Network Management Best Practices

Network management involves administering, controlling, and monitoring an organization’s network. For most companies, the top priority for network teams is ensuring the continuous availability of critical business services, even during disruptive events like natural disasters, ransomware attacks, and infrastructure failures. Network resilience is the ability to continue operating (if in a degraded state) and delivering digital services in the face of adversity. This guide discusses the network management best practices for improving and supporting network resilience.
Network management best practices
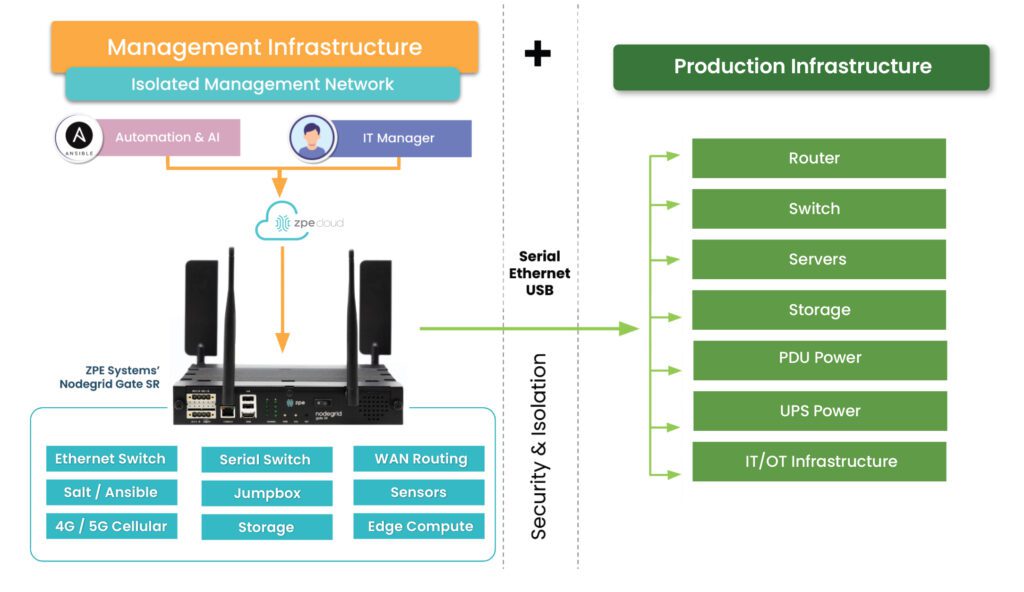
Isolated Management Infrastructure (IMI)
Major ransomware attacks and breaches happen so frequently that cybersecurity professionals must now operate as if the network has already been compromised. This high-threat atmosphere led to the rise of the Zero Trust Security methodology discussed below. It’s also why a recent CISA Binding Directive outlines the best practice of isolating your management interfaces to a designated management network.
Moving all control functions for network infrastructure off the production LAN reduces the risk of cybercriminals accessing your management interfaces and “crown jewel” assets. This practice is known as isolated management infrastructure (IMI), and it separates the management plane from the data plane using designated network infrastructure. Doing so prevents attackers on the production network from finding and accessing the interfaces used to control servers, firewalls, routers, and other critical infrastructure devices. Thanks to management network segmentation and zero-trust security controls, hacking an IMI is almost impossible.
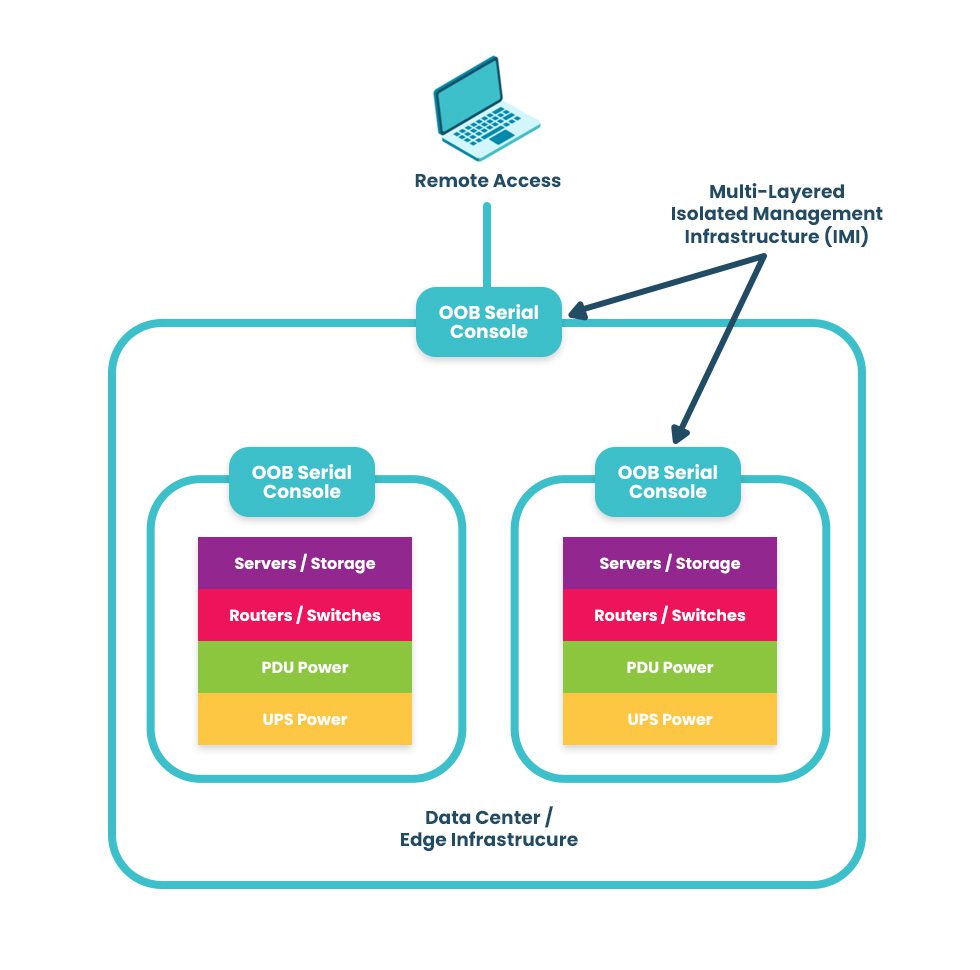
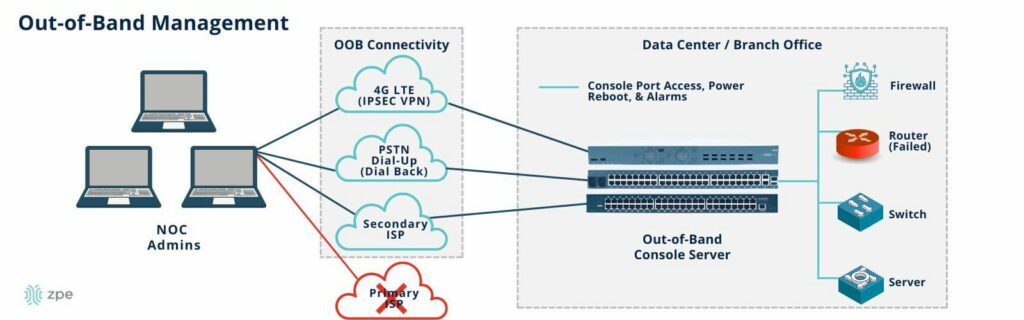
The best practice is to use out-of-band (OOB) serial consoles (a.k.a. console servers or terminal servers) to help construct the IMI. An OOB management solution uses dedicated network interfaces (such as 4G/5G cellular LTE or fiber) to provide an Internet connection for remote management access that doesn’t rely upon the primary production network at all. The benefit of using an OOB console server for the IMI is that teams have continuous access to monitor, manage, troubleshoot, and recover remote infrastructure when the production network is unavailable. Additionally, routing management ports to terminate on OOB terminal servers deployed top-of-rack creates multiple layers of management isolation to protect critical assets from criminals on the network.
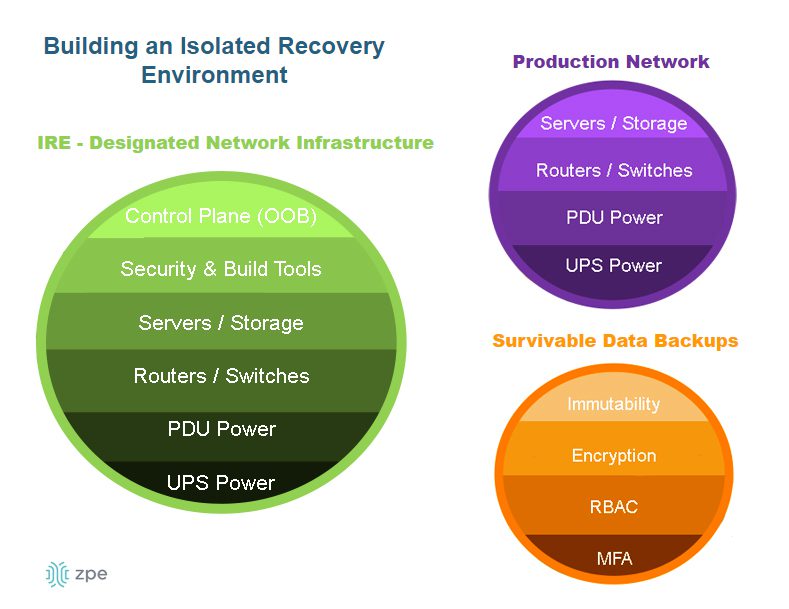
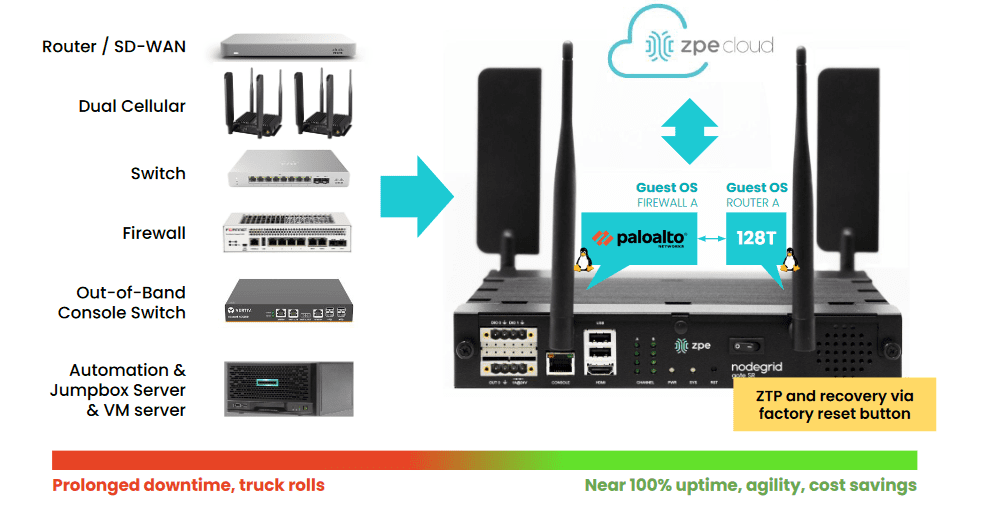
Another network management best practice aided by IMI and OOB serial consoles is an isolated recovery environment (IRE). An IRE is built with designated infrastructure that is easily and quickly deployable, including an OOB control plane (such as a serial console), redundant storage & compute, and security and recovery tools. This gives teams a safe environment to recover from ransomware attacks without worrying about reinfection. Ideally, the IMI will use devices that consolidate network functions to enable easy deployments and scaling of IRE and OOB, but those devices should have robust features that can host the apps, tools, and services required to rebuild systems and restore data.
Network automation
Modern networks are large, complex, and ever-expanding, with user expectations growing more demanding every day. Even the best network administrator sometimes makes mistakes, either through negligence or because they have an overwhelming amount of work to do. Maybe they copy and paste the wrong security setting for a particular firewall appliance in a rush to deploy a new site on time; perhaps they miss a critical device health alert because they’re responding to a separate incident. These human errors, while understandable, can have devastating consequences on network resilience by causing security breaches, equipment failure, and service outages.
Network automation removes human error from the equation, ensuring network management tasks are carried out perfectly every time. Automation streamlines the most tedious network and fleet management tasks so teams can improve efficiency without allowing anything to fall through the cracks. Automation tools also respond to changing network conditions faster than human administrators to optimize the performance and availability of critical systems and services.
Network security
As discussed above, network breaches occur so frequently that it’s now a security best practice to assume attackers are already on the network. This is part of the zero trust security methodology, which follows the principle of “never trust, always verify” regarding all the users, devices, and applications that access the network. Zero trust security uses strong authentication methods (e.g., 2FA or one-time passwords), hardware roots of trust, and network micro-segmentation. These methods prevent attackers from moving around the network and accessing valuable resources (such as management interfaces).
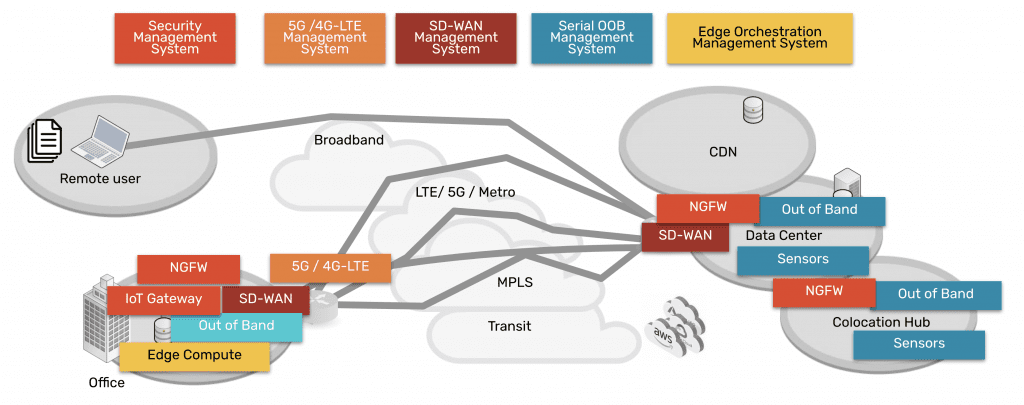
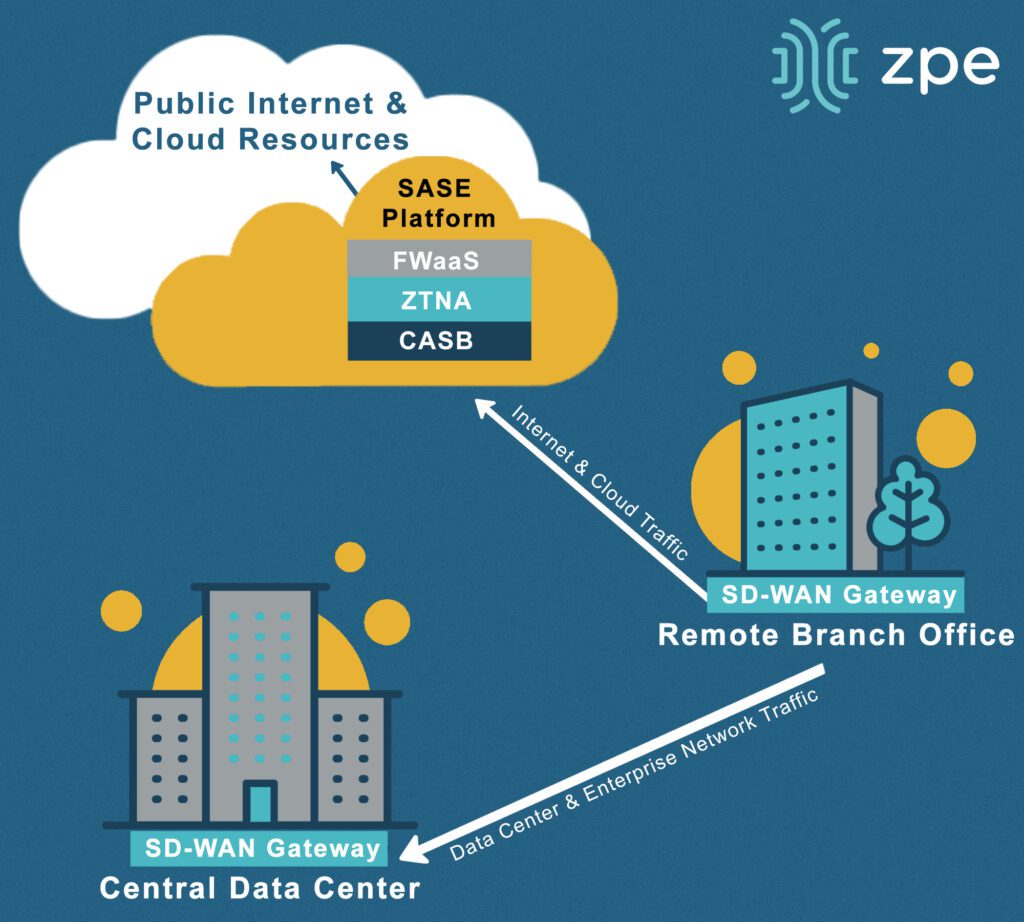
Another security-related network management best practice is to extend zero-trust controls and policies to the network’s edges, such as to work-from-home devices, branch offices, and other remote business sites. This is achieved using edge-centric security solutions such as Security Service Edge (SSE) and Secure Access Service Edge (SASE). These technologies route remote, web-destined network traffic through a whole stack of cloud-based security solutions. This allows organizations to apply consistent security to edge traffic without creating bottlenecks at a centralized firewall or deploying additional security appliances at each site.
Another emerging network management best practice, especially for complex, automated infrastructures, is using artificial intelligence (AI) and machine learning to aid security and recovery. For example, AIOps solutions analyze data pulled from various sources on the network, including monitoring platforms, security appliances, and system event logs. AIOps is excellent at detecting anomalies, extrapolating potential consequences, and positing solutions. It can find novel and zero-day threats on the network, spot the signs of an imminent device failure, and perform root-cause analysis (RCA) to discover the source of problems. AIOps enhances the management, automation, and security practices on this list to improve the overall efficiency and resilience of enterprise networks.
Network management FAQs
1. How do I ensure interoperability amongst network management solutions?
Managing a modern network requires many different solutions, often from many different vendors. All these solutions must work together to prevent the management plane from getting too complex and ensure there are no coverage gaps. One option is to stick within one vendor’s ecosystem, but you may miss out on beneficial features or pay for functionality you don’t need. The best approach is to use a vendor-neutral (a.k.a. vendor-agnostic) network management platform to unify all your tools. To learn more, read The Benefits of Vendor Agnostic Platforms in Network Management.
2. What’s the difference between network automation and orchestration?
Network automation and network orchestration are two concepts that are often referenced together, leading to some confusion about the difference between them. Network automation focuses on individual tasks and processes, such as deploying a single software update. Network orchestration involves coordinating and managing multiple tasks and processes, or even entire workflows, such as configuring and deploying all the software on a server. To learn more, read IT Automation vs Orchestration: What’s the Difference?
3. Is network resilience the same as redundancy and backups?
Redundancy and backups are both critical to business continuity, but they do not equate to network resilience. Backups are copies of data, configurations, and code that are used to restore failed (or compromised) production systems. Redundancy duplicates services, applications, and systems so the primary versions can be “failed over” in case of failure or attack. Resilience is an organization’s overall ability to recover or adapt when major disruptions occur. To learn more, read Network Resilience: What is a Resilience System?
Resilient network management with Nodegrid
These network management best practices represent the industry-leading solutions for addressing the most common resilience challenges facing organizations. The network resilience experts at ZPE Systems can help you implement these practices with Gen 3 out-of-band management solutions and a vendor-neutral network management platform that supports automation. ZPE’s Nodegrid platform is the perfect ransomware recovery multi-tool, providing an isolated control plane as well as access to all the tools and software needed to restore critical operations.
Network management best practices for ransomware recovery and resilience
Learn more about using Nodegrid to improve ransomware resilience by downloading our white paper, 3 Steps to Ransomware Recovery.
ZPE Systems offers various solutions to help you implement your enterprise network management strategy.
Including data center infrastructure management, critical remote infrastructure management, and a secure uCPE gateway for distributed branch & edge networks. To learn more, contact us online.