuvo conectividad out-of-band basada en LTE, failover seguro hacia los centros de datos y gestión centralizada en la nube. El resultado es una mayor resiliencia, una recuperación más rápida y menos desplazamientos técnicos a campo — o, en otras palabras, convertir el uptime en una ventaja competitiva para la economía digital de América Latina.
Resultados clave:
Continuidad del negocio: Los envíos y pagos siguen fluyendo durante las caídas de red
Recuperación rápida: Las correcciones remotas evitan más de 24 horas de downtime
Eficiencia: Implementaciones más rápidas y menos visitas presenciales
“Todos en la unidad quedaron impresionados. El LTE integrado asumió la conexión automáticamente y la distribución continuó con normalidad. La solución de ZPE se pagó por sí sola con solo esta caída de red.” – Evandro Soares Correia, Jr. – Administrador de TI, Mercado Libre
O Mercado Livre, a maior plataforma de e-commerce e fintech da América Latina, atende a mais de 148 milhões de usuários com serviços de compras online, pagamentos e logística. Com mais de 200 unidades operacionais em toda a região, a alta disponibilidade (uptime) é crítica; um único minuto de inatividade (downtime) pode atrasar envios, paralisar pagamentos e impactar a confiança do cliente.
O desafio? Apenas 25% dessas unidades possuem equipe de TI dedicada, o que torna as quedas de rede custosas e demoradas para serem resolvidas. Falhas de internet ou nos links do data center podem derrubar aplicações essenciais, enquanto erros de configuração em equipamentos críticos podem levar até um dia inteiro para serem corrigidos. O Mercado Livre precisava de uma maneira de simplificar a gestão em escala, garantir a continuidade dos negócios e evitar intervenções presenciais caras.
Ao adotar a plataforma Nodegrid da ZPE Systems, o Mercado Livre obteve conectividade out-of-band via LTE, failover seguro para data centers e gerenciamento centralizado em nuvem. O resultado é uma resiliência muito maior, recuperação acelerada e menos deslocamentos técnicos a campo — ou, em outras palavras, a transformação do uptime em uma vantagem competitiva para a economia digital da América Latina.
Principais resultados:
Continuidade de Negócios: Envios e pagamentos continuam fluindo durante as quedas de rede.
Recuperação Rápida: Correções remotas evitam mais de 24 horas de inatividade.
Eficiência: Implantações mais rápidas e menos visitas presenciais.
“Todos na unidade ficaram impressionados. O LTE integrado assumiu a conexão automaticamente e a distribuição continuou normalmente. A solução da ZPE se pagou com apenas essa única queda de rede.” – Evandro Soares Correia, Jr. – Administrador de TI, Mercado Livre
ISP security strategies often put a lot of armor around the production network. Firewalls, DDoS mitigation, traffic inspection, and redundancy are all designed to protect customer traffic and keep packets flowing.
But some of the most damaging outages and breaches don’t start in the production network. They start somewhere that’s much less visible and much more vulnerable, a place where one strike can easily get to all the vitals.
They start at the console.
The management plane is a foundational part of the security puzzle. It’s where engineers access routers, switches, and other critical networking gear. This plane also grants broad access and has much less security built around it. In other words, the management plane is usually the most powerful yet least protected part of the network.
Image: The Pyramid of Planes (Source: Cisco Press)
Why The Management Plane Is a High-Value Target
The management plane is where real control lives. Console access allows engineers to restore devices, change configurations, disable interfaces, and recover systems when things go wrong. It is literally what controls the entire network.
Yet for ISPs and many others, securing management access is treated as a secondary concern. Management traffic often rides on the same paths as production traffic. Access is granted broadly, credentials are reused, and visibility into what actually happens during a console session is minimal. This is especially true for POPs and last-mile sites where physical security and staffing are limited.
To an attacker, it’s minimal effort for maximum impact. They don’t need to exploit routing protocols or overwhelm links. With console access, they can simply reconfigure, disable, or erase devices.
Three Big Problems with Traditional Network Management
In-Band Management Creates A Huge Attack Surface
In-band management is where admin access shares the same network paths as customer traffic. An obvious problem with this is that when the production network fails (from a fiber cut, routing instability, or other incident), teams can’t access the devices they need to recover.
But from a security standpoint, there’s a bigger problem: the attack surface is much larger with in-band management. If an attacker breaches the production network, they’ve got a direct path to the management plane. It’s highly likely that they’ll move laterally from customer-facing systems to control interfaces. When an attacker controls an ISP’s network, they control the business, too.
Shared Access Gives Attackers Broad Control
In many environments, console access isn’t given the proper zero-trust treatment it deserves. Instead, it’s about convenience. Engineers, NOC staff, and third-party vendors will often share access paths, credentials, and devices without segmentation.
This is how small mistakes turn into major security events. A lack of segmentation means that all it takes is one set of credentials to be misplaced or stolen, and an attacker gains broad control. They can move laterally across devices, regional sites, and backbone routers faster than defenders can respond.
Poor Visibility Leaves Soft Spots…Soft
Breaches always come with the same question: What happened?
This is impossible to answer in traditional environments because it’s difficult to find the evidence. Legacy solutions lack detailed logs and audit trails, so there’s no way to get a clear picture of the attack. Security teams can’t reconstruct what happened, and compliance teams can’t find or produce any evidence. It’s like being blindfolded during an attack, but also unable to remove the blindfold after the fact.
When it’s impossible to figure out where the attack came from or how it transpired, it’s impossible to defend against the next one.
What If The Management Plane Was Designed Like A Security System?
Modern ISP environments require a security posture that treats the management plane for what it is: a critical system. It needs to:
Minimize the attack surface
Limit the blast radius of attacks
Offer full visibility in case of attack
Many ISPs are adopting an approach that gives them all of these capabilities. This involves setting up a management architecture that is completely dedicated to, well, management. Here’s what it looks like.
Gen 3 Out-of-Band Management for ISPs
Traditional out-of-band management was often little more than a backup modem bolted onto a console server. It solved one problem – getting in during an outage – but left many other problems untouched, especially around security, scale, and governance.
Gen 3 out-of-band management is fundamentally different.
Instead of acting as an emergency access tool, Gen 3 OOB is designed as a permanent, security-first management plane. It is physically and logically isolated from the production network, ensuring that management access doesn’t die when production goes offline. Even if the production network is actively under attack, the management plane remains reachable.
This architecture dramatically reduces the attack surface. Management traffic no longer traverses production links, and attackers who compromise customer-facing systems don’t automatically gain a path to administrative access. Independent connectivity, such as LTE, 5G, or satellite, ensures that access persists during fiber cuts, routing failures, or control-plane incidents.
The most important part is, Gen 3 OOB is built to operate at ISP scale. It supports centralized policy enforcement, secure remote access across thousands of sites, and consistent controls from backbone POPs down to last-mile cabinets. Management access becomes predictable, resilient, and defensible, giving teams real operational control that’s critical during emergencies.
Isolated Management Infrastructure
Out-of-band access alone isn’t enough if it’s not governed properly. This is where Isolated Management Infrastructure (IMI) comes in.
IMI extends the principles of Gen 3 OOB by applying zero trust security controls directly to the management plane. Every user, device, and session must continuously prove its identity and authorization. Instead of the typical castle-and-moat, “all or nothing” approach, management access is precise.
Engineers are granted access only to the devices and ports they need. Vendors receive temporary, segmented access that automatically expires. Sessions are logged, recorded, and tied to individual identities, creating a complete audit trail for security and compliance teams.
A big part of IMI is that it assumes that breaches will happen somewhere in the environment, and is designed to limit the blast radius when they do. If credentials are compromised, attackers cannot move laterally across sites or escalate privileges unchecked. Visibility ensures that suspicious activity is detected fast and investigated with confidence.
For ISPs, IMI brings the management plane in line with modern security expectations. It aligns with regulatory requirements, supports forensic investigations, and enables teams to operate securely without slowing down recovery or day-to-day operations.
Together, Gen 3 OOB and IMI create a management architecture that is resilient by design and secure by default.
See Why Nodegrid Is the Choice For ISP Network Management
Discover what goes into securing modern ISP networks with Nodegrid. Our guide, The Security Architecture That Makes Nodegrid Ideal for ISPs, breaks down what makes Nodegrid secure by design. Take a look at everything from multiple, dedicated OOB links that guarantee management access, to zero-trust enforcement, centralized policy control, and third-party vendor isolation.
Download the guide now to get the complete security picture.
For many ISPs, the most expensive part of an outage shows up on the road.
A router locks up at a remote POP, a fiber aggregation switch stops responding, or a misconfigured update takes a site offline. When the network goes down and impacts customers, the only way to recover is to send a technician to the site.
Truck rolls like these feel routine, but once you bring scale into the picture, they’re one of the biggest costs an ISP operator can incur.
Why Do ISPs Still Rely On Truck Rolls?
Many ISP networks still rely on physical intervention when something goes wrong, and it’s for one simple reason: when you lose access to the device, you lose control of the network.
Common scenarios include:
A router or switch becomes unreachable over IP
A software upgrade fails and the device doesn’t come back
A configuration change locks out remote access
Power cycles are needed, but there’s no remote power control
When the production network is down and there’s no independent way to reach the device, operations teams have no choice. Someone has to drive to the site.
The Technical Gaps That Force Truck Rolls
It’s not a lack of ops protocol or discipline that forces truck rolls. Instead, it’s a lack of proper management architecture that leaves several large technical gaps.
No Independent Access Path
Image: Traditional ISP management access is cut off when the main network goes down, forcing technicians to go on site.
Most ISP devices are managed over the same network they help provide. Because there’s no independent access path (like dedicated out-of-band management), when the network fails, so does access to the device itself. Recovery is only possible by restoring the very network that’s broken, and since the underlying infrastructure can’t be accessed remotely, someone has to physically connect to the devices that are causing issues.
Many failure states can only be resolved via the console:
Bootloader recovery
Rollback after a failed OS upgrade
Network lockouts caused by ACL or routing errors
Again, traditional approaches leave serial access dependent on the production network. When the network goes down, the only way to access the console is by physically connecting.
Here’s how one of ZPE’s IT & System Administrators addressed this exact scenario, but used out-of-band to recover remotely instead of going on site.
No Remote Power Control
When devices freeze or become unresponsive, a power cycle typically fixes the problem. But without power management best practices (and proper outlet mapping), a simple device reboot becomes a site visit.
Fragmented Tools
Console servers, power devices, and access controls are typically spread across different systems. That fragmentation slows recovery and increases human error, especially during high-stakes events like outages.
Why Truck Rolls Hurt Business More Than You Think
Direct Costs Add Up Fast
Between labor, fuel, scheduling, and overtime, it’s common for a single dispatch to cost thousands of dollars. What happens when this is multiplied across dozens or hundreds of remote sites? This approach becomes unmanageable and unscalable.
Operational Scalability Breaks Down
Growing networks means having more sites. This means:
More logistics
More staffing pressure
More risk during outages (especially after hours)
Eventually, growth becomes constrained by the ability to physically respond to failures.
Longer MTTR Puts SLAs at Risk
Every minute spent waiting for a technician is another minute of customer impact. Longer mean time to repair (MTTR) increases the risk of:
SLA penalties
Customer churn
Escalations with enterprise and wholesale clients
Technician Burnout
Skilled operational roles are already in short supply. But technicians quickly become burnt out when they’re constantly juggling high-stakes outages, 2 a.m. wakeup calls, and hours-long road trips (sometimes just to reset a device). This contributes to higher turnover and makes truck rolls even less sustainable.
What If Truck Rolls Weren’t the Default?
Imagine this scenario:
A core router stops responding at a remote site. Instead of opening a dispatch ticket:
The NOC connects to the device over an independent OOB network
Engineers access the serial console remotely
The device is power cycled if needed
Configuration is fixed and services are restored, without anyone leaving their chair
No driving. No waiting. No hours-long downtime.
This isn’t theoretical. It’s what happens when recovery is built into the architecture.
The Role of Out-of-Band and Isolated Management Infrastructure
Out-of-band management creates a dedicated, independent path to reach critical infrastructure, even when the production network is unavailable.
Creating a management plane that’s physically and logically separate from production infrastructure
Enforcing strong access controls
Providing consistent recovery workflows across sites
Together, they transform outage response from reactive (i.e., truck rolls) to controlled. If the alarm bells start ringing, technicians can respond instantly from wherever they are.
Key capabilities include:
Remote serial console access
Remote power control
Independent connectivity via cellular or satellite
Centralized access and auditing
How Nodegrid Helps ISPs Eliminate Truck Rolls
ZPE Systems’ Nodegrid is designed specifically for environments where uptime, scale, and remote recovery matter.
Nodegrid provides secure remote access to serial consoles and power controls from a single platform, so recovery doesn’t require multiple tools or manual workarounds. Check out the Raritan SX II Migration Video to see what it looks like.
Centralized Control at Scale
Engineers can manage thousands of distributed sites from a single interface, applying consistent policies and workflows across the network. Watch our ZPE Cloud demo to see how simple it is to monitor, troubleshoot, and push updates across global devices.
Faster Recovery, Fewer Dispatches
By enabling remote troubleshooting, remediation, and reboot capabilities, Nodegrid dramatically reduces the need for physical site visits.
See How Much You Can Save With This ROI Worksheet
This free worksheet shows three simple ways to calculate the cost of truck rolls, downtime, and recovery, and how much you can save by using ZPE Systems’ Nodegrid. Download now and you’ll also get access to the Zero-Downtime Migration Checklist — a practical guide to help you deploy the industry’s most resilient network management solution without disrupting services.
Fremont, Calif. — November 27, 2025 — ZPE Systems is proud to be named the Fastest Growing Vendor: Technology and Storage by Stock in the Channel, a leading platform for IT channel procurement and vendor analytics.
This award highlights ZPE Systems’ rapid growth and strong momentum as organizations modernize their network infrastructure and management solutions. ZPE’s ongoing expansion across enterprise, service provider, and hyperscale environments reflects the increasing demand for ZPE’s vendor-agnostic out-of-band management platform, which simplifies operations and strengthens resilience.
With ZPE Systems now part of Legrand, a global leader in electrical and digital infrastructure solutions, customers have a one-stop shop for end-to-end infrastructure, from power and racks to connectivity, out-of-band management, and cloud orchestration. This integration ensures customers benefit from world-class support, unified procurement, and a stronger portfolio designed to meet the demands of modern, distributed, and AI-driven networks.
“We’re honored to bring home the award for Fastest Growing Vendor in Technology and Storage,” said Mark Thomas, Channel Manager EMEA & APAC. “This award shows the trust our partners and customers place in ZPE Systems as they navigate increasingly complex environments and the very demanding requirements of AI architectures. Now as part of Legrand, we’re even better positioned to deliver comprehensive infrastructure solutions and exceptional value.“
ZPE Systems continues to deepen relationships across the channel, empowering partners with the Nodegrid platform for infrastructure management. Nodegrid provides customers with the industry’s most secure and complete remote out-of-band access, delivered through a combination of multi-function Nodegrid Serial Consoles, Nodegrid Services Routers, and ZPE Cloud SaaS for global infrastructure management. Nodegrid has become the go-to platform for enterprises seeking to reduce risk, accelerate deployments, and increase visibility across the entire network management lifecycle.
ZPE Systems extends its gratitude to Stock in the Channel for this recognition, and most importantly, to our partners, customers, and Channel Team for helping to achieve this milestone. We look forward to continuing our mission to deliver innovative management solutions that support the world’s most critical networks.
Mercado Libre, Latin America’s largest e-commerce and fintech platform, powers over 148 million users with online shopping, payments, and logistics services. With more than 200 sites across the region, uptime is critical; a single minute of downtime can delay shipments, stall payments, and impact customer trust.
The challenge? Only 25% of sites have dedicated IT staff, making outages costly and time-consuming to resolve. Internet or data center link failures can bring down core applications, while misconfigurations on key devices can take up to a full day to fix. Mercado Libre needed a way to simplify management at scale, ensure business continuity, and avoid expensive on-site interventions.
By adopting ZPE Systems’ Nodegrid platform, Mercado Libre gained LTE-based out-of-band connectivity, secure failover to data centers, and centralized cloud management. The result is stronger resilience, faster recovery, and fewer truck rolls — or in other words, turning uptime into a competitive advantage for Latin America’s digital economy.
Key outcomes:
Business Continuity: Shipments and payments keep flowing during outages
Fast Recovery: Remote fixes prevent 24+ hour downtime
Efficiency: Faster deployments and fewer on-site visits
“Everyone on-site was amazed. The built-in LTE automatically took over and distribution carried on like normal. The ZPE solution paid for itself with just this one outage.” – Evandro Soares Correia, Jr. – IT Admin, Mercado Libre
ZPE Systems delivers innovative solutions to simplify infrastructure managment at the datacenter, branch, and edge.
Learn how our Zero Pain Ecosystem can solve your biggest network orchestration pain points.