AI Data Center Infrastructure

AI data center infrastructure components
Computing
Generative AI and other artificial intelligence technologies require significant processing power. AI workloads typically run on graphics processing units (GPUs), which are made up of many smaller cores that perform simple, repetitive computing tasks in parallel. GPUs can be clustered together to process data for AI much faster than CPUs.
Storage
AI requires vast amounts of data for training and inference. On-premises AI data centers typically use object storage systems with solid-state disks (SSDs) composed of multiple sections of flash memory (a.k.a., flash storage). Storage solutions for AI workloads must be modular so additional capacity can be added as data needs grow, through either physical or logical (networking) connections between devices.
Networking
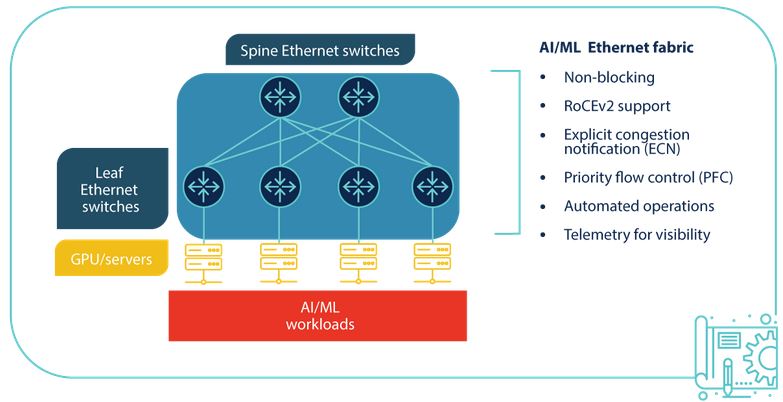
AI workloads are often distributed across multiple computing and storage nodes within the same data center. To prevent packet loss or delays from affecting the accuracy or performance of AI models, nodes must be connected with high-speed, low-latency networking. Additionally, high-throughput WAN connections are needed to accommodate all the data flowing in from end-users, business sites, cloud apps, IoT devices, and other sources across the enterprise.
Power
AI infrastructure uses significantly more power than traditional data center infrastructure, with a rack of three or four AI servers consuming as much energy as 30 to 40 standard servers. To prevent issues, these power demands must be accounted for in the layout design for new AI data center deployments and, if necessary, discussed with the colocation provider to ensure enough power is available.
Management
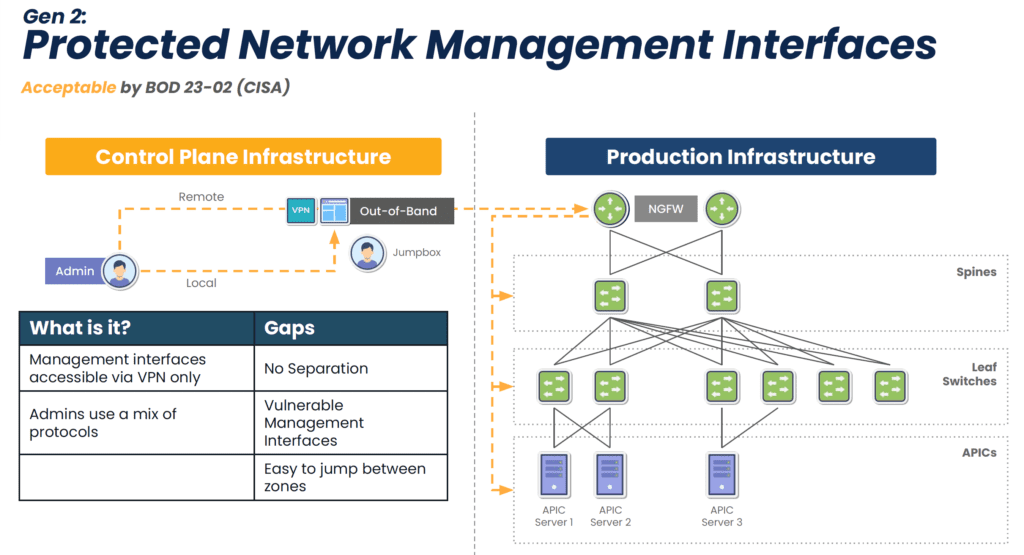
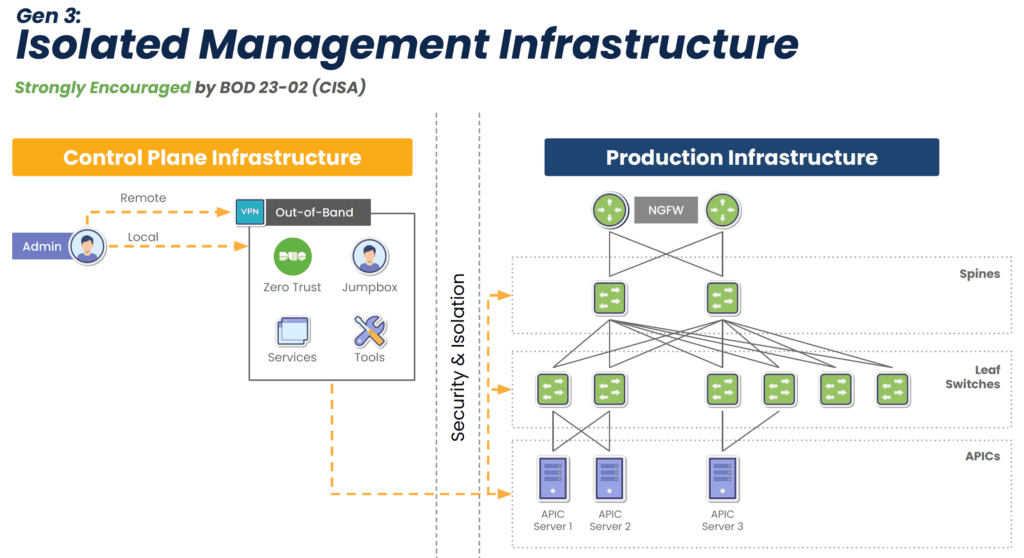
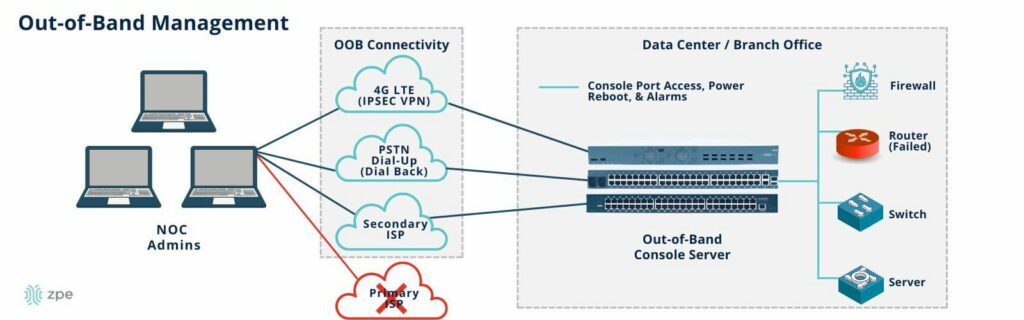
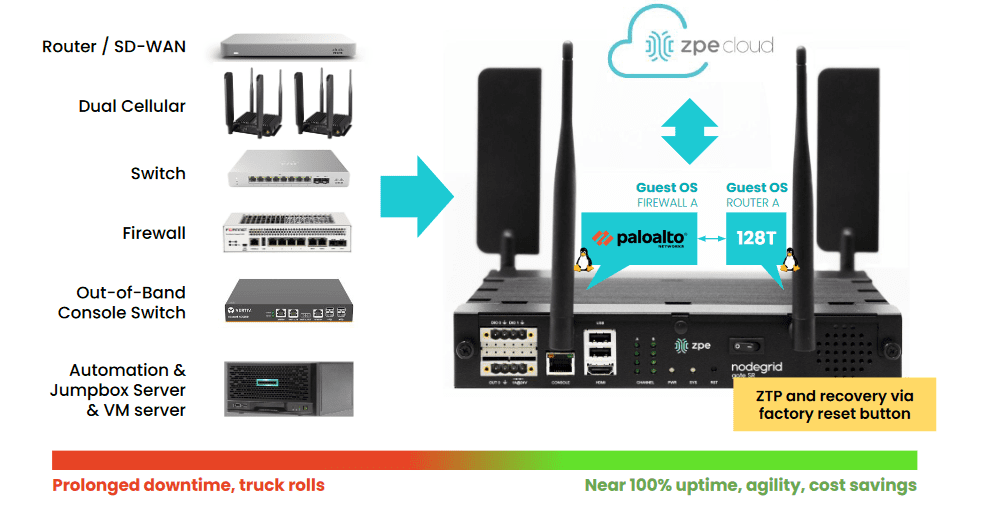
Data center infrastructure, especially at the scale required for AI, is typically managed with a jump box, terminal server, or serial console that allows admins to control multiple devices at once. The best practice is to use an out-of-band (OOB) management device that separates the control plane from the data plane using alternative network interfaces. An OOB console server provides several important functions:
- It provides an alternative path to data center infrastructure that isn’t reliant on the production ISP, WAN, or LAN, ensuring remote administrators have continuous access to troubleshoot and recover systems faster, without an on-site visit.
- It isolates management interfaces from the production network, preventing malware or compromised accounts from jumping over from an infected system and hijacking critical data center infrastructure.
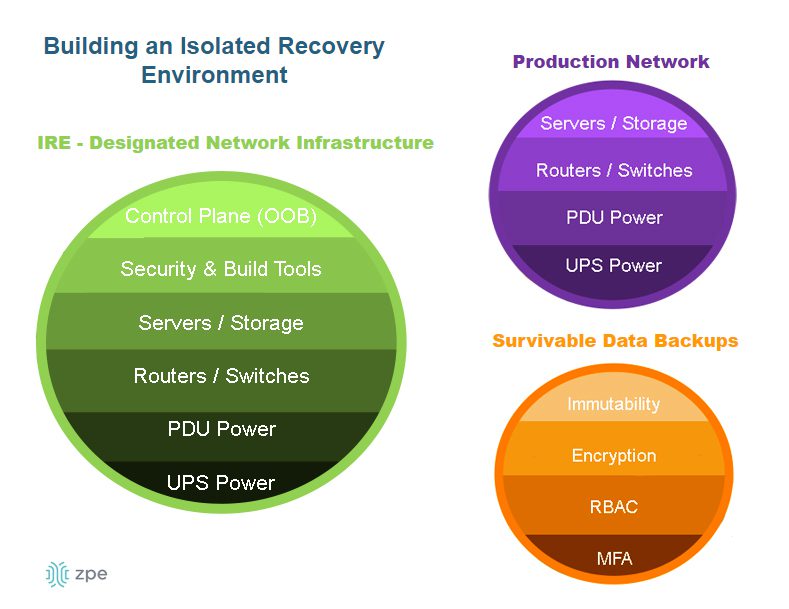
- It helps create an isolated recovery environment where teams can clean and rebuild systems during a ransomware attack or other breach without risking reinfection.
An OOB serial console helps minimize disruptions to AI infrastructure. For example, teams can use OOB to remotely control PDU outlets to power cycle a hung server. Or, if a networking device failure brings down the LAN, teams can use a 5G cellular OOB connection to troubleshoot and fix the problem. Out-of-band management reduces the need for costly, time-consuming site visits, which significantly improves the resilience of AI infrastructure.
AI data center challenges
Artificial intelligence workloads, and the data center infrastructure needed to support them, are highly complex. Many IT teams struggle to efficiently provision, maintain, and repair AI data center infrastructure at the scale and speed required, especially when workflows are fragmented across legacy and multi-vendor solutions that may not integrate. The best way to ensure data center teams can keep up with the demands of artificial intelligence is with a unified AI orchestration platform. Such a platform should include:
- Automation for repetitive provisioning and troubleshooting tasks
- Unification of all AI-related workflows with a single, vendor-neutral platform
- Resilience with cellular failover and Gen 3 out-of-band management.
To learn more, read AI Orchestration: Solving Challenges to Improve AI Value
Improving operational efficiency with a vendor-neutral platform
Nodegrid is a Gen 3 out-of-band management solution that provides the perfect unification platform for AI data center orchestration. The vendor-neutral Nodegrid platform can integrate with or directly run third-party software, unifying all your networking, management, automation, security, and recovery workflows. A single, 1RU Nodegrid Serial Console Plus (NSCP) can manage up to 96 data center devices, and even extend automation to legacy and mixed-vendor solutions that wouldn’t otherwise support it. Nodegrid Serial Consoles enable the fast and cost-efficient infrastructure scaling required to support GenAI and other artificial intelligence technologies.
Make Nodegrid your AI data center orchestration platform
Request a demo to learn how Nodegrid can improve the efficiency and resilience of your AI data center infrastructure.
Contact Us