Data Center Scalability Tips & Best Practices
Data center scalability is the ability to increase or decrease workloads cost-effectively and without disrupting business operations. Scalable data centers make organizations agile, enabling them to support business growth, meet changing customer needs, and weather downturns without compromising quality. This blog describes various methods for achieving data center scalability before providing tips and best practices to make scalability easier and more cost-effective to implement.
How to achieve data center scalability
There are four primary ways to scale data center infrastructure, each of which has advantages and disadvantages.
4 Data center scaling methods
| Method | Description | Pros and Cons |
|---|---|---|
| 1. Adding more servers | Also known as scaling out or horizontal scaling, this involves adding more physical or virtual machines to the data center architecture. | ✔ Can support and distribute more workloads
✔ Eliminates hardware constraints ✖ Deployment and replication take time ✖ Requires more rack space ✖ Higher upfront and operational costs |
| 2. Virtualization | Dividing physical hardware into multiple virtual machines (VMs) or virtual network functions (VNFs) to support more workloads per device. | ✔ Supports faster provisioning
✔ Uses resources more efficiently ✔ Reduces scaling costs ✖ Transition can be expensive and disruptive ✖ Not supported by all hardware and software |
| 3. Upgrading existing hardware | Also known as scaling up or vertical scaling, this involves adding more processors, memory, or storage to upgrade the capabilities of existing systems. | ✔ Implementation is usually quick and non-disruptive
✔ More cost-effective than horizontal scaling ✔ Requires less power and rack space ✖ Scalability limited by server hardware constraints ✖ Increases reliance on legacy systems |
| 4. Using cloud services | Moving some or all workloads to the cloud, where resources can be added or removed on-demand to meet scaling requirements. | ✔ Allows on-demand or automatic scaling
✔ Better support for new and emerging technologies ✔ Reduces data center costs ✖ Migration is often extremely disruptive ✖ Auto-scaling can lead to ballooning monthly bills ✖ May not support legacy software |
It’s important for companies to analyze their requirements and carefully consider the advantages and disadvantages of each method before choosing a path forward.
Best practices for data center scalability
The following tips can help organizations ensure their data center infrastructure is flexible enough to support scaling by any of the above methods.
Run workloads on vendor-neutral platforms
Vendor lock-in, or a lack of interoperability with third-party solutions, can severely limit data center scalability. Using vendor-neutral platforms ensures that teams can add, expand, or integrate data center resources and capabilities regardless of provider. These platforms make it easier to adopt new technologies like artificial intelligence (AI) and machine learning (ML) while ensuring compatibility with legacy systems.
Use infrastructure automation and AIOps
Infrastructure automation technologies help teams provision and deploy data center resources quickly so companies can scale up or out with greater efficiency. They also ensure administrators can effectively manage and secure data center infrastructure as it grows in size and complexity.
For example, zero-touch provisioning (ZTP) automatically configures new devices as soon as they connect to the network, allowing remote teams to deploy new data center resources without on-site visits. Automated configuration management solutions like Ansible and Chef ensure that virtualized system configurations stay consistent and up-to-date while preventing unauthorized changes. AIOps (artificial intelligence for IT operations) uses machine learning algorithms to detect threats and other problems, remediate simple issues, and provide root-cause analysis (RCA) and other post-incident forensics with greater accuracy than traditional automation.
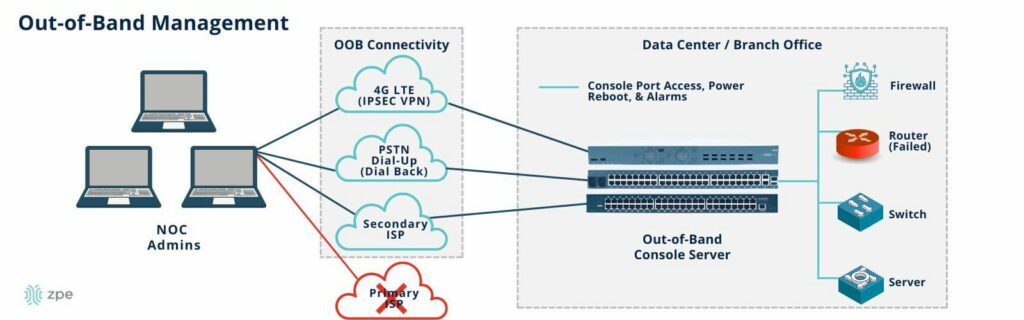
Isolate the control plane with Gen 3 serial consoles
Serial consoles are devices that allow administrators to remotely manage data center infrastructure without needing to log in to each piece of equipment individually. They use out-of-band (OOB) management to separate the data plane (where production workflows occur) from the control plane (where management workflows occur). OOB serial console technology – especially the third-generation (or Gen 3) – aids data center scalability in several ways:
- Gen 3 serial consoles are vendor-neutral and provide a single software platform for administrators to manage all data center devices, significantly reducing management complexity as infrastructure scales out.
- Gen 3 OOB can extend automation capabilities like ZTP to mixed-vendor and legacy devices that wouldn’t otherwise support them.
- OOB management moves resource-intensive infrastructure automation workflows off the data plane, improving the performance of production applications and workflows.
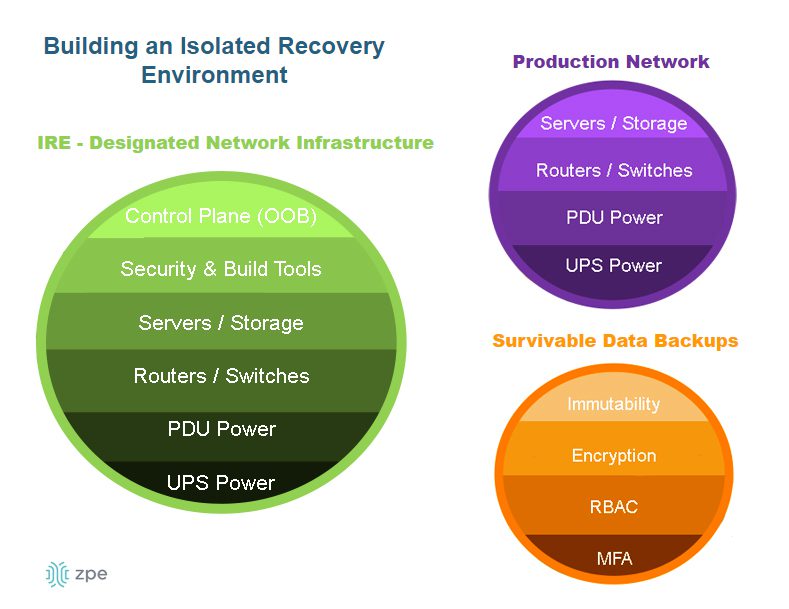
- Serial consoles move the management interfaces for data center infrastructure to an isolated control plane, which prevents malware and cybercriminals from accessing them if the production network is breached. Isolated management infrastructure (IMI) is a security best practice for data center architectures of any size.
How Nodegrid simplifies data center scalability
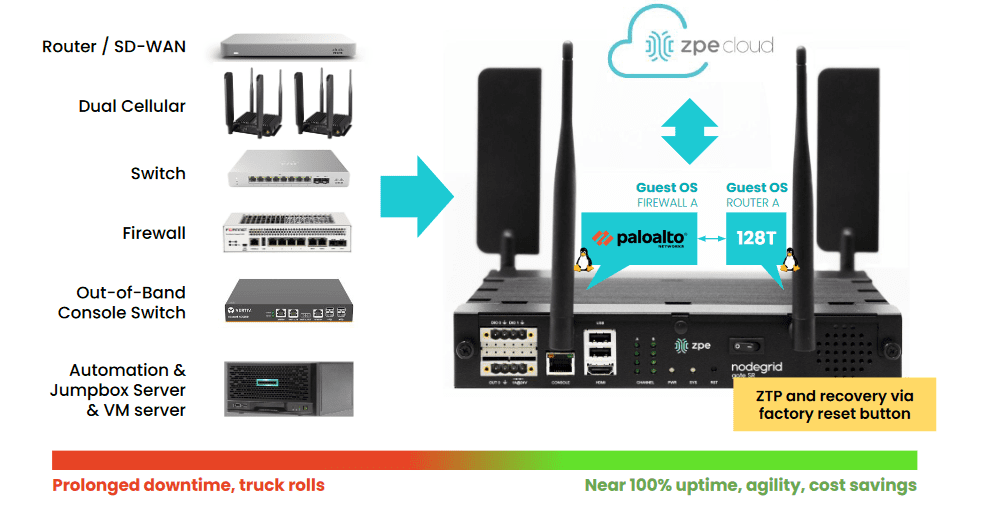
Nodegrid is a Gen 3 out-of-band management solution that streamlines vertical and horizontal data center scalability.
The Nodegrid Serial Console Plus (NSCP) offers 96 managed ports in a 1RU rack-mounted form factor, reducing the number of OOB devices needed to control large-scale data center infrastructure. Its open, x86 Linux-based OS can run VMs, VNFs, and Docker containers so teams can run virtualized workloads without deploying additional hardware. Nodegrid can also run automation, AIOps, and security on the same platform to further reduce hardware overhead.
Nodegrid OOB is also available in a modular form factor. The Net Services Router (NSR) allows teams to add or swap modules for additional compute, storage, memory, or serial ports as the data center scales up or down.
Want to see Nodegrid in action?
Watch a demo of the Nodegrid Gen 3 out-of-band management solution to see how it can improve scalability for your data center architecture.
")


")