This guide to out-of-band management answers critical questions about what this technology is, why you need it, and how to choose the right solution.

Out-of-Band Management: What It Is and Why You Need It
read more
This guide to out-of-band management answers critical questions about what this technology is, why you need it, and how to choose the right solution.
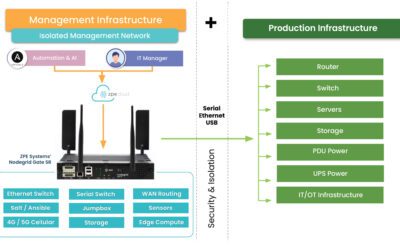
Isolated Management Infrastructure is the key to modern network resilience. Read about the gaps of existing approaches and why Big Tech trusts IMI.

Network resilience requirements have changed. James Cabe discusses why the new standard is Isolated Management Infrastructure.

Todd Atherton (Channel Sales Director) and Marc Westberg (Channel Sales Engineer) walk you through Nodegrid’s device clustering capabilities that let you get convenient, centralized management of your distributed fleet.

This guide discusses the edge computing requirements for hardware, networking, availability, security, and visibility to ensure a successful deployment.

This guide discusses IT infrastructure management best practices for creating and maintaining more resilient enterprise networks.

ZPE Systems is now a brand of Legrand! Read the full press release for details about the acquisition.
This guide to collaboration in DevOps provides tips and best practices to bring Dev and Ops together while minimizing friction for maximum operational efficiency.

This guide answers all your questions about terminal servers, discussing their uses and benefits before describing what to look for in the best terminal server solution.