Critical Entities Resilience Directive

Who does the Critical Entities Resilience Directive apply to, and why does it matter?
The CER Directive covers eleven sectors and subsectors that provide services essential to society, the economy, public health & safety, or preserving the environment. These include:
In-Scope Sectors Covered by the CER Directive |
|
| Sector | Subsectors |
| Energy |
|
| Transport |
|
| Banking |
|
| Financial Market Infrastructure |
|
| Health |
|
| Drinking Water |
|
| Waste Water |
|
| Digital Infrastructure |
|
| Public Administration | |
| Space |
|
| Food Production, Processing, and Distribution |
|
The Critical Entities Resilience Directive is one of several new EU regulations (such as DORA and NIS2) created to establish consistent guidelines for resilience in sectors where any service disruption has a significant negative impact on society or the economy. Whereas DORA applies primarily to financial institutions and supporting services, and NIS2 focuses on cybersecurity threats, the CER Directive is broader in scope and addresses other, non-digital threats to resilience such as natural disasters and global health crises (e.g., COVID-19).
The penalties for noncompliance will vary by Member State but are likely to include fines, public notification, remediation, and withdrawal of authorization.
CER Directive requirements for critical entities
Most of the CER Directive requirements apply to Member States, outlining how the designated authorities will adopt and enforce resilience measures and support critical entities in achieving compliance. However, there are five key provisions that relevant organizations should be aware of as they prepare for their identification as critical entities.
1. Article 4: Strategy on the resilience of critical entities
EU Member States have until 17 January 2026 to adopt a strategy outlining the guidelines and procedures for critical entities to achieve and maintain a high level of resilience. Essentially, this strategy will describe the requirements for CER Directive compliance in each Member State and provide guidance on how to meet those requirements. Potentially critical entities can prepare by examining existing resilience frameworks and regulations to anticipate the policies, tools, and procedures that will likely be required.
2. Article 5: Risk assessment by Member States
Member States have until 17 January 2026 to perform a risk assessment of all essential services. These assessments must account for natural and human-made risks, including accidents, natural disasters, public health emergencies, terrorist attacks, and antagonistic threats. Member States will then use the risk assessments to identify critical entities within each sector.
3. Article 12: Risk assessment by critical entities
Critical entities must perform risk assessments using similar criteria to Article 5 within nine months of being notified of their designation as critical and at least every four years afterward. If an organization already conducts risk assessments according to other similar resilience guidelines or frameworks, Member States have the authority to decide whether or not those assessments meet CER Directive compliance requirements.
4. Article 13: Resilience measures of critical entities
Critical entities must take the appropriate technical, security, and policy measures to ensure resilience, including a comprehensive strategy for service continuity and disaster recovery. Examples of resilience measures outlined by the CER Directive include:
CER Directive Resilience Measures |
|
| Requirements | Examples |
| Adopt disaster risk reduction and climate adaptation measures | Using an environmental monitoring system to detect and respond to rising temperatures, humidity, and other relevant conditions |
| Ensure adequate physical protection of the premises and critical infrastructure, including fencing, barriers, perimeter monitoring tools, detection equipment, and access controls | Installing proximity sensors in data center racks to automatically notify security teams if an unauthorized user physically tampers with remote infrastructure |
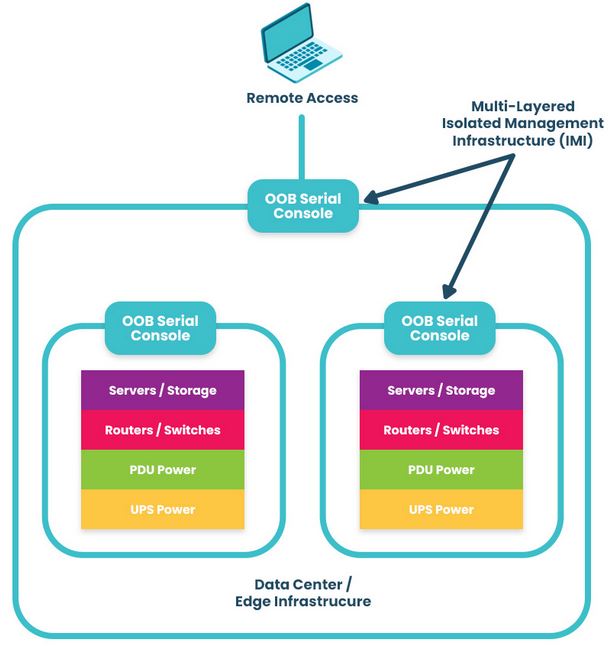
| Respond to, resist, and mitigate service disruptions | Deploying out-of-band (OOB) serial consoles with cellular capabilities to ensure continuous remote management access to critical infrastructure |
| Recover from incidents using business continuity measures to resume provisioning essential services | Building a resilience system containing all the infrastructure and tools needed to rebuild and recover while still delivering core services |
| Manage employee security by classifying personnel who exercise critical functions, establishing access rights and controls, and performing background checks as needed | Adopting zero-trust security policies and controls that assign access privileges according to role (role-based access control, or RBAC) |
5. Article 15: Incident notification
Critical entities must notify the competent authority of any incidents that have or could significantly disrupt essential services within 24 hours of detection. The significance of a disruption is determined according to the following parameters:
- How many users the disruption affects;
- How long the disruption lasts;
- The geographical area the disruption affects.
The incident notification must explain the nature, cause, and potential consequences of the disruption, including any cross-border implications.
How Nodegrid simplifies CER Directive compliance
Nodegrid is a Gen 3 out-of-band management platform that makes the perfect foundation for a resilience system. Nodegrid OOB separates the control plane from the data plane to ensure continuous remote management access to critical infrastructure even during production network outages. Vendor-neutral serial consoles and integrated branch service routers directly host third-party software for security, automation, recovery, and more, reducing hardware overhead at each site while ensuring teams have access to all the tools they need to restore essential services.
Looking to Upgrade to a Nodegrid serial console?
Prepare for the Critical Entities Resilience Directive by replacing your discontinued, EOL serial console with a Gen 3 out-of-band solution from Nodegrid.