Zero Trust Edge Solutions: Continuing the Zero Trust Journey

The zero trust security methodology follows the principle of “never trust, always verify,” which assumes that any account or device could be compromised and should be forced to continuously establish trustworthiness. This sounds like an extreme approach, but with the frequency of high-profile data breaches and ransomware attacks steadily increasing, security teams must pivot their approach away from prevention and toward damage mitigation and recovery. Zero trust security limits the lateral movement of compromised accounts on the network by establishing micro-perimeters around network resources that continually assess an account’s behavior for suspicious activity.
Organizations also must extend zero trust security policies and controls to remote business sites at their network’s edges, such as branches, Internet of Things (IoT) deployments, and home offices. Zero trust edge solutions are software platforms that provide networking, access, and security capabilities designed specifically for the edge. This guide explains what zero trust edge solutions do and the challenges involved in using them before discussing how to build a unified ZTE platform.
What are zero trust edge solutions?
A zero trust edge solution combines edge-centric security functionality with remote access and networking capabilities. ZTE’s core feature is zero trust network access (ZTNA), which securely connects remote users to enterprise applications and resources, similar to a VPN. ZTNA is more secure than VPNs because it only allows users to authenticate to one resource at a time and prevents them from seeing or accessing anything else until they re-establish their identity and credentials. ZTE’s other features and capabilities vary depending on the vendor and deployment type. ZTE solutions come in three different forms:
- As a service: Companies can purchase ZTE functionality as a cloud-based, vendor-managed service. Remote users connect to regional points of presence (POPs) to reach the ZTE stack in the cloud before being routed to enterprise resources. This deployment style is easier to deploy for organizations with lots of users in the field but few (if any) physical edge locations to host security or networking solutions.
. - With SD-WAN: Some ZTE providers combine zero-trust features with software-defined wide area networking (SD-WAN) capabilities. SD-WAN creates a virtual network overlay that’s decoupled from the underlying WAN infrastructure, enabling centralized control and automation. Packaging ZTE and SD-WAN together helps organizations consolidate their tech stack at physical edge sites like branches, warehouses, and manufacturing plants while still offering ZTNA to work-from-home and field employees.
. - Build your own: Since there are very few mature ZTE providers on the market, and it can be difficult to find pre-made solutions with all the features needed for complex, distributed edge networks, many teams opt to build their own platform by combining tools from multiple vendors. Typically, these organizations have physical branches with existing WAN infrastructure that they use as regional POPs to host ZTNA and other security solutions.
Why build your own ZTE solution?
If pre-made solutions exist, why would companies go through the hassle of creating their own zero trust edge platform? Presently, there aren’t any “complete” ZTE solutions that offer full, zero-trust protection for branches and other physical edge sites.
For example, many ZTE platforms don’t protect management ports on the control plane, leaving critical edge infrastructure like servers, switches, and power distribution units (PDUs) exposed to cybercriminals. Additionally, branch ZTE solutions rely upon production network infrastructure, so if there’s an outage or ransomware attack, remote management teams are completely cut off from troubleshooting and recovery. These solutions also lack helpful edge networking features like fleet management and automation, and their closed ecosystems limit the ability to extend their capabilities.
Building your own zero trust edge platform allows you to combine all the security, networking, and management functionality you need to get full security coverage and streamline branch operations. The key to creating a robust and efficient ZTE solution is starting with a vendor-neutral platform that can unify the entire security architecture.
How Nodegrid simplifies ZTE
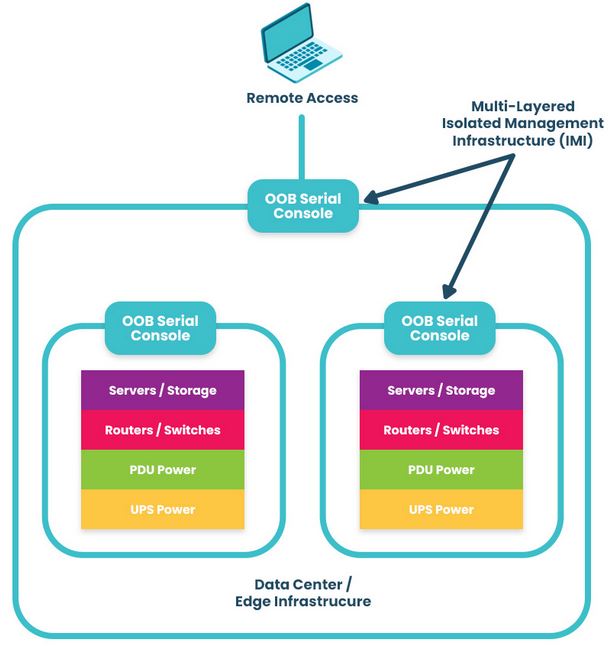
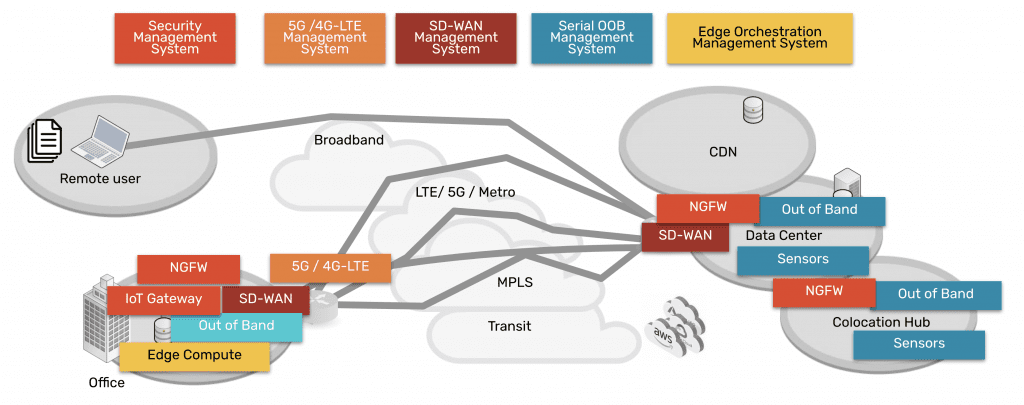
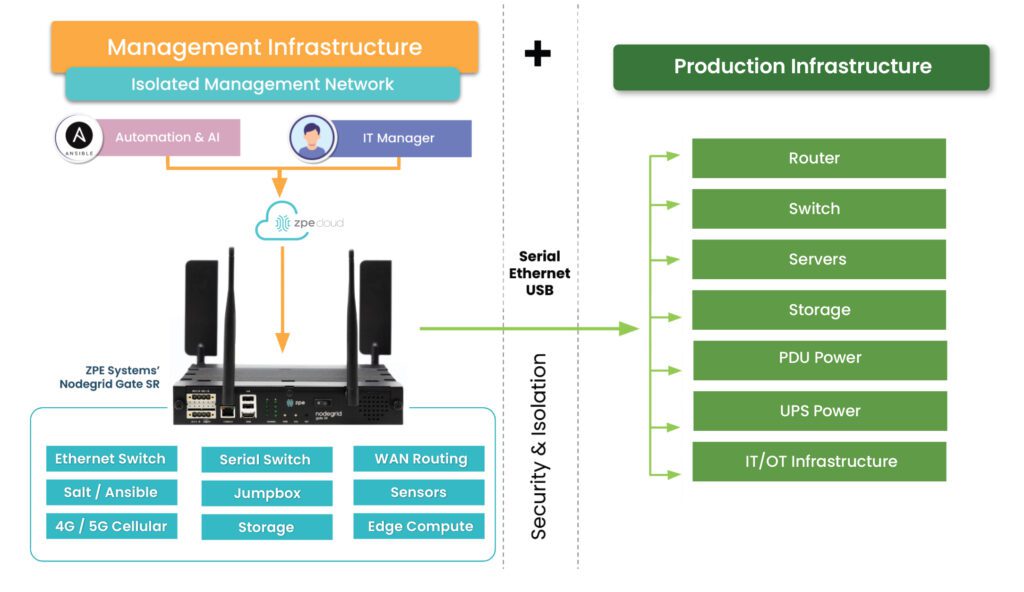
Nodegrid edge networking solutions from ZPE Systems provide the perfect vendor-neutral platform for integrated zero trust edge deployments. All-in-one edge gateway routers deliver a full stack of branch networking capabilities, including out-of-band (OOB) management. OOB creates a dedicated control plane on an isolated network so remote teams have continuous access to manage, troubleshoot, and repair edge infrastructure.
Nodegrid protects the management interfaces on the OOB network with robust, zero trust security processes and controls. For example, the encryption keys for each Nodegrid device are destroyed after provisioning so that only the public key is accessible when needed for authentication to our cloud. Nodegrid devices also use the Trusted Platform Module (TPM) as a hardware security module to prevent cybercriminals from tampering with the configuration or storage.
Our platform runs on the Linux-based, x86 Nodegrid OS, which supports VMs and Docker containers for third-party applications. That means you can deploy ZTNA, SD-WAN, and other zero trust edge solutions without purchasing or managing additional hardware at each branch. Nodegrid’s OOB and failover functionality ensure those security and access solutions remain operational during ISP outages, ransomware attacks, and other disruptions. Teams can also run their favorite tools for automation, troubleshooting, and recovery on the Nodegrid platform, streamlining edge operations and ensuring their toolbox is available on the OOB network. Nodegrid also simplifies fleet management with true zero-touch provisioning to securely and automatically deploy configurations at edge business sites.
Want to unify your zero trust edge solutions with Nodegrid?
Nodegrid provides a robust, vendor-neutral platform to unify and extend your zero trust edge capabilities. Request a free demo to see Nodegrid in action. Watch Demo