What to do if You’re Ransomware’d: A Healthcare Example

This article was written by James Cabe, CISSP, a 30-year cybersecurity expert who’s helped major companies including Microsoft and Fortinet.
Ransomware gangs target the innocent and vulnerable. They hit a Chicago hospital in December 2023, a London hospital in October the same year, and schools and hospitals in New Jersey as recently as January 2024. This is one of the biggest reasons I’m committed to stopping these criminals by educating organizations on how to re-think and re-architect their approach to cybersecurity.
In previous articles, I discussed IMI (Isolated Management Infrastructure) and IRE (Isolated Recovery Environments), and how they could have quickly altered outcomes for MGM, Ragnar Locker victims, and organizations affected by the MOVEit vulnerability. Using IMI and IRE, organizations find that the key to not only speedy recovery, but also to limiting the blast radius and attack persistence, is isolation.
Why is isolation (not segmentation) key to ransomware recovery?
The NIST framework for incident response has five steps: Identify, Protect, Detect, Respond, and Recover. It’s missing a crucial step, however: Isolate. Stay tuned for a full breakdown of this in my next article. But the reason this is so critical is because attacks move at machine speed, and are very pervasive and persistent. If your management network is not fully isolated from production assets, the infection spreads to everything. Suddenly, you’re locked out completely and looking at months of tedious recovery. For healthcare providers, this jeopardizes everything from patient care to regulatory compliance.
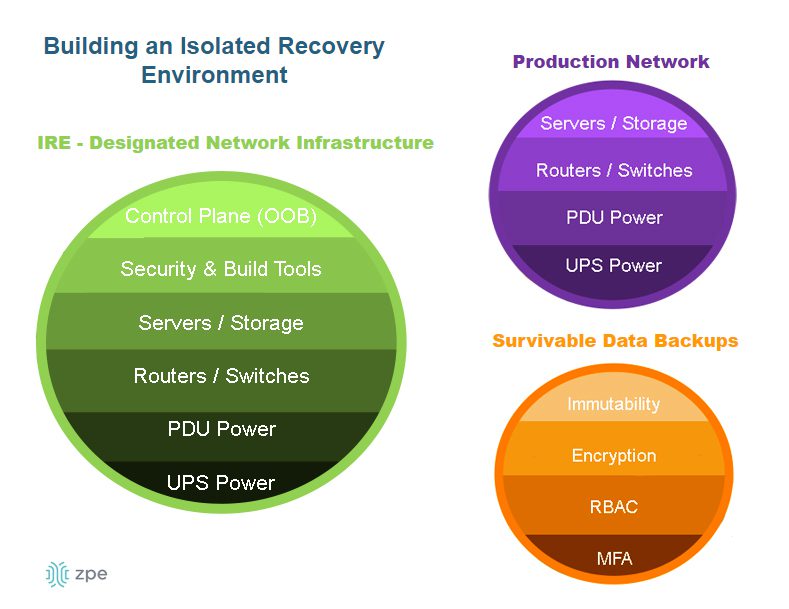
Isolation is integral to building a resilience system, or in other words, a system that gives you more than basic serial console/out-of-band access and instead provides an entire infrastructure dedicated to keeping you in control of your systems — be it during a ransomware attack, ISP outage, natural disaster, etc. Because this infrastructure is physically and virtually isolated from production (no dependencies on production switches/routers, no open management ports, etc.), it’s nearly impossible for attackers to lock you out.
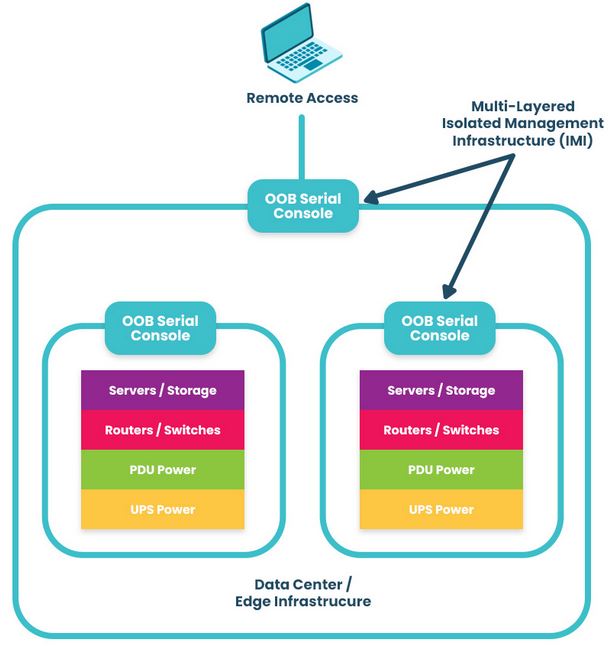
So, what really should you do if you’re ransomware’d? Let’s walk through an example attack on a healthcare system, and compare the traditional DR (Disaster Recovery) response to the IMI/IRE approach.
Ransomware in Healthcare: Disaster Recovery vs Isolated Recovery
Suppose you’re in charge of a hospital’s network. MDIoT, patient databases, and DICOM storage are the crown jewels of your infrastructure. Suddenly, you discover ransomware has encrypted patient records and is likely spreading quickly to other crown jewel assets. The risks and potential fallout can’t be understated. Millions of people are depending on you to protect their sensitive info, while the hospital is depending on you to help them avoid regulatory/legal penalties and ensure they can continue operating.
The problem with Disaster Recovery
Though the word ‘recovery’ is in the name, the DR approach is limited in its capacity to recover systems during an attack. Disaster Recovery typically employs a couple things:
- Backups, which are copies of data, configurations, and code that are used to restore a production system when it fails.
- Redundancy, which involves duplicating critical systems, services, and applications as a failsafe in the event that primaries go down (think cellular failover devices, secondary firewalls, etc.).
What happens when you activate your DR processes? It’s highly likely that you won’t be able to, and that’s because the typical DR setup relies on the production network. There’s no isolation.
Think about it this way: your backup servers need direct access to the data they’re backing up. If your file servers get pwned, your backup servers will, too. If your primary firewall gets hacked, your secondary will, too. The problem with backup and redundancy systems — and any system, for that matter — is that when they depend on the underlying infrastructure to remain operational, they’re just as susceptible to outages and attacks. It’s like having a reserve parachute that depends on the main parachute.
And what about the rest of your systems? You just discovered the attack has encrypted your servers and is quickly bringing operations to a crawl. How are you going to get in and fight back? What if you try to log into your management network, only to find that you’re locked out? All of your tools, configurations, and capabilities have been compromised.
This is why CISA, the FBI, US Navy, and other agencies recommend implementing Isolated Management Infrastructure.
IMI and IRE guarantee you can fight back against ransomware
You discover that the ransomware has spread. Not only has it encrypted data and stopped operations, but it has also locked you out of your own management network and is affecting the software configurations throughout the hospital. This is where IMI (Isolated Management Infrastructure) and IRE (Isolated Recovery Environment) come in.
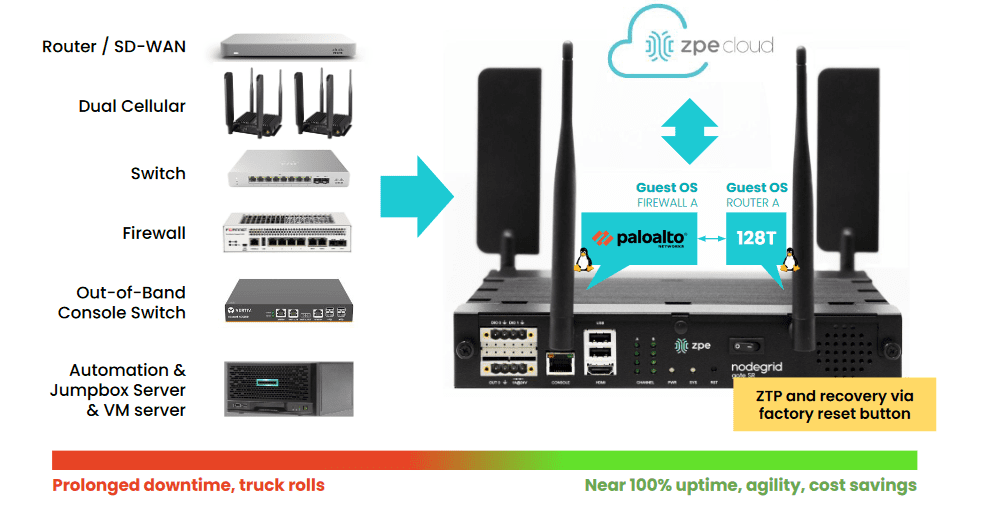
Because IMI is physically separate from affected systems, it guarantees management access so teams can set up communication and a temporary ‘war room’ for incident response. The IRE can then be created using a combination of cellular, compute, connectivity, and power control (see diagram for design and steps). Docker containers should be used to bring up each step.
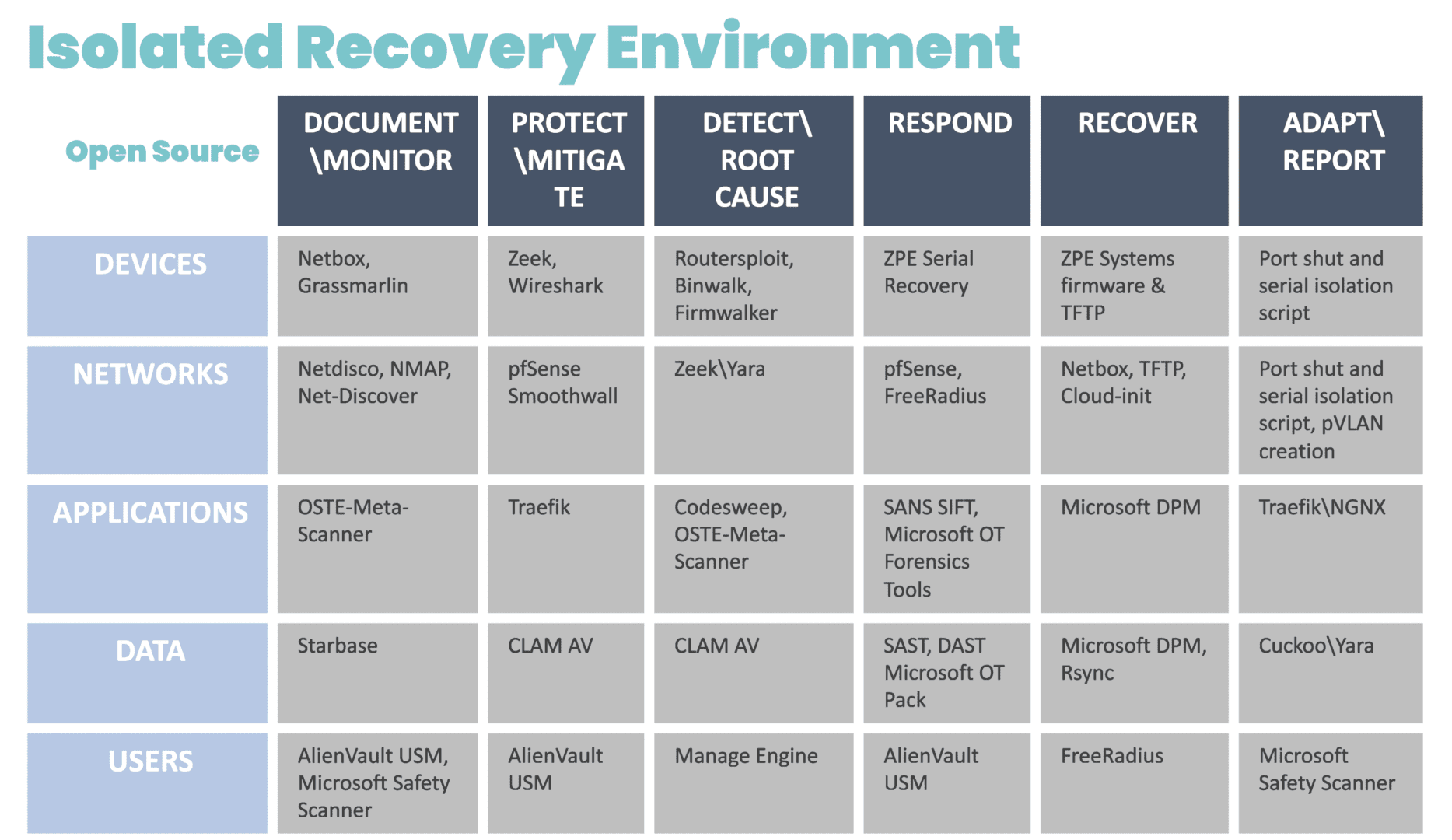
Image: The infrastructure and incident response protocol involved in the Isolated Recovery Environment. These products were chosen from free or open source projects that have proven to be very useful in each of these stages of recovery. These can be automated in pieces for each phase, and then be brought down via Docker container to eliminate the risk of leakage or risk during each phase.
Without diving too far into the technicalities, the IRE enables you to recover survivable data, restore software configurations, and prevent reinfection. Here are some things you can do (and should do) in this scenario, courtesy of the IRE:
Establish your war room
You can’t fight ransomware if you can’t securely communicate with your team. Use the IRE to create offline, break-the-glass accounts that are not attached to email. This allows you to communicate and set up ticketing for forensics purposes.
Isolate affected systems
There’s no use running antivirus if reinfection can occur. Use the IRE to take offline the switch that connects the backup and file servers. Isolate these servers from each other and shut down direct backup ports. Then, you can remote-in (KVM, iKVM, iDRAC) to run antivirus and EDR (Endpoint Detection and Response).
Restore data and device images
The key is to have backup data at its most current, both for patient data and device/software configurations. Because the IRE provides an isolated environment, and you’ve already pulled your backups offline, you can gradually restore data, re-image devices, and restore configurations without risking reinfection. The IRE ensures devices “keep away” from each other until they can be cleansed and recovered.
Things You’ll Need To Build The IMI and IRE
Network Automation Blueprint
We’ve created a comprehensive blueprint that shows how to implement the architecture for IMI and IRE. Don’t let the name fool you. The Network Automation Blueprint covers everything from establishing a dedicated management network, to automating deployment of services for ransomware recovery. Get your PDF copy now at the link below.
Gen 3 Console Servers To Replace End-of-Life Gear
It’s nearly impossible to build the IMI or deploy the IRE using older console servers. That’s because these only give you basic remote access and a hint of automation capabilities. You’ll still need the ability to run VMs and containers. Gen 3 console servers let you do all of the things for IMI and IRE, like full control plane/data plane separation, hosting apps, and deploying VMs/containers on-demand. They’ve also been validated by Synopsys and have built-in security features I’ve been talking about for years. Check out the link below for resources about Gen 3 and how we’ll help you upgrade.
Get in touch with me!
I’d love to talk with you about IMI, IRE, and resilience systems. These are becoming more crucial to operational resilience and ransomware recovery, and countries are passing new regulations that will require these approaches. Get in touch with me via social media to talk about this!





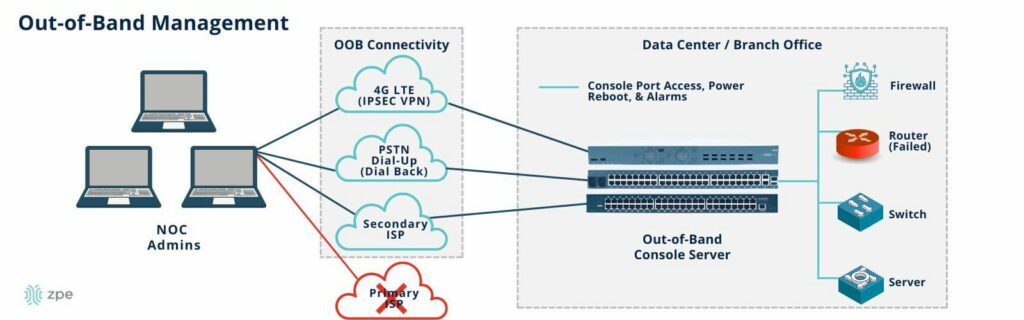



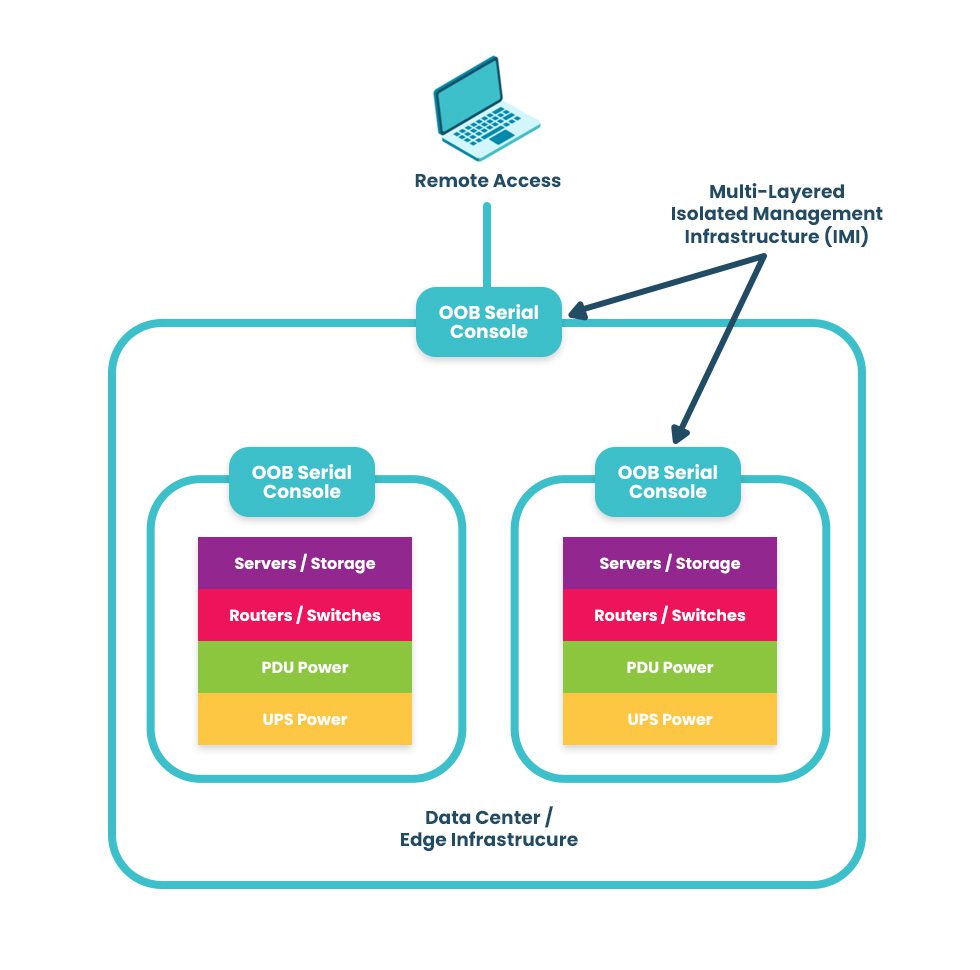 An IMI using out-of-band serial consoles also provides a safe environment to recover from ransomware attacks. The pervasive nature of ransomware and its tendency to re-infect cleaned systems mean it can take companies between
An IMI using out-of-band serial consoles also provides a safe environment to recover from ransomware attacks. The pervasive nature of ransomware and its tendency to re-infect cleaned systems mean it can take companies between