Zero Trust Security Benefits

Network security has become more challenging for companies whose employees, devices, and applications no longer reside within one easily defended perimeter. Additionally, cyber attacks like ransomware constantly threaten networks, forcing organizations to operate under the assumption that systems are already breached.
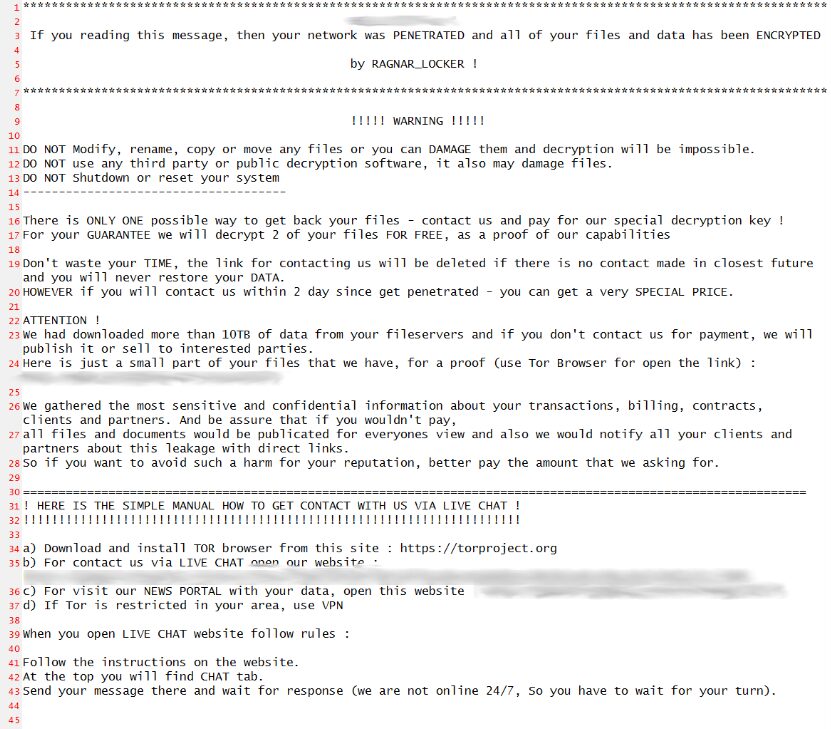
Zero trust security is a methodology that helps companies limit the blast radius of an attack to prevent the exfiltration of sensitive and valuable data. Zero trust assumes that every user, device, and application is unsafe until proven otherwise, following the principle of “never trust, always verify.” This guide discusses how zero trust security benefits organizations by increasing network visibility, reducing the scope of cyber attacks, and providing precise security coverage.
Zero trust security benefits
1. Improves network control
Implementing zero trust security requires knowing exactly what devices, users, applications, and services access the network, where they reside, and their potential vulnerabilities. Additionally, you must monitor all traffic on the network to identify unusual activity that could indicate compromise, and react to potential breaches. Zero trust teams deploy tools such as SIEM (security information and event management) and inventory discovery and assessment solutions to achieve this level of granular visibility.
While these tools are necessary to implement zero trust, the visibility they provide has side benefits that improve network management control and efficiency. Having insight into the health status of every network resource enables preventative maintenance and speedy responses to issues that could affect performance or availability if left unchecked. Many zero-trust solutions also use automation tools, such as automatic device/app discovery or AI threat detection, to cut back on the time your administrators spend on tedious, day-to-day management and monitoring tasks.
2. Reduces attack radius
Many traditional cybersecurity methodologies focus almost entirely on prevention, but once an attacker breaches the network, teams lack the tools to find or stop them. Zero trust security assumes a breach is already occurring. It provides the tools and techniques needed to stop it, reducing the attack radius and limiting the damage caused to your organization.
Zero trust uses network micro-segmentation and precise security policies to create perimeters around individual resources, requiring users to continuously prove their identity and “trustworthiness” as they move around the network. Each checkpoint provides another opportunity for multi-factor authentication (MFA) or security monitoring tools to catch and lock out the account.
Zero trust security reduces the duration of attacks, which limits data exfiltration, downtime, and other business impacts.
3. Provides precise security coverage
Traditional security models create one large perimeter of controls and policies that must address every potential vulnerability on the network. This approach leads to a bloated patchwork of appliances and solutions that may not cover all bases, leaving gaps in your security that could expose critical vulnerabilities.
Conversely, zero trust security creates micro-perimeters around individual resources, allowing you to implement the exact policies and controls required to protect each component. Tools like next-generation firewalls (NGFWs) enable teams to micro-segment the network, create micro-perimeters, and enforce access controls. Zero trust identity and access management (IAM) solutions also provide a centralized place to create, deploy, manage, and monitor highly specific security policies to protect individual resources.
Zero trust security shrinks your perimeter to smaller network segments, allowing teams to apply the best security policies and controls to protect each micro-perimeter. As a result, you don’t have to worry about any weak points or gaps in your network security.
How to take advantage of zero trust security benefits
Zero trust security benefits organizations by increasing their overall network visibility, reducing the scope and impact of attacks, and enabling more precise security controls and access policies.
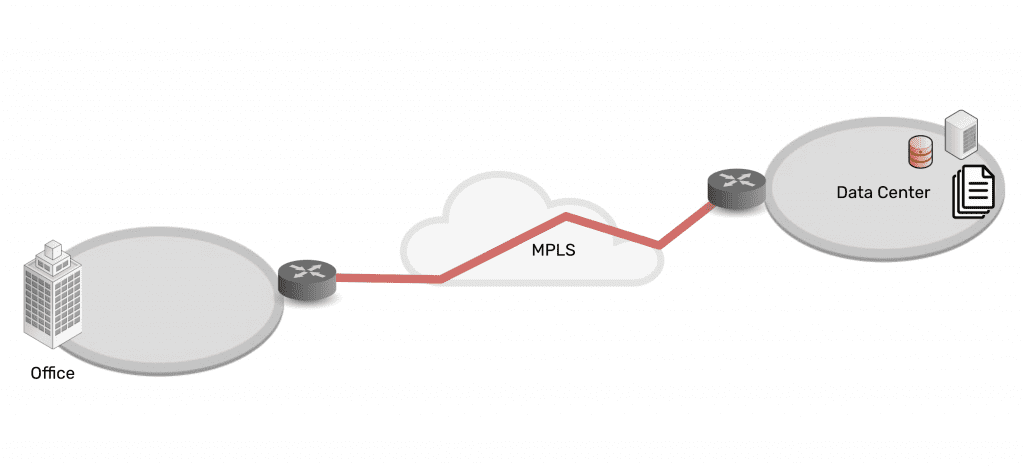
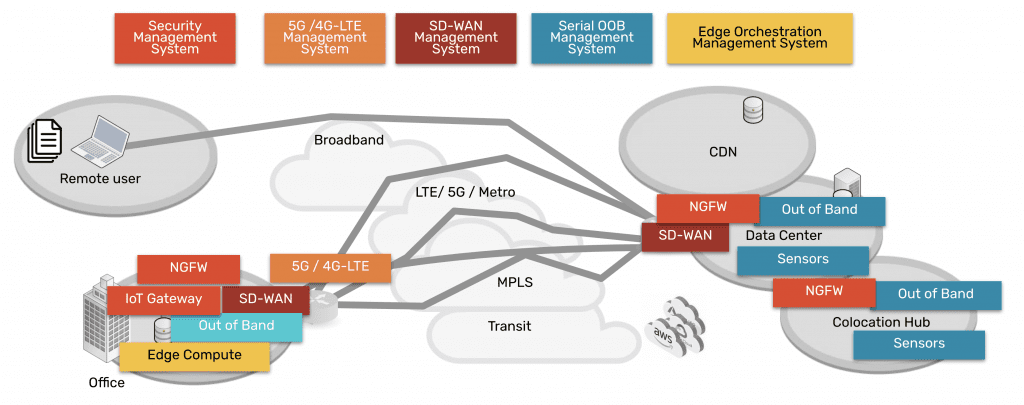
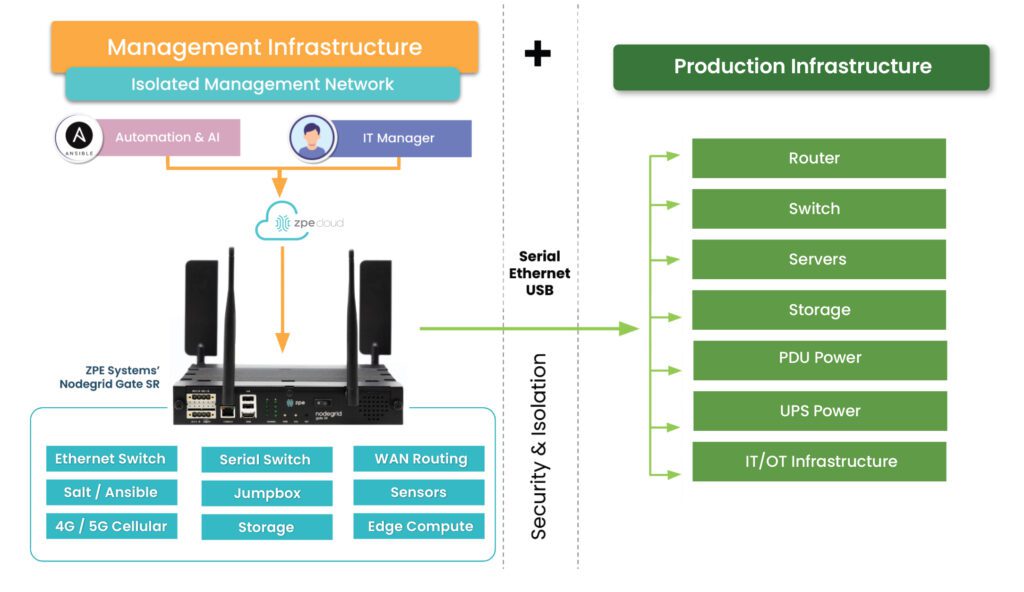
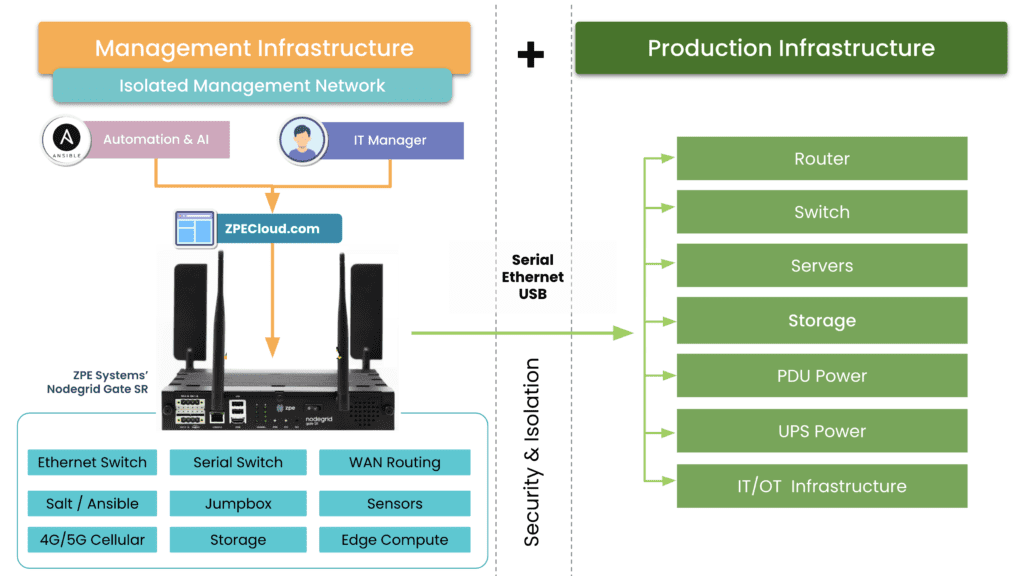
One important thing to consider is that you must apply zero trust to both production network resources and management interfaces on the control plane. The best practice is to move management interfaces to an isolated, out-of-band (OOB) network using Nodegrid OOB devices to help create an isolated management infrastructure (IMI) that’s micro-segmented with zero trust policies and controls. A zero-trust IMI prevents attackers from jumping from production resources to the control plane for “crown jewels” infrastructure, significantly improving your security posture.

Additionally, achieving zero trust is easier with an open, flexible, vendor-neutral platform that integrates all your tools, features, and controls into one simplified interface. For example, the Nodegrid platform from ZPE Systems serves as a single security gateway with seamless integrations with third-party services like Okta and Palo Alto Panorama. Nodegrid allows you to take advantage of zero trust security benefits with a customized solution that supports your organization’s unique goals and requirements.
Want to learn more about how to simplify zero trust security with Nodegrid?
ZPE Systems can help your company realize these zero trust security benefits with our secure out-of-band management solutions and vendor-neutral platform. Schedule a free Nodegrid demo to learn more.