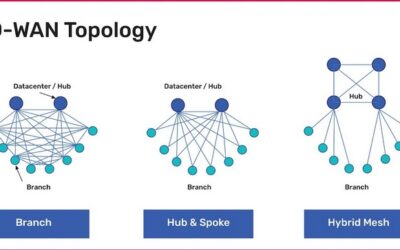
Learn about the most common SD-WAN deployment models with diagrams, pros and cons, and best practices to help organizations choose the right topology.
A Guide to SD-WAN Deployment Models
read more
Learn about the most common SD-WAN deployment models with diagrams, pros and cons, and best practices to help organizations choose the right topology.

An isolated recovery environment (IRE) uses designated network infrastructure and survivable data to help teams recover from ransomware faster and with less impact to the business.

SD-WAN benefits organizations through MPLS cost reduction, improved WAN performance, greater automation & orchestration, and enhanced security capabilities.
Compact, all-in-one branch gateways use environmental monitoring, OOB management, and vendor-neutral platforms to simplify retail network management.

Vapor IO is re-architecting the Internet with micro edge data centers. See how Nodegrid trims costs with automation & lights-out management.

The infrastructure orchestration and automation layer contains the tools and paradigms used to efficiently manage and control an automated network.

Let’s discuss how AIOps and machine learning help teams manage their automation and orchestration—and the massive amounts of data produced by their automated systems—more efficiently.

The infrastructure orchestration and automation layer contains the tools and paradigms used to efficiently manage and control an automated network.

Out-of-band management is a critical component of network design. Instead of using one of your main networks for administrative tasks, out-of-band (OOB) gives you admin access via a completely...

When it comes to infrastructure, network consolidation is becoming a must-have. This is especially true in hyper converged architectures, where streamlining operations means the difference between...